对hadoop之RPC的理解
因为公司hadoop集群出现了一些瓶颈,在机器不增加的情况下需要进行优化,不管是存储还是处理性能,更合理的利用现有集群的资源,所以来学习了一波hadoop的rpc相关的知识和hdfs方面的知识,以及yarn相关的优化,学完之后确实明白了可以在哪些方面进行优化,可以对哪些参数进行调整,有点恍然大悟的感觉,本文的大部分的内容来于《Hadoop 2.x HDFS源码剖析》,自认为这本书写的挺好,确实能学到很多东西,看了本篇博客如果不懂,还是可以继续学习这本书,讲的很详细,很清晰。本篇文章主要从RPC的原理、hdfs通信协议和Hadoop RPC的实现这三部分进行阐述。
一、RPC原理
1.1、RPC框架
RPC(Pemote Procedure CallProtocol)是一种通过网络调用远程计算机服务协议,RPC协议假定存在某些网络传输协议,如TCP,UDP,并通过这些传输协议为通信程序之间传递访问请求或者应答信息。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。为实现该目标,RPC 框架需提供一种透明调用机制让使用者不必显式的区分本地调用和远程调用。
RPC通常采用客户机/服务器模型。请求程序是一个客户机,而服务提供程序则是一个服务器。客户端首先会发送一个有参数的调用请求到服务端,等待服务端的响应消息,在服务端,服务提供程序会保持睡眠状态直到有调用请求到达为止,当接收到请求,服务端会对请求就行调用,计算结果,最后返回给客户端。RPC的框架图如下图所示:
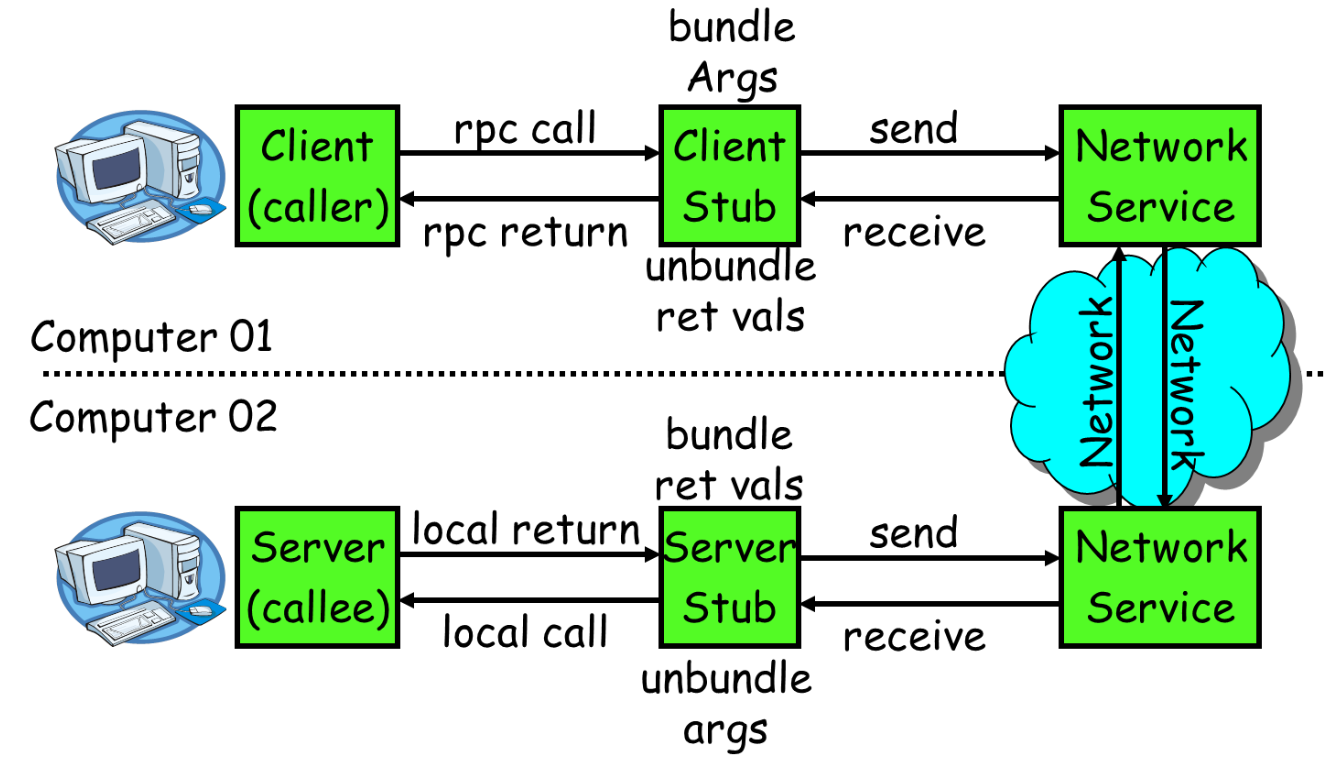
上图所示,RPC主要包括如下几个部分:
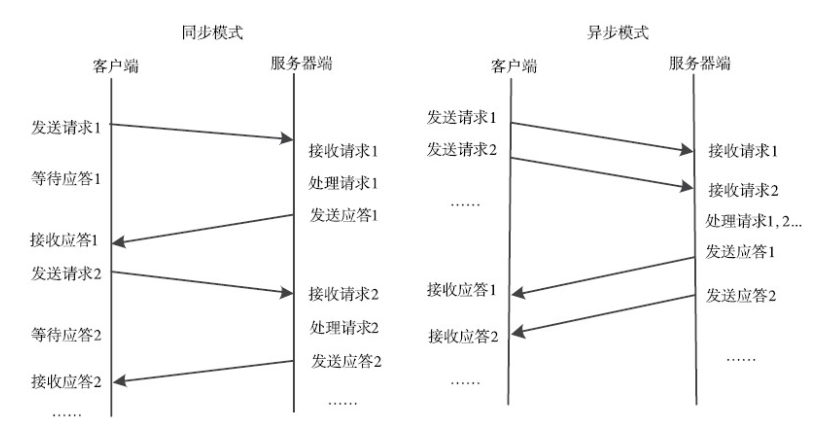
1、通信模块:传输RPC请求和响应的网络通信模块,可以基于TCP协议,也可以基于UDP协议,它们在客户和服务器之间传递请求和应答消息,一般不会对数据包进行任何处理。请求–应答协议的实现方式有同步方式和异步方式两种,如下图所示。
2、客户端的stub程序:在客户端stub程序表现为像本地程序一样,但底层会将调用参数和请求序列化并通过通信模块发送给服务器。之后stub会等待服务器的响应信息,并将响应信息反序列化给请求程序。
3、服务端stub程序:stub程序会将客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序的响应信息徐丽华并发回给客户端。
4、请求程序:请求程序像本地调用方法一样调用客户端stub程序,然后接收stub程序的返回响应信息。
5、服务程序:服务端会接收来自stub的调用请求,执行对应的逻辑并返回执行结果。
1.2、RPC特点
- 透明性:远程调用其他机器上的程序,对用户来说就像调用本地方法一样。
- 高性能:RPC Server能够并发处理多个来自Client的请求。
- 可控性:JDK中已经提供了一个RPC框架——RMI,但是该PRC框架过于重量级并且可控之处比较少,所以Hadoop RPC实现了自定义的RPC框架。
1.3、RPC请求基本步骤
- 客户程序以本地方式调用系统产生的客户端的Stub程序;
- 该Stub程序将函数调用信息序列化并按照网络通信模块的要求封装成消息包,并交给通信模块发送到远程服务器端。
