全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在Github上,欢迎改进。
HanLP中文分词solr插件支持Solr5.x,兼容Lucene5.x。

快速上手
将hanlp-portable.jar和hanlp-solr-plugin.jar共两个jar放入
${webapp}/WEB-INF/lib下修改solr core的配置文件
${core}/conf/schema.xml:
<fieldType name="text_cn" class="solr.TextField"> <analyzer type="index" enableIndexMode="true" class="com.hankcs.lucene.HanLPAnalyzer"/> <analyzer type="query" enableIndexMode="true" class="com.hankcs.lucene.HanLPAnalyzer"/></fieldType>效果一览
对于新手来说,上面的两步可能太简略了,不如看看下面的step by step
启动solr
首先在solr-5.2.1\bin目录下启动solr:
solr start -f用浏览器打开http://localhost:8983/solr/#/,看到如下页面说明一切正常:
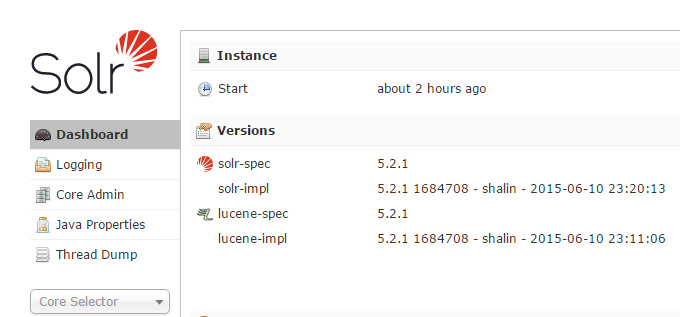
创建core
在solr-5.2.1\server\solr下新建一个目录,取个名字比如叫one,将 示例配置文件solr-5.2.1\server\solr\configsets\sample_techproducts_configs\conf 拷贝过来,对conf目录下的schema.xml做上述一步改动,意思是使用HanLP分词器来对text_cn域进行分词。接着修改 schema.xml中的默认域type,搜索
<field name="text" type="text" indexed="true" stored="false" multiValued="true"/>修改为
<field name="text" type="text_cn" indexed="true" stored="false" multiValued="true"/>意思是默认文本为text_cn类型。
完成了之后在solr的管理界面导入这个core one:

接着就能在下拉列表中看到这个core了:

上传测试文档
修改好了,就可以拿一些测试文档来试试效果了。hanlp-solr-plugin代码库中的src/test/resources下有个测试文档集合documents.csv,其内容如下:
id,title1,你好世界2,商品和服务3,和服的价格是每镑15便士4,服务大众5,hanlp工作正常代表着id从1到5共五个文档,接下来复制solr-5.2.1\example\exampledocs下的上传工具post.jar到resources目录,利用如下命令行将数据导入:
java -Dc=one -Dtype=application/csv -jar post.jar *.csvWindows用户的话直接双击该目录下的upload.cmd即可。
正常情况下输出如下结果:
SimplePostTool version 5.0.0Posting files to [base] url http://localhost:8983/solr/one/update using content-type application/csv...POSTing file documents.csv to [base]1 files indexed.COMMITting Solr index changes to http://localhost:8983/solr/one/update...Time spent: 0:00:00.059请按任意键继续. . .同时刷新一下core one的Overview,的确看到了5篇文档:

搜索文档
是时候看看HanLP分词的效果了,点击左侧面板的Query,输入“和服”试试:

发现精确地查到了“和服的价格是每镑15便士”,而不是“商品和服务”这种错误文档:

