Lucene使用案例
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆(来自百度百科)
点击查看百度百科:https://baike.baidu.com/item/Lucene
CSDN一篇文章介绍:https://blog.csdn.net/regan_hoo/article/details/78802897
关于Lucene具体介绍不多说,这里写一个应用场景来学会使用Lucene:
我在一个文件夹里面存了一堆txt文本,大小不一,名字不同,里面的内容不同,我要做一个功能实现:
比如我输入一个java,只要名字,路径,内容等等出现了java这个词汇,就返回结果给我
1.建一个java工程,导包(开发中通常是使用老版本的):
2.一步一步来:
我在D盘666文件夹放入一堆文本文件
然后在D盘的temp的index下创建索引库
创建索引:
package lucene; import java.io.File; import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test; public class MyFirstLucene {
// 创建索引
@Test
public void testIndex() throws Exception {
// 新建一个索引库(我放在D盘某文件夹内)
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
// 新建分析器对象
Analyzer analyzer = new StandardAnalyzer();
// 新建配置对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
// 创建一个IndexWriter对象(参数一个索引库,一个配置)
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建域对象
File f = new File("D:\\666");
File[] list = f.listFiles();
for (File file : list) {
// 创建一个文档对象
Document document = new Document();
// 文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
// 文件大小
long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize", file_size, Store.YES);
// 文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
// 文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent", file_content, Store.YES); // 添加到document
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField); // 创建索引
indexWriter.addDocument(document);
} // 关闭资源
indexWriter.close(); }
}
好的,运行成功,我打开D盘的temp文件夹中的Index文件夹:存入了一堆看不懂的东西,这就代表创建索引库成功:
3.查询索引:
// 搜索索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexSearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
Query query = new TermQuery(new Term("fileName", "spring"));
// 第五步:执行查询(显示条数)
TopDocs topDocs = indexSearcher.search(query, 10);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("------------");
}
// 第七步:关闭IndexReader对象
indexReader.close(); }
实现了基础功能
但是,这里有很大的一个问题:
无法处理中文
4.所以,接下来就处理中文问题:中文分析器(上边的示例采用的是标准分析器,即处理英文的分析器)
首先,我们看看用标准分析器分析中文的结果:
// 查看分析器的分词效果
@Test
public void testTokenStream() throws Exception {
// 创建一个分析器对象
Analyzer analyzer = new StandardAnalyzer();// 获得tokenStream对象
// 第一个参数:域名,可以随便给一个
// 第二个参数:要分析的文本内容
TokenStream tokenStream = analyzer.tokenStream("test",
"高富帅可以用二维表结构来逻辑表达实现的数据");
// 添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 添加一个偏移量的引用,记录了关键词的开始位置以及结束位置
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 将指针调整到列表的头部
tokenStream.reset();
// 遍历关键词列表,通过incrementToken方法判断列表是否结束
while (tokenStream.incrementToken()) {
// 关键词的起始位置
System.out.println("start->" + offsetAttribute.startOffset());
// 取关键词
System.out.println(charTermAttribute);
// 结束位置
System.out.println("end->" + offsetAttribute.endOffset());
}
tokenStream.close();
}
结果:
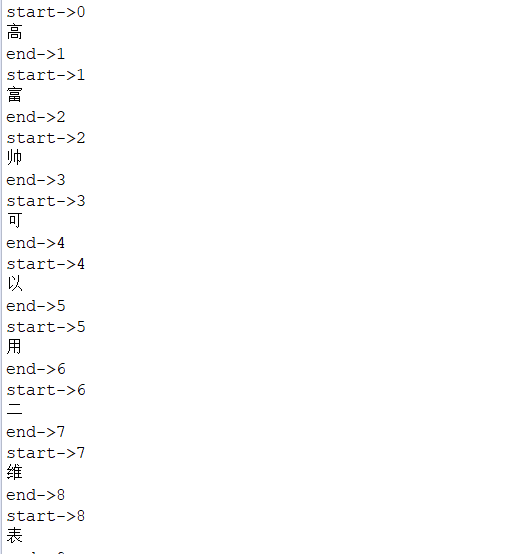
这里截取了一部分,发现如果采用了标准分析器,每一个中文都分隔开了,显然有问题
于是不能采用标准分析器:
用一个SmartChinese分析器:
// 查看分析器的分词效果
@Test
public void testTokenStream() throws Exception {
Analyzer analyzer = new SmartChineseAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("test",
"高富帅可以用二维表结构来逻辑表达实现的数据");
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println("start->" + offsetAttribute.startOffset());
System.out.println(charTermAttribute);
System.out.println("end->" + offsetAttribute.endOffset());
}
tokenStream.close();
}
效果有提升:

不过有一个问题:对于新词汇如高富帅这样的,它不识别

如果追求更好的效果:可以采用其他的第三方分析器
比如我这里采用一个IK分析器,可以自己添加进去“高富帅”这种词汇
@Test
public void testTokenStream() throws Exception {
Analyzer analyzer = new IKAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("test",
"高富帅可以用二维表结构来逻辑表达实现的数据");
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println("start->" + offsetAttribute.startOffset());
System.out.println(charTermAttribute);