- 远程服务器端接收此消息后,将此消息发送给相应的服务端的Stub程序;
- Stub程序拆封消息,并反序列化,形成被调过程要求的形式,并调用对应函数;
- 被调用函数按照所获参数执行,并将结果返回给服务端的Stub程序;
- Stub程序将此结果封装成消息,通过网络通信模块逐级地传送给客户程序。
二、HDFS的通信协议
HDFS通信协议抽象了HDFS各个节点之间的调用接口,主要分为hadoop RPC接口和流式接口
2.1、hadoop RPC接口
1、ClientProtoclo
该接口定义客户端与namenode节点间的接口,用于客户端对文件系统的所有操作,读写都需要与该接口交互。
该接口定义了由客户端发起,namenode响应的操作,主要包括hdfs文件读写的相关操作,hdfs命名空间,快照,缓存相关的操作。
(客户端与Namenode交互)一般性操作,客户端会通过getBlockLocations()方法向Namenode获取文件的具体位置信息(指的是存储这个数据块副本的所有datanode的信息),还会使用reportBadBlocks()方式向Namenode汇报错误的数据块。
(写,追写数据)首先会使用create()方法通过hdfs文件系统目录树中创建一个新的空文件,然后调用addBlock()方法获取存储文件的数据块的位置信息,最后客户端根据位置信息与datanode建立数据流管道,写入数据。追写略有不同,首先通过append()方法获取最后一个可写数据块的位置信息并打开一个已有的文件(没有写满的),然后建立好数据管道流,并向节点中追写数据,当写满后,则会像create()方法一样,客户端会调用addBlock()方法获取新的数据块。当客户端完成了整个文件的写入操作后,会调用complete()方法通知Namenode,这个操作会提交新写入的HDFS文件的所有数据块,当数据块满则副本数时,则返回true,否则返回false;会重试。
如上是顺利完成,如果在客户端获取到一个新申请的数据块时,无法建立连接,会调用abandonBlock()方法放弃喝个数据块,客户端会再次通过addBlock()方法获取新的数据块。
在客户端写某个数据块时,如果副本节点出了错误,客户端会调用getAdditionalDatanode()方法向Namenode申请一个新的datanode来替代故障datanode。然后客户端调用updateBlockForPipeline()方法向Namenode申请为这个数据块分配新的时间戳,这样故障节点的数据块的时间戳就会过期,回本删除,最后客户端就可以使用新的时间戳建立新的数据管道流近些写数据了。
如果在写的过程中客户端发生了故障,为了防止故障,对于任意的一个client打开的文件都需要client定期调用clientProtocol.renewLease()方法更新租约,如果Namenode长时间没有收到client的租约更新信息,就会认为client故障,触发一次租约恢复操作,关闭文件并且同步所有数据节点上这个文件数据块的状态,确保hdfs系统中这个文件正确且保持一致。
如果在写数据的过程中Namenode发生故障呢,则需要HA发挥作用了。
2、ClientDatanodeProtocol
