(数据科学学习手札89)geopandas&geoplot近期重要更新
本文示例代码及数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
最近一段时间(本文写作于2020-07-10)geopandas与geoplot两个常用的GIS类Python库都进行了一系列较为重大的内容更新,新增了一些特性,本文就将针对其中比较实际的新特性进行介绍。
2 geopandas&geoplot近期重要更新内容
2.1 geopandas近期重要更新
2.1.1 新增高性能文件格式
从geopandas0.8.0版本开始,在矢量文件读写方面,新增了.feather与.parquet两种崭新的数据格式,他们都是Apache Arrow项目下的重要数据格式,提供高性能文件存储服务,使得我们可以既可以快速读写文件,又可以显著减少文件大小,做到了“多快好省”:
 图1
图1
在将geopandas更新到0.8.0版本后,便新增了read_feather()、to_feather()、read_parquet()以及to_parquet()这四个API,但要注意,这些新功能依赖于pyarrow,首先请确保pyarrow被正确安装,推荐使用conda install -c conda-forge pyarrow来安装。
安装完成后,我们就来一睹这些新功能的效率如何,首先我们创建一个足够大的虚拟表(200万行11列),并为其新增点要素矢量列:
import numpy as np
from shapely.geometry import Point
import pandas as pd
from tqdm.notebook import tqdm
# 创建虚拟表,其中字段名为了导出shapefile不报错加上非数字的前缀
base = pd.DataFrame(np.column_stack([np.random.randint(1, 100, (2000000, 10)),
np.random.uniform(-90, 90, (2000000, 2))]),
columns=['_'+str(i) for i in range(12)])
tqdm.pandas() # 开启apply进度条
base['geometry'] = base.progress_apply(lambda row: Point(row['_10'], row['_11']), axis=1) # 添加矢量列
base = gpd.GeoDataFrame(base, crs='EPSG:4326') # 转换为GeoDataFrame