System.out.println("end->" + offsetAttribute.endOffset());
}
tokenStream.close();
}
添加配置文件
IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
ext.doc:
高富帅
二维表
stopword.dic:
我
是
用
的
二
维
表
来
a
an
and
are
as
at
be
but
by
for
if
in
into
is
it
no
not
of
on
or
such
that
the
their
then
there
these
they
this
to
was
will
with
这时候效果:

解决了中文问题,并且可以扩展
上边对于索引库操作只有添加,我们还可以对索引库做其他操作:
查询的时候也可以有多种方式,下面代码示例:
package lucene; import java.io.File; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; /**
* 索引维护 添加 (上边已完成) 删除 修改 查询
*/
public class LuceneManager {
public IndexWriter getIndexWriter() throws Exception {
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
return new IndexWriter(directory, config);
} // 全删除
@Test
public void testAllDelete() throws Exception {
IndexWriter indexWriter = getIndexWriter();
indexWriter.deleteAll();
indexWriter.close();
} // 根据条件删除
@Test
public void testDelete() throws Exception {
IndexWriter indexWriter = getIndexWriter();
Query query = new TermQuery(new Term("fileName", "apache"));
indexWriter.deleteDocuments(query);
indexWriter.close();
} // 修改
@Test
public void testUpdate() throws Exception {
IndexWriter indexWriter = getIndexWriter();
Document doc = new Document();
doc.add(new TextField("fileN", "测试文件名", Store.YES));
doc.add(new TextField("fileC", "测试文件内容", Store.YES));
indexWriter.updateDocument(new Term("fileName", "lucene"), doc, new IKAnalyzer());
indexWriter.close();
} public IndexSearcher getIndexSearcher() throws Exception {
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));
IndexReader indexReader = DirectoryReader.open(directory);
return new IndexSearcher(indexReader);
} // 执行查询的结果
public void printResult(IndexSearcher indexSearcher, Query query) throws Exception {
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("------------");
}
} // 查询所有
@Test
public void testMatchAllDocsQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = new MatchAllDocsQuery();
System.out.println(query);
printResult(indexSearcher, query);
// 关闭资源
indexSearcher.getIndexReader().close();
} // 根据数值范围查询
@Test
public void testNumericRangeQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
// 参数的意思:文本大小在100到200字节之间,不包含100,包含200
Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 200L, false, true);
System.out.println(query);
printResult(indexSearcher, query);
// 关闭资源
indexSearcher.getIndexReader().close();
} // 可以组合查询条件
@Test
public void testBooleanQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
BooleanQuery booleanQuery = new BooleanQuery();
Query query1 = new TermQuery(new Term("fileName", "apache"));
Query query2 = new TermQuery(new Term("fileName", "lucene"));
// 类似 select * from user where id = ? or/and name = ?
booleanQuery.add(query1, Occur.MUST);// and
booleanQuery.add(query2, Occur.SHOULD);// or
System.out.println(booleanQuery);
printResult(indexSearcher, booleanQuery);
// 关闭资源
indexSearcher.getIndexReader().close();
} // 条件解释的对象查询(上边的查询和这种掌握一种即可)
@Test
public void testQueryParser() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());
// *:* 域:值
Query query = queryParser.parse("fileName:lucene OR fileContent:apache");
printResult(indexSearcher, query);
// 关闭资源
indexSearcher.getIndexReader().close();
} // 条件解析的对象查询 多个默认域
@Test
public void testMultiFieldQueryParser() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
String[] fields = { "fileName", "fileContent" };
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
Query query = queryParser.parse("lucene");
printResult(indexSearcher, query);
// 关闭资源
indexSearcher.getIndexReader().close();
} }
Lucene使用案例的更多相关文章
- 基于lucene的案例开发:查询语句创建PackQuery
转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/44656141 http://www.llwjy.com/blogdetail/1 ...