客户端与datanode间的接口,主要用户客户端获取datanode节点信息是调用,真正的读写是通过流式接口进行的。其中主要定义两部分,一部分是支持HDFS文件读写的操作,例如调用getReplicaVisibleLength()获取datanode节点某个数据块的真实数据长度和getBlockLocalPathInfo()方法等,另一部分是支持DFSAdmin中与datanode节点管理相关的命令。
3、DatanodeProtocol
datanode与namenode间的通信接口,包括namenode通过该接口中的方法返回向datanode下发指令。datanode则是通过该接口向namenode进行注册,汇报块信息和缓存信息。DataNode使用这个接口与Namenode握手、注册、发送心跳、进行全量以及增量的数据块汇报,NameNode会在Datanode的心跳响应中携带Namenode的指令。该接口主要的方法分为三种类型,Datanode的启动相关,心跳相关,数据块的读写相关。
(Datanode启动相关)Datanode启动会与NameNode进行4次交互,通过versionRequest()与NameNode进行握手操作,然后调用refisterDatanode()向NameNode注册当前的datanode,接着调用blockReport()汇报datanode上存储的所有数据块信息,最后调用cacheReport()汇报datanode缓存的所有数据块。
握手主要是返回namenode的一些命名空间ID,集群ID,hdfs的版本号等,datanode收到信息后进行校验对比,判断是否能够与该namenode协同工作,能否注册。
块汇报后会根据datanode上报数据块存储情况建立数据块与datanode节点的对应关系。blockReport()在启动的时候和指定时间间隔的情况下发生。cacheReport()和blockReport()方法完全一致。只不过是汇报当前datanode上的缓存的所有数据块。
(心跳相关)datanode会定期的向namenode发送心跳(dfs.heartbeat.interval=3s),如果namenode很长时间没有收到datanode的心跳信息,则认为该datanode失效。每次心跳都会包含datanode节点上的存储的状态,缓存状态,正在写文件数据的连接数,读写数据使用的线程等。在开启了HA的状态下,datanode需要向两个namenode同时发送心跳信息,不过只有active才会向datanode发送指令。
(数据块读写相关)datanode会向namenode汇报损坏的数据块,以及定期性namenode汇报datanode新接手的数据块或者删除的数据块。
4、InterDatanodeProtocol
datanode和datanode间的接口,主要用于数据块的恢复操作,以及同步datanode节点上存储数据块副本的信息。主要用于租约恢复操作。
客户端打开一个文件进行操作时,首先要获取这个文件的租约,并且还需要定期更新这个租约,不然,namenode则会认为该client异常,namenode就会触发租约恢复操作(同步数据管道中所有datanode上该文件数据库的状态,并强制关闭这个文件)。
租约恢复不是由namenode控制的负责的,而是namenode在数据管道中选择出一个datanode的恢复主节点,然后下发恢复指令触发这个数据节点控制租约恢复操作,也就是有这个恢复主节点协调整个租约恢复操作的的过程。租约恢复操作就是将数据管道中所有的datanode节点保存同一的数据块状态(时间戳和数据块长度)同步一致。