最终得到一个较为庞大的GeoDataFrame,接着我们分别测试geopandas读写shapefile、feather以及parquet三种数据格式的耗时及文件占硬盘空间大小:
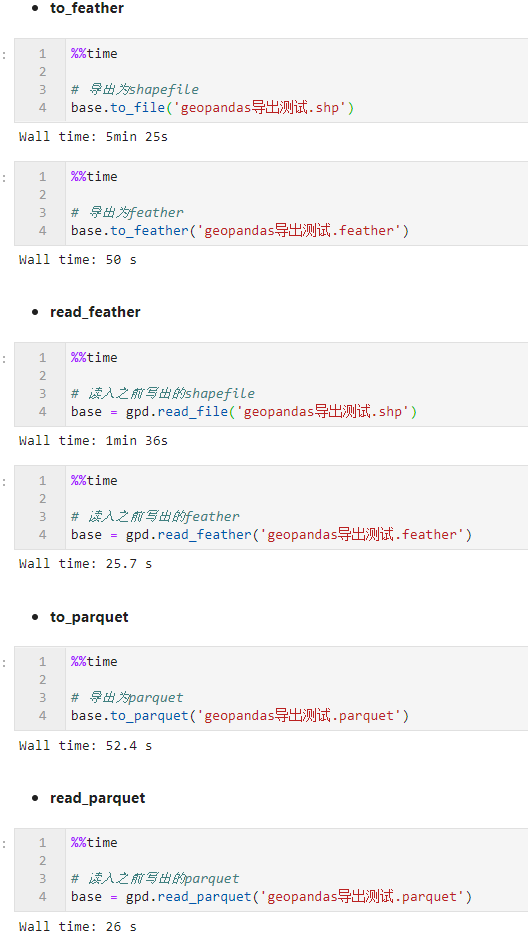 图2
图2
 图3
图3
具体的性能比较结果如下,可以看到与原始的shapefile相比,feather与parquet取得了非常卓越的性能提升,且parquet的文件体积非常小:
| 类型 | 写出耗时 | 读入耗时 | 写出文件大小 |
|---|---|---|---|
| shapefile | 325秒 | 96秒 | 619MB |
| feather | 50秒 | 25.7秒 | 128MB |
| parquet | 52.4秒 | 26秒 | 81.2MB |
所以当你要存储的矢量数据规模较大时,可以尝试使用feather和parquet来代替传统的文件格式。
2.2 geoplot近期重要更新
2.2.1 webplot在线底图切换方式升级
在之前我们出品的基于geopandas的空间数据分析系列文章中的geoplot篇(上)中,对可以添加在线底图的webplot()进行过介绍,但在先前的版本中只能使用固定的少数几种内置的在线地图,而在最近的版本中,webplot()的底图叠加方式进行了非常大的调整,使得可以利用参数provider来像folium那样自由切换底图,其传入格式为:
{
'url': 地图源url,
'attribution': 自定义字符串,必填
}
譬如我们可以在一个神奇的网站 http://openwhatevermap.xyz/#3/-60.50/167.87 上点击自己感兴趣的地图样式:
 图4
图4
将对应的url和自定义的attribution传入webplot()中:
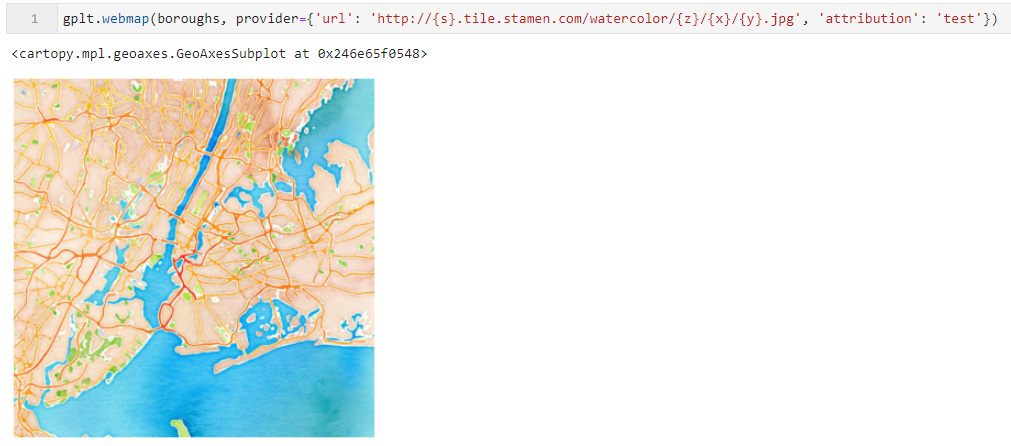 图5
图5
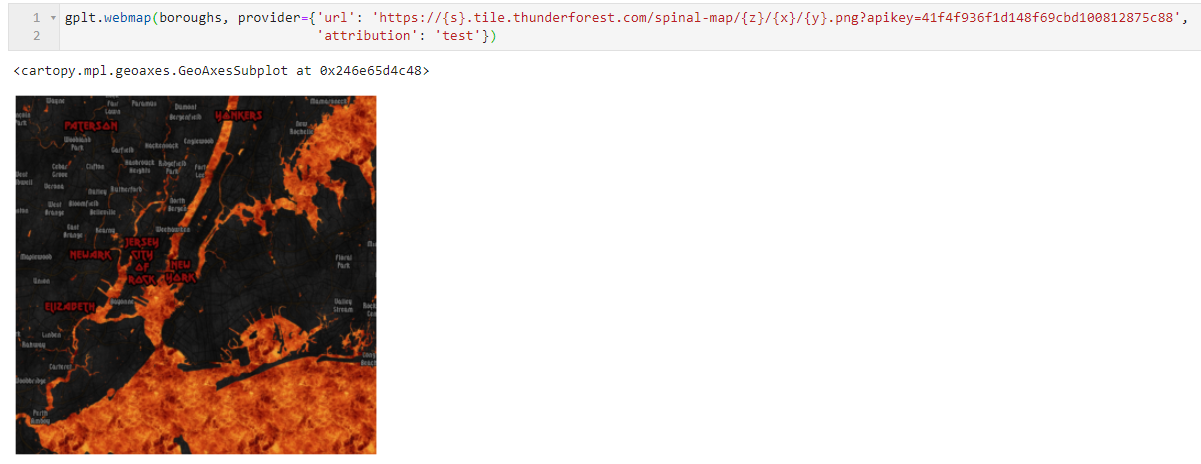 图6
图6
你也可以利用下面的方式查看contextily中所有内置的底图参数,从中选择你心仪的底图:
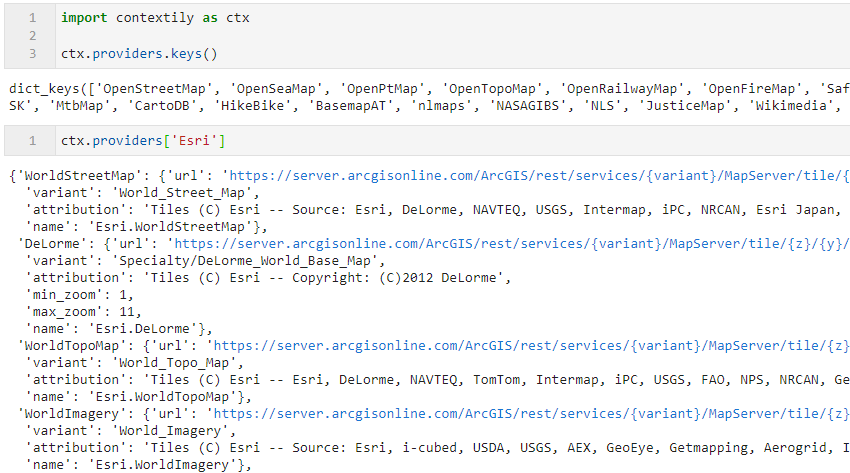 图7
图7
以上就是本文的全部内容,欢迎在评论区与我们进行讨论~
(数据科学学习手札89)geopandas&geoplot近期重要更新的更多相关文章
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- MATLAB实例:聚类网络连接图
MATLAB实例:聚类网络连接图 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 本文给出一个简单实例,先生成2维高斯数据,得到数据之后,用模糊C均值( ...
