词嵌入之GloVe
什么是GloVe
GloVe(Global Vectors for Word Representation)是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
GloVe实现步骤
构建共现矩阵
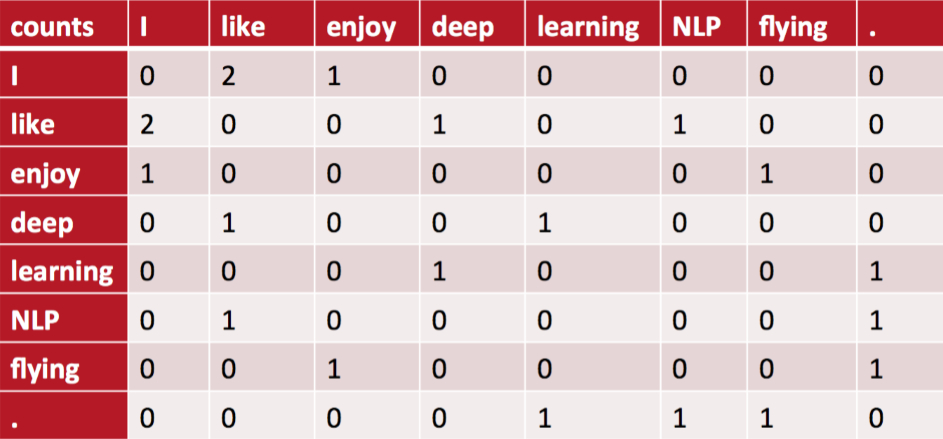
统计词与词在固定窗口大小内共同出现的次数并构建一个共现矩阵。例如有以下三句话:
- I like deep learning.
- I like NLP.
- I enjoy flying
当窗口大小为2时,构造的共现矩阵为:
词向量与共现矩阵的关系
设共现矩阵为X,其第i行第j个元素为\(X_{ij}\)。与Word2Vec相同,GloVe同样有两个词向量矩阵分别由输入层到隐藏层、隐藏层到输出层。设中心词i在第一个词向量矩阵中所对应的词向量为\(w_i\),上下文词j在第二个词向量矩阵中所对应的词向量为\(\widetilde w_j\),则GloVe所构造的词向量与共现矩阵间的近似关系为:
\[w_i^T\widetilde w_j+b_i+\widetilde b_j=\log X_{ij}
\]其中,\(b_i\)和\(\widetilde b_j\)为词i和词j的偏置项。公式的由来见第三节的推导部分。
损失函数
基于词向量与共现矩阵间的近似关系,可以构造如下损失函数:
\[J=\sum_{i,j=1}^Vf(X_{ij})(w_i^T\widetilde w_j+b_i+\widetilde b_j-\log X_{ij})^2
\]其中V为词汇表大小。这个损失函数是加了权重项的均方误差,关于权重项\(f(X_{ij})\),我们希望:
- 共现次数多的两个词的权重应当大于共现次数少的两个词的权重,因此\(f(X_{ij})\)应当是非递减的;
- 但\(f(X_{ij})\)也不应当过大,因此\(f(X_{ij})\)应当有上限;
- 共现次数为0的两个词其权重也应当为0。
基于以上三点,GloVe作者构造了以下权重函数:
\[f(X_{ij})=\left\{\begin{aligned}
(\frac{X_{ij}}{x_{max}})^\alpha \quad \quad X_{ij}<x_{max}
\\
1 \qquad\quad otherwise
\end{aligned}\right.
\]其中\(\alpha\)在原论文中被设置为了0.75,它的作用与Word2Vec中负采样处的\(\alpha\)类似,也是为了提高共现次数小的两个词的权重,进而提高低频词的词向量的准确度。\(x_{max}\)是共现次数的上限,在原论文中被设置为了100。
其他细节
- 在统计共现矩阵的时候,并不是说只要两个词同时出现在了一个窗口内共现矩阵的对应项就会加1,GloVe根据两个单词在上下文窗口的距离d,提出了一个衰减函数(decreasing weighting):\(decay=\frac{1}{d}\)用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
- 与Word2Vec相同,GloVe同样有两个词向量矩阵分别由输入层到隐藏层、隐藏层到输出层,理论上是这两个矩阵式对称的,唯一的区别是初始化的值不一样而导致最终的值不一样。Word2Vec是选择第一个矩阵作为最终的词向量矩阵,但理论上二者都可以当成最终的结果来使用。GloVe的选择是将二者的和作为最终的词向量。由于二者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性。
GloVe公式推导
记\(X_i=\sum_{k=1}^VX_{ik}\)为词i所有窗口内共现词的数量,\(p_{ik}=\frac{X_{ik}}{X_i}\)为单词k出现在单词i的上下文中的概率,\(p_{ij,k}=\frac{p_{ik}}{p_{jk}}\)为为单词k出现在单词i的上下文中的概率与为单词k出现在单词j的上下文中的概率的比值。当单词i和单词j与单词k均相关或者均不相关时该比值趋近于1;当单词i与单词k相关,单词j与单词k不相关时该比值很大;当单词i与单词k不相关,单词j与单词k相关时该比值很小。
作者通过实验发现通过构建词向量与这个比值的关系比直接构建词向量与条件概率的关系效果更好。
假设词向量与上述比值通过函数F进行对应,即:
\[F(w_i,w_j,w_k)=\frac{p_{ik}}{p_{jk}}
\]由于\(\frac{p_{ik}}{p_{jk}}\)最终反应的实际上是单词i和单词j间的关系,因此可以将上式修改为:
\[F(w_i-w_j,w_k)=\frac{p_{ik}}{p_{jk}}
\]上式左边是向量,右边是标量,因此可以对左边进行内积:
\[F((w_i-w_j)^Tw_k)=F(w_i^Tw_k-w_j^Tw_k)=\frac{p_{ik}}{p_{jk}}
\]上式左边是差,右边是商,当F为指数函数时满足,因此:
\[\frac{e^{w_i^Tw_k}}{e^{w_j^Tw_k}}=\frac{p_{ik}}{p_{jk}}
\]分别令分子分母相同,则:
\[e^{w_i^Tw_k}=\frac{X_{ik}}{X_i}
\]则:
\[w_i^Tw_k=\log X_{ik}-\log X_i
