大话Spark(6)-源码之SparkContext原理剖析
SparkContext是整个spark程序通往集群的唯一通道,他是程序的起点,也是程序的终点。
我们的每一个spark个程序都需要先创建SparkContext,接着调用SparkContext的方法, 比如说 sc.textFile(filepath),程序最后也会调用sc.stop()来退出。
让我们来一起看下SparkContext里面到底是如何实现的吧!
1 SparkContext内的三大核心对象:DAGScheduler,TaskScheduler,SchedulerBackend
DAGScheduler:面向Stage调度机制的高层调度器,会为每个job计算一个Stage的DAG(有向无环图)。追踪RDD和Stage的输出是否物化(写磁盘或内存),并且执行一个最优的调度机制来执行。将stage作为tasksets提交到底层的TaskScheduler并在集群上运行。DAGScheduler监控作业运行调度的过程,如果某个阶段运行失败,会重新提交提交该调度阶段。
TaskScheduler:是一个接口,底层调度器。会根据ClusterManager的不同有不同的实现,在Standalone模式下的实现为TaskSchedulerImpl。接收DAGScheduler发过来的任务集,并以任务的形式分发到集群worker节点的Executor中去运行,任务失败TaskScheduler负责重试。如果TaskScheduler发现某个任务一直没运行完,可能会启动同样的任务去运行一个任务,结果选取早运行完的那个任务的(预测执行)。
SchedulerBackend:是一个接口,根据ClusterManager的不同会有不同的实现,Standalone模式下是StandaloneSchedulerBackend(2.3版本, 1.x版本是SparkDeploySchedulerBackend)底层接受TaskSchedulerImpl的控制,实际负责Master的注册和Tasks发送到Executor等操作。
2.1 图示SparkContext实例化过程
如下图所示,我们看下SparkContext在实例化过程中,会创建多少核心实例来完成整个应用程序的注册。
 