- 【百度前端学院 Day4】背景边框列表链接和更复杂的选择器
1. 背景 背景指的是元素内容.内边距和边界下层的区域(可用background-clip修改) background-color 背景色 background-image 背景图片(url) b ...
- AttributeError: 'PyQt5.QtCore.pyqtSignal' object has no attribute 'connect'
pyqt5信号要定义为类属性 #!/usr/bin/python3 # -*- coding: utf-8 -*- from PyQt5.Qt import * import sys class Wi ...
- 备份、恢复数据库(Dos命令提示符下)_数据库安装工具_连载_1
Dos命令提示符下: 备份.恢复数据库,是不是很简单啊,是的,当你20年不碰MS SQL,是不是又忘记了呢,答案也许也是吧,^_^虽然在程序中执行SQL代码时,很讨厌那个Go,正如MySQL中那个分号 ...
- update语句基本用法
UPDATE runoob_tbl SET runoob_title='学习 C++' WHERE runoob_id=;
- 基于docker-compose部署jumpserver
基于docker-compose部署jumpserver 组件说明 Jumpserver 为管理后台, 管理员可以通过 Web 页面进行资产管理.用户管理.资产授权等操作, 用户可以通过 Web 页面 ...
- sockaddr_in与sockaddr区别
先粘代码 struct sockaddr { __SOCKADDR_COMMON (sa_); /* Common data: address family and length. */ char s ...
- PIP设置镜像源
PIP设置镜像源 pip安装Python包时候,默认是国外的下载源,速度太慢,本文介绍几种设置pip国内镜像源的方法 镜像源 阿里云 http://mirrors.aliyun.com/pypi/si ...
- 4.kubernetes的服务发现插件-CoreDNS
1.1.部署K8S内网资源清单http服务 1.2.部署coredns 部署K8S内网资源清单http服务 在运维主机HDSS7-200.host.com上,配置一个nginx虚拟主机,用以提高k8s ...
- linux最小化安装命令补全
bash-completion 需要安装bash-completion才能补全,安装后,重新打开一个窗口就能生效.