5、NamenodePortocol
主要用于namenode的ha机制,或者单节点的情况下是secondaryNamenode也namenode之间的通信接口
2.2、流式接口
流式接口是HDFS中基于TCP或者HTTP实现的接口,在HDFS中,流式接口包括基于TCP的DataTransferProtocol接口,以及HA架构中Active Namenode和Standby Namenode之间的HTTP接口。
1、DataTransferProtocol
DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS客户端与数据节点以及数据节点与数据节点之间的数据块的传输就是基于DataTransferProtocol接口实现的。
2、Active Namenode和Standby Namenode间的HTTP接口
Namenode会定期将文件系统的命名空间保存在一个fsimage文件中,以及会将Namenode的命名空间的修改操作先写入到editlog文件中,定期的合并fsimage和editlog文件。这个合并操作由Secondary Namenode或者Standby Namenode去实现,合并完之后又要同步给Active Namenode,在Active Namenode和Standby Namenode之间的HTTP接口就是用来传输的fsimage文件的。
二、Hadoop RPC的实现
Hadoop作为一个分布式的存储系统,各个节点之间的通信和交互是必不可少的,所以在hadoop有一套节点之间的通信交互机制。RPC(Pemote Procedure CallProtocol,远程过程调用协议)允许本地程序像调用本地方法一样调用远程机器上的应用程序提供服务,Hadop RPC机制是基于IPC实现的,主要用到了java的动态代理,java NIO以及protobuf等基础技术(没有基于java的RMI)。
Hadoop RPC框架主要由三个类组成:RPC、Client和Server类,RPC类用于对外提供一个使用Hadoop RPC框架的接口,Client类用于实现客户端功能,Server类用于实现服务端功能。
3.1、RPC类的实现
客户端调用程序可以通过RPC类提供的waitForProxy()和getProxy()方法获取指定RPC协议的代理对象,然后RPC客户端就可以调用代理对象的方法发送RPC请求到服务器了。
在服务端,服务端程序调用RPC内部的Builder.build()方法构造一个RPC.Server类,然后调用RPC.server.start()方法启动Server对象监听并响应RPC请求。
3.2、Client类的实现
HDFS Client会获取一个ClientProtocolPB协议的代理对象,并在这个代理对象上调用RPC方法,代理对象会调用RPC.Client.call()方法将序列化之后的RPC请求发送到服务器。
Client发送请求与接收响应的流程图如下所示:Client类只有一个入口,即call()方法,代理类会调用Client.call()方法将RPC请求发送到远程服务器,然后等待远程服务器的响应。
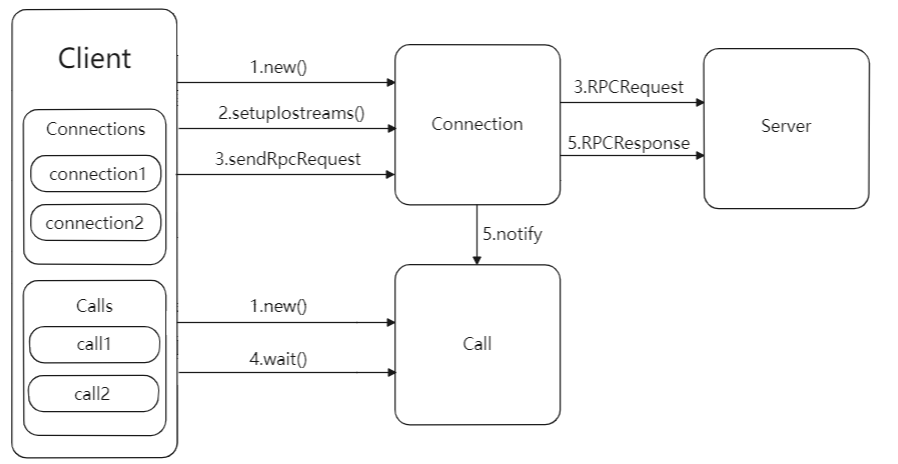