- 基于lucene的案例开发:纵横小说分布式採集
转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/46812645 http://www.llwjy.com/blogdetail/9 ...
- 【详细】Lucene使用案例
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引 ...
- Lucene入门案例一
1. 配置开发环境 官方网站:http://lucene.apache.org/ Jdk要求:1.7以上 创建索引库必须的jar包(lucene-core-4.10.3.jar,lucene-anal ...
- 2.Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程
1 Lucen目录介绍 2 lucene-core-3.6.2.jar是lucene开发核心jar包 contrib 目录存放,包含一些扩展jar包 3 案例 建立第一个Lucene项目 ...
- Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程
2.Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程 2014-12-07 23:39 2623人阅读 评论(0) ...
- Lucene全文检索(一)
全文检索的概念 1.从大量的信息中快速.准确的查找要的信息2.收索的内容是文本信息3.不是根据语句的意思进行处理的(不处理语义)4.全面.快速.准确是衡量全文检索系统的关键指标.5.搜索时英文不区分大 ...
- (转)全文检索技术学习(一)——Lucene的介绍
http://blog.csdn.net/yerenyuan_pku/article/details/72582979 本文我将为大家讲解全文检索技术——Lucene,现在这个技术用到的比较多,我觉得 ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
随机推荐
- Java往hbase写数据
接上篇读HDFS 上面读完了HDFS,当然还有写了. 先上代码: WriteHBase public class WriteHBase { public static void writeHbase( ...
- 使用thymeleaf一旦没有闭合标签就会报错怎么解决
问题:input标签未关闭报bug,代码稍有不慎就出小问题 使用springboot的thymeleaf模板时默认会对HTML进行严格的检查,导致当你的标签没有闭合时就会通不过,例如: //要想通过, ...
- idea中使用thymeleaf标签时有红色的波浪线怎么去掉
使用最新版本的idea2017可以解决,方法如下: 选择File->Settings->Editor->Inspections,然后搜索thymeleaf 将Expression v ...
- 1.2OpenCV如何扫描图像,利用查找表和计时
查找表 颜色缩减法:如果矩阵元素存储的是单通道像素,使用C或C++的无符号字符类型,那么像素可有256个不同值. 但若是三通道图像,这种存储格式的颜色数就太多了(确切地说,有一千六百多万种).用如此之 ...
- Amount of Degrees(数位dp)
题目链接:传送门 思路:考虑二进制数字的情况,可以写成一个二叉树的形式,然后考虑区间[i……j]中满足的个数=[0……j]-[0……i-1]. 所以统计树高为i,中有j个1的数的个数. 对于一个二进制 ...
- IntelliJ IDEA 2017版 编译器使用学习笔记(九)(图文详尽版);IDE使用的有趣的插件;IDE代码统计器;Mybatis插件
一.代码统计器,按照名字搜索即可,在file===setting------plugin 使用右键项目:点击自动统计 二.json转实体类 三.自动找寻bug插件 四.Remind me工具 五.检测 ...
- Linq高级应用
Linq的应用为我们带来了很大的方便,提高了coding效率,最近看到了一个用linq写的数独游戏算法,让我看到了Linq写的是如此优雅,耳目一新的感觉,以前没有写过这样的代码,同时也感觉到原来Lin ...
- js 匿名函数 用法
JS执行顺序为从上到下 先声明存储匿名函数的变量放在JS文件中 <script src="/Scripts/niming.js" type="text/javasc ...
- Redis源码笔记-初步
目录 目录 1 1. 前言 2 2. 名词 2 3. dict.c 2 3.1. siphash算法 2 3.2. 核心函数 3 3.3. 核心宏 3 3.4. 核心结构体 3 3.4.1. dict ...
- 深入浅出javascript(八)this、call和apply
_________此篇日志属于重要记录,长期更新__________ this,call,apply这三个是进阶JS的重要一步,需要详细的记录. ➢ this 一.作为对象的方法调用. 当函数作为对象 ...