2.2 时序图
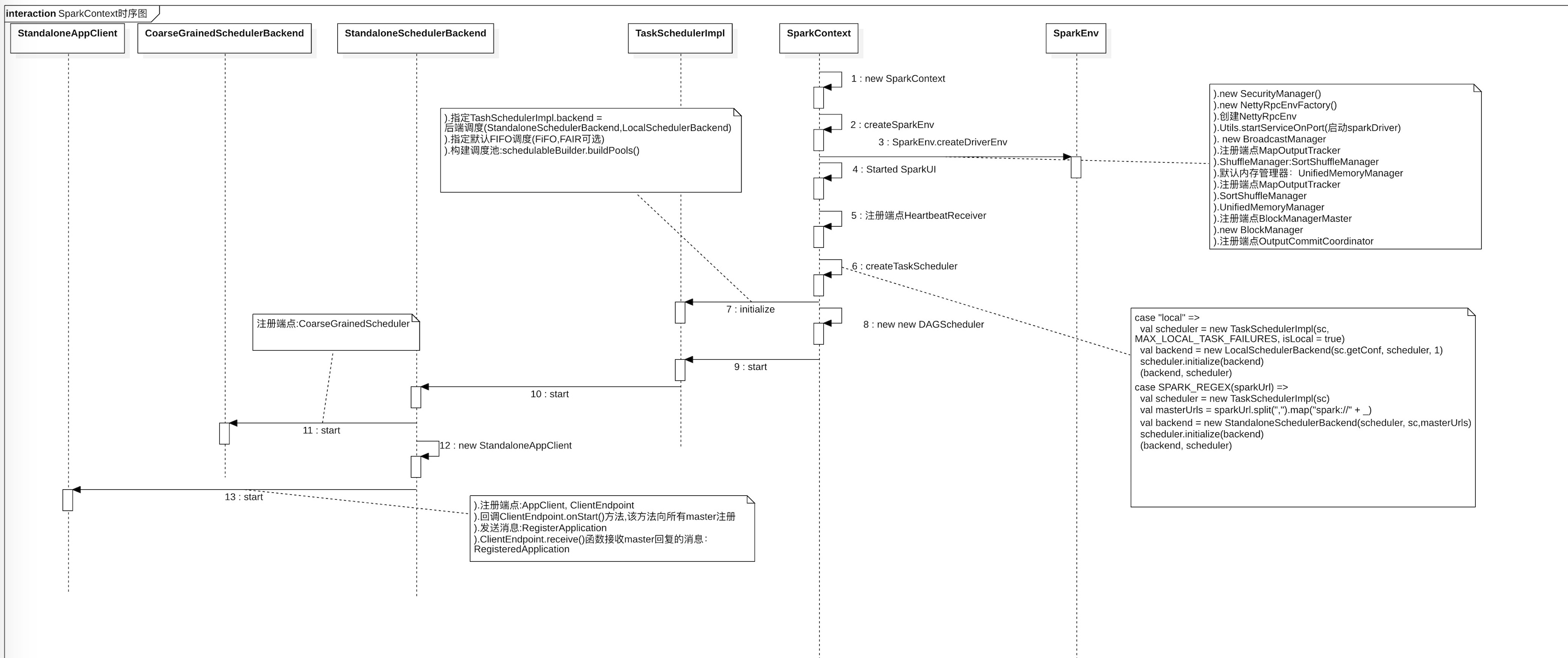 

3 主要内容描述
- createTaskScheduler
- createSchedulerBackend
- SchedulerBackend的initialize初始化构造默认FIFO调度吃
- new DAGScheduler
- 创建StandaloneAppClient与spark集群通信
- 创建AppClient,ClientEndPoint(向master注册)
- 发消息RegisterApplication
- ClientEndpoint.receive()函数接收master的回复消息
4 通过源码看SparkContext实例化过程(Standalone模式)
scala中不在方法里的成员都会被实例化,开始最关键的方法是createTaskScheduler,它是位于 SparkContext 的 构造函数中,当它实例化时会直接被调用。
createTaskScheduler创建了TaskSchedulerImpl并通过StandaloneSchedulerBackend对其进行初始化。
createTaskScheduler返回scheduleBackend和TaskScheduler, 然后又基于TaskScheduler构造DAGScheduler。
SparkContext调用createTaskScheduler方法,返回SchedulerBackend和TaskScheduler。
 
下createTaskScheduler方法内部:根据不同的master url创建不同的TaskScheduler实现和不同的SchedulerBackend实现。 master url就是创建SparkContext的时候传的,例如下面的
local:val conf = new SparkConf().setAppName("TestApp").setMaster("local")
val sc = new SparkContext(conf)
 
taskSchedulerImpl的初始化方法,创建一个默认FIFO的调度池:
 
taskSchedulerImpl初始化后,随即为其设置DAGScheduler,然后调用其start()方法:
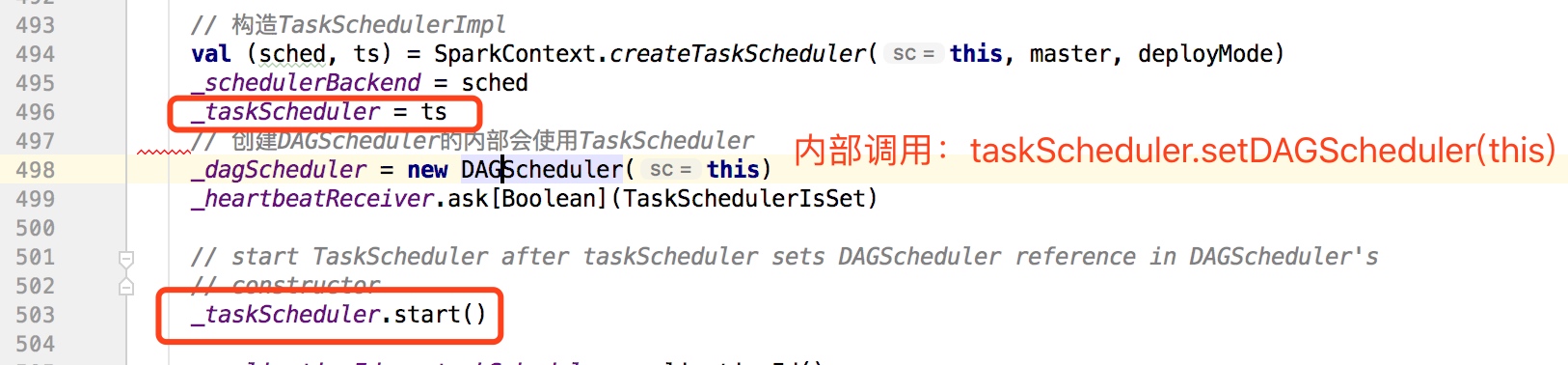 
在taskSchedulerImpl的start()方法中再调用backend(StandaloneSchedulerBackend)的start()方法,其中最重要的就是创建ApplicationDescription和AppClient
 
创建ApplicationDescription和AppClient
 
ApplicationDescription存放当前应用程序信息,name,cores,memory等。
AppClient是Application与Spark通信的组件。在appClient.start()的时候会创建内部类ClientEndPoint
 