\]将i和k交换后上式左边仍然不变,但右边值变了。为了保持右边的值不变,考虑到对称性,在上式左边加上两个偏置项\(b_i\)和\(b_k\),则:
\[w_i^Tw_k+b_i+b_j=\log X_{ik}
\]GloVe与Word2Vec的比较
Word2Vec每次都是利用局部窗口内的信息进行更新,而GloVe每次更新都利用到了共现矩阵中所统计的全局共现信息,所以理论上来说GloVe抗噪声能力更强,对语料的利用更加充分,效果也应当更好。从原论文给出的实验结果来看,GloVe的性能是远超Word2Vec的,但网上也有人说GloVe和Word2Vec实际表现其实差不多。
词嵌入之GloVe的更多相关文章
- L25词嵌入进阶GloVe模型
词嵌入进阶 在"Word2Vec的实现"一节中,我们在小规模数据集上训练了一个 Word2Vec 词嵌入模型,并通过词向量的余弦相似度搜索近义词.虽然 Word2Vec 已经能够成 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入 给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名. 但是如果是榴莲种植员可能就无法 ...
- NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立
http://3g.163.com/all/article/DM995J240511AQHO.html 选自the Gradient 作者:Sebastian Ruder 机器之心编译 计算机视觉领域 ...
- 2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入
1. one-hot编码 # 字符集的one-hot编码 import string samples = ['zzh is a pig','he loves himself very much','p ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
- NLP之基于词嵌入(WordVec)的嵌入矩阵生成并可视化
词嵌入 @ 目录 词嵌入 1.理论 1.1 为什么使用词嵌入? 1.2 词嵌入的类比推理 1.3 学习词嵌入 1.4 Word2Vec & Skip-Gram(跳字模型) 1.5 分级& ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
随机推荐
- 移动端 canvas统计图
一.折线图 1. 获取画布画笔 2. 封装画线的方法 3. 画坐标轴 4. 循环数据画横轴 > 4.1 画刻度 > 4.2 刻度文字 > 4.3 画折线 > 4.4 画点 5. ...
- 题解洛谷P1538【迎春舞会之数字舞蹈】
方法:暴力,判断,输出 本题为了更好理解建议各位可以复制样例来研究,甚至可以复制题解来测试思想,相信大家不会抄. 有什么不好的请大佬们在评论里指出,谢谢 #include <bits/stdc+ ...
- 2020软件测试工程师面试题汇总(内含答案)-看完BATJ面试官对你竖起大拇指!
测试技术面试题 1.什么是兼容性测试?兼容性测试侧重哪些方面? 参考答案: 兼容测试主要是检查软件在不同的硬件平台.软件平台上是否可以正常的运行,即是通常说的软件的可移植性. 兼容的类型,如果细分的话 ...
- Ubuntu16.04网卡配置
新安装的Ubuntu16.04系统容易出现无法连接有线网络的问题,主要是因为网卡配置不完善,下面通过实操讲解如何解决该问题. 1. 查看网络设备 ifconfig 发现只有enp2s0和lo,没有et ...
- python装饰器学习详解-函数部分
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 最近阅读<流畅的python>看见其用函数写装饰器部分写的很好,想写一些自己的读书笔记. ...
- [LeetCode]319. Bulb Switcher灯泡开关
智商压制的一道题 这个题有个数学定理: 一般数(非完全平方数)的因子有偶数个 完全平凡数的因子有奇数个 开开关的时候,第i个灯每到它的因子一轮的时候就会拨动一下,也就是每个灯拨动的次数是它的因子数 而 ...
- 什么情况下调用doGet()和doPost()?
默认情况是调用doGet()方法,JSP页面中的Form表单的method属性设置为post的时候,调用的为doPost()方法: 为get的时候,调用deGet()方法.
- 四元数和旋转(Quaternion & rotation)
四元数和旋转(Quaternion & rotation) 本篇文章主要讲述3D空间中的旋转和四元数之间的关系.其中会涉及到矩阵.向量运算,旋转矩阵,四元数,旋转的四元数表示,四元数表示的旋转 ...
- 使用纯 CSS 实现滚动阴影效果
开门见山,有这样一种非常常见的情况,对于一些可滚动的元素而言.通常在滚动的时候会给垂直于滚动的一侧添加一个阴影,用于表明当前有元素被滚动给该滚出了可视区域,类似这样: 可以看到,在滚动的过程中,会出现 ...
- Java GC --- Java堆内存
Java堆是被所有线程共享的一块内存区域,所有对象实例和数组都在堆上进行内存分配.为了进行高效的垃圾回收,虚拟机把堆内存划分成: 1. 新生代(Young Generation): 由 Eden 与 ...