Client发送请求与接收响应的流程图如上所示:主要可以分为如下几个步骤:
- Client.call()方法将RPC请求封装成一个Call对象,其中保存了RPC调用的完成标志,返回值信息以及异常信息,然后call()方法会创建一个connection对象,用于管理client和server的socket连接。用ConnectionId作为key,将新建的Connection对象放入到Client.connections字段值保存,以callId作为key,将构造的Call对象放入Connection.calls字段中保存。
- Client.call()方法调用Connection.setupIOstreams()方法建立与server的socket连接,setupIOstreams()方法还会启动connection线程,这些线程会监听socket并读取server发回的响应信息。
- Client.call()方法调用Connection.sendRpcRequest()方法发送RPC请求到Server。
- Client.call()方法调用Call.wait()在Call对象上等待,等待server返回响应信息。
- Connection线程收到Server发回的响应信息,根据响应中的信息找到对应的call对象,然后设置Call对象的返回字段,并调用call.notify()唤醒Client.call()方法的线程读取Call对象的返回值。
RPC.Client中发送请求和接收响应的是由两个独立的线程进行的,发送请求线程就是调用Client.call()方法的线程,而接收响应线程则是call()启动的connect线程。
内部类Connection是一个线程类,提供建立Client到Server的Socket连接,发送RPC请求以及读取RPC响应信息等功能。Client与每个Server之间维护一个通信连接,与该连接相关的基本信息及操作被封装到Connection类中,基本信息主要包括通信连接唯一标识(remoteId)、与Server端通信的Socket(socket)、网络输入数据流(in)、网络输出数据流(out)、保存RPC请求的哈希表(calls)等。
Call类封装了一个RPC请求,它包含5个成员变量,分别是唯一标识id、函数调用信息param、函数执行返回值value、出错或者异常信息error和执行完成标识符done。由于Hadoop RPC Server采用异步方式处理客户端请求,这使远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用的。当客户端向服务器端发送请求时,只需填充id和param两个变量,而剩下的3个变量(value、error和done)则由服务器端根据函数执行情况填充。
3.3、Server类的实现
为了提高性能,Server类采用了很多技术提高并发能力,包括线程池,javaNIO提供的Reactor模式等。为了更好的理解Server类的设计,我们一步一步的推进:
3.3.1、Reactor模式
RPC服务端的处理流程和所有网络程序服务端处理的流程类似:1、读取请求;2、反序列化请求;3、处理请求;4、序列化响应;5、发回响应。