clientEndPoint注册master。
 
注册的时候会从线程池中拿出一个线程并且会带上APPDescription中的作业信息。
 
ClientEndpoint.receive接收master返回的消息,根据不同的返回消息做不同的操作。
 
SparkContext.DAGScheduler
 
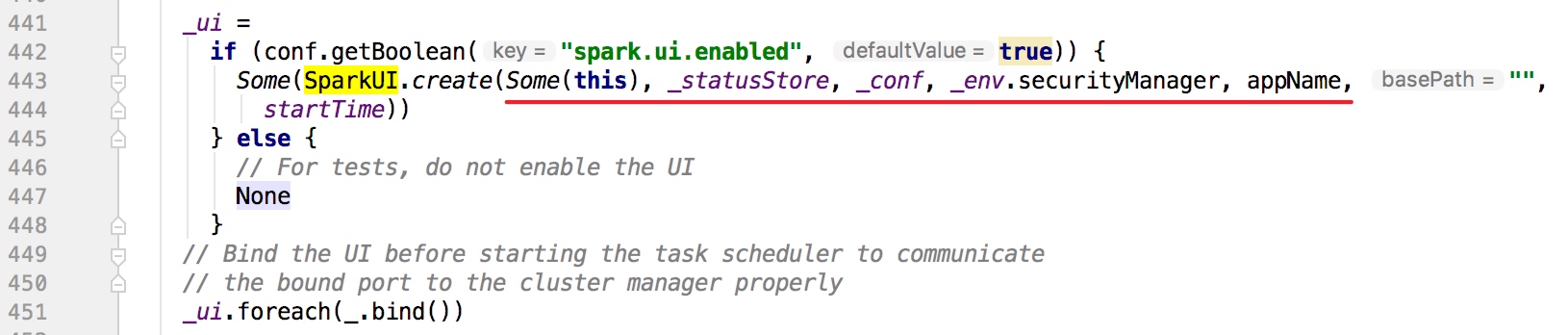
创建SparkUI

以上就是SparkContext源码的构造过程,感谢阅读。
End。
原文链接:
大话Spark(6)-源码之SparkContext原理剖析
大话Spark(6)-源码之SparkContext原理剖析的更多相关文章
- 大话Spark(7)-源码之Master主备切换
Master作为Spark Standalone模式中的核心,如果Master出现异常,则整个集群的运行情况和资源都无法进行管理,整个集群将处于无法工作的状态. Spark在设计的时候考虑到了这种情况 ...
- Spring Boot 揭秘与实战 源码分析 - 工作原理剖析
文章目录 1. EnableAutoConfiguration 帮助我们做了什么 2. 配置参数类 – FreeMarkerProperties 3. 自动配置类 – FreeMarkerAutoCo ...
- 大话Spark(8)-源码之DAGScheduler
DAGScheduler的主要作用有2个: 一.把job划分成多个Stage(Stage内部并行运行,整个作业按照Stage的顺序依次执行) 二.提交任务 以下分别介绍下DAGScheduler是如何 ...
- 大话Spark(9)-源码之TaskScheduler
上篇文章讲到DAGScheduler会把job划分为多个Stage,每个Stage中都会创建一批Task,然后把Task封装为TaskSet提交到TaskScheduler. 这里我们来一起看下Tas ...
- Spark源码分析 – SparkContext
Spark源码分析之-scheduler模块 这位写的非常好, 让我对Spark的源码分析, 变的轻松了许多 这里自己再梳理一遍 先看一个简单的spark操作, val sc = new SparkC ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Spark SQL源码解析(五)SparkPlan准备和执行阶段
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Tomcat源码分析——请求原理分析(中)
前言 在<TOMCAT源码分析——请求原理分析(上)>一文中已经介绍了关于Tomcat7.0处理请求前作的初始化和准备工作,请读者在阅读本文前确保掌握<TOMCAT源码分析——请求原 ...
随机推荐
- 【noi 2.6_90】滑雪(DP)
题意:输出最长下降路径的长度. 解法:f[i][j]表示结尾于(i,j)的最长的长度.由于无法确定4个方位已修改到最佳,所以用递归实现. 1 #include<cstdio> 2 #inc ...
- hdu5391 Zball in Tina Town
Problem Description Tina Town is a friendly place. People there care about each other. Tina has a ba ...
- DSC注册Agent失败- InternalServerError
问题 有大概5台Agent Server,注册的时候,发现2台可以成功,其他的不成功. 注册失败的错误日志如下: 初步尝试 首先,Pull Server已经平稳的运行了几年了,此次注册还有部分Agen ...
- WPF 之命令(七)
一.前言 事件的作用是发布和传播一些消息,消息送达接收者,事件的使命也就完成了,至于消息响应者如何处理发送来的消息并不做规定,每个接收者可以使用自己的行为来响应事件.即事件不具有约束力. 命令 ...
- codeforces 878A
A. Short Program time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- Linux 驱动框架---设备文件devfs
设备文件系统 Linux引入了虚拟文件系统,从而使设备的访问可以像访问普通文件系统一样.因此在内核中描述打开文件的数据inode中的rdev成员用来记录设备文件对应到的设备号.设备文件也由一个对应的f ...
- Pycharm无法import caffe
这里是首先建立在读者可以在终端导入而无法在Pycharm中导入的情况下的: 参考链接(问题的最后一个回答) 选用了虚拟环境的python作为解释器, 但由于caffe的特殊性, 依然没有导入, 原因就 ...
- set CSS style in js solutions All In One
set CSS style in js solutions All In One css in js set each style property separately See the Pen se ...
- CSS ::marker All In One
CSS ::marker All In One CSS pseudo element / CSS 伪元素 /* user agent stylesheet */ ::marker { unicode- ...
- uname -a
uname -a Linux shell command https://en.wikipedia.org/wiki/Uname#:~:text=uname $ uname # Darwin $ un ...