这说明HanLP工作良好。
要知道,不少中文分词器眉毛胡子一把抓地命中“商品和服务”这种错误文档,降低了查准率,拉低了用户体验,跟原始的MySQL LIKE有何区别?
代码调用
在Query改写的时候,可以利用HanLPAnalyzer分词结果中的词性等属性,如
String text = "中华人民共和国很辽阔";for (int i = 0; i < text.length(); ++i){ System.out.print(text.charAt(i) + "" + i + " ");}System.out.println();Analyzer analyzer = new HanLPAnalyzer();TokenStream tokenStream = analyzer.tokenStream("field", text);tokenStream.reset();while (tokenStream.incrementToken()){ CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class); // 偏移量 OffsetAttribute offsetAtt = tokenStream.getAttribute(OffsetAttribute.class); // 距离 PositionIncrementAttribute positionAttr = kenStream.getAttribute(PositionIncrementAttribute.class); // 词性 TypeAttribute typeAttr = tokenStream.getAttribute(TypeAttribute.class); System.out.printf("[%d:%d %d] %s/%s\n", offsetAtt.startOffset(), offsetAtt.endOffset(), positionAttr.getPositionIncrement(), attribute, typeAttr.type());}在另一些场景,支持以自定义的分词器(比如开启了命名实体识别的分词器、繁体中文分词器、CRF分词器等)构造HanLPTokenizer,比如:
tokenizer = new HanLPTokenizer(HanLP.newSegment() .enableJapaneseNameRecognize(true) .enableIndexMode(true), null, false);tokenizer.setReader(new StringReader("林志玲亮相网友:确定不是波多野结衣?"));...高级配置
HanLP分词器主要通过class path下的hanlp.properties进行配置,请阅读HanLP自然语言处理包文档以了解更多相关配置,如:
停用词
用户词典
词性标注
……
原文地址:http://www.hankcs.com/nlp/segment/full-text-retrieval-solr-integrated-hanlp-chinese-word-segmentation.html
全文检索Solr集成HanLP中文分词【转】的更多相关文章
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- 全文检索引擎Solr系列——整合中文分词组件mmseg4j
默认Solr提供的分词组件对中文的支持是不友好的,比如:“VIM比作是编辑器之神”这个句子在索引的的时候,选择FieldType为”text_general”作为分词依据时,分词效果是: 它把每一个词 ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- HanLP中文分词Lucene插件
基于HanLP,支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统. Maven <dependency> <groupId>com.hankcs.nlp&l ...
随机推荐
- CentOS7重装yum和python
卸载现有的Python和Yum 1.删除现有Python ##强制删除已安装程序及其关联 rpm -qa|grep python|xargs rpm -ev --allmatches --nodeps ...
- 如何把自己开发的项目上传到GitHub仓库或者码云仓库?
首先你需要用你的邮箱去注册一个自己的GitHub仓库 or 码云仓库.然后确保你的电脑安装了git. 码云仓库:https://gitee.com/ GitHub:https://github.com ...
- 第24课 - #pragma 使用分析
第24课 - #pragma 使用分析 1. #pragma简介 (1)#pragma 是一条预处理器指令 (2)#pragma 指令比较依赖于具体的编译器,在不同的编译器之间不具有可移植性,表现为两 ...
- 【二叉树-BFS系列1】二叉树的右视图、二叉树的锯齿形层次遍历
题目 199. 二叉树的右视图 给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值. 示例: 输入: [1,2,3,null,5,null,4] 输出: [1, ...
- Linux高级命令进阶
输出重定向 场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候需要使用到的输出重定向技术. >:覆盖输出,会覆盖掉原先的文件内容 ...
- k8s运行容器之Job(四)
Job 容器按照持续运行的时间可分为两类:服务类容器和工作类容器. 服务类容器通常持续提供服务,需要一直运行,比如 http server,daemon 等.工作类容器则是一次性任务,比如批处理程序, ...
- 天猫精灵对接1:outh对接
公司的智能家居产品需要接入语音控制,目前在对接阿里语音的天猫精灵 对接天猫精灵的第一步是完成outh鉴权 https://doc-bot.tmall.com/docs/doc.htm?spm=0.76 ...
- Spring boot +Thymeleaf 搭建springweb
对接天猫精灵的时候需要有网关服务器方提供几个页面,服务器已经有了,spring boot的 纯后台的,就加了Thymeleaf jar包添加几个页面跳转 maven配置 <!-- 引入thy ...
- JAVA之代理1JDK
代理主要有JDK的代理以及CGLIB的代理 代理方式 实现 优点 缺点 特点 JDK静态代理 代理类与委托类实现同一接口,并且在代理类中需要硬编码接口 实现简单,容易理解 代理类需要硬编码接口,在实际 ...
- 11.深入k8s:kubelet工作原理及源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 kubelet信息量是很大的,通过我这一篇文章肯定是讲不全的,大家可 ...