Reactor模式是一种广泛应用在服务器端的设计模式,也是一种基于事件驱动的设计模式;Reactor的处理流程是:应用程序向一个中间人注册IO事件,当中间人监听到这个IO时间发生后,会通知并唤醒应用程序处理这个事件,这里所说的中间人其实是一个不断等待和循环的线程,它接收所以的应用程序的注册,并肩擦应用程序注册的IO事件是否就绪,如果就绪了则通知应用程序进行处理。
一个简单的基于Reactor模式的网络服务器设计如下图所示:主要包括reactor、acceptor以及hadndler等模块,其中reactor负责监听所有的IO事件,当检测到一个新的IO事件发生时,reactor就睡唤醒这个事件对应的模块处理。acceptor负责响应socket连接请求事件,会接收请求建立连接,之后构造handler对象,handler负责向reactor注册IO读事件,然后进行对应的业务逻辑处理,最后发回响应。
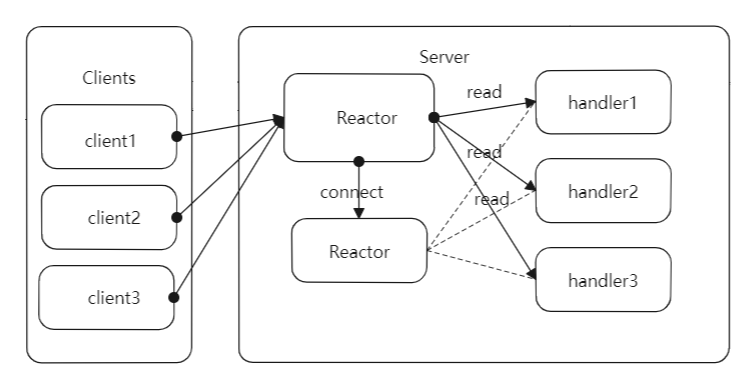
主要的步骤如下:
- 客户端发送socket连接请求到服务端,服务端的reactor对象监听到了这个IO请求,由于acceptor对象在reactor对象上注册了socket连接请求的iO事件,所以reactor会出发acceptor对象响应socket连接请求。
- acceptor对象会接收到来自客户端的socket连接请求,并为这个连接创建一个handler对象,handler对象的构造方法在reactor对象上注册IO读事件。
- 客户端建立连接后,会通过socket发送RPC请求,RPC请求达到reactor后,会有reactor对象分发到对应的handler对象处理。
- handler对象会从网络上读取RPC请求,然后反序列化请求并执行请求对应的逻辑,最后将响应信息序列化并通过socket发回给客户端。
由于上述的设计中服务端只有一个线程,所以就要求handler中读取请求、执行请求以及发送响应的流程必须能够迅速处理完成,如果在一个环节中发生了阻塞,则整个服务器逻辑全部阻塞。所以接下来看多线程的Reactor模式的网络服务器结构。
3.3.2、多线程的Reactor模式
在基础的Reactor模式的基础上,把占用时间比较长的读取请求部分也业务逻辑处理部分进行分开,交给两个独立的线程池处理,分别为readers的线程池和handler的线程池。readers线程池中包含若干个执行读取RPC请求任务的Reader线程。它们会在Reactor上注册读取RPC请求IO事件,然后从网络中读取RPC请求,并将RPC请求封装在一个Call对象中,最后将Call对象放入共享消息队列MQ中。而handers线程池包含很多个handler线程,它们会不断的从共享消息队列MQ中取出RPC请求,然后执行业务逻辑并向客户端发送响应。这样就保证了IO事件的监听和分发,RPC请求的读取和响应是在不同的线程中执行,大大提高了服务器的并发性能。具体的架构图如下:
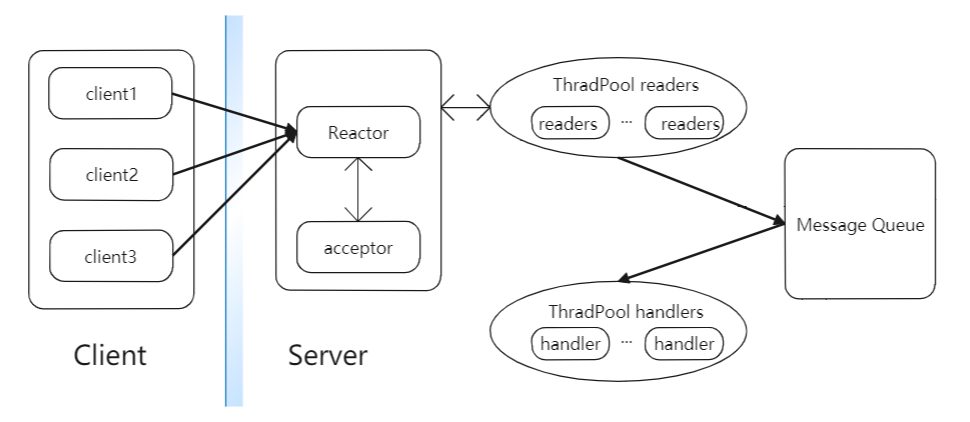
上图就是多线程的Reactor模式版本,IO事件的监听、RPC请求的读取和处理就可以并发的进行了,但是像hadoop的Namenode这样的对象,同一时间会存在很多个socket连接请求以及RPC请求的道道,这样就会造成Reactor在处理和分发这些IO事件时出现阻塞,导致服务器性能下降,在这个的基础上可以拓展为多个reactor的模式。
3.3.3、多个Reactor多线程模式
多个Reactor多线程模式结构如下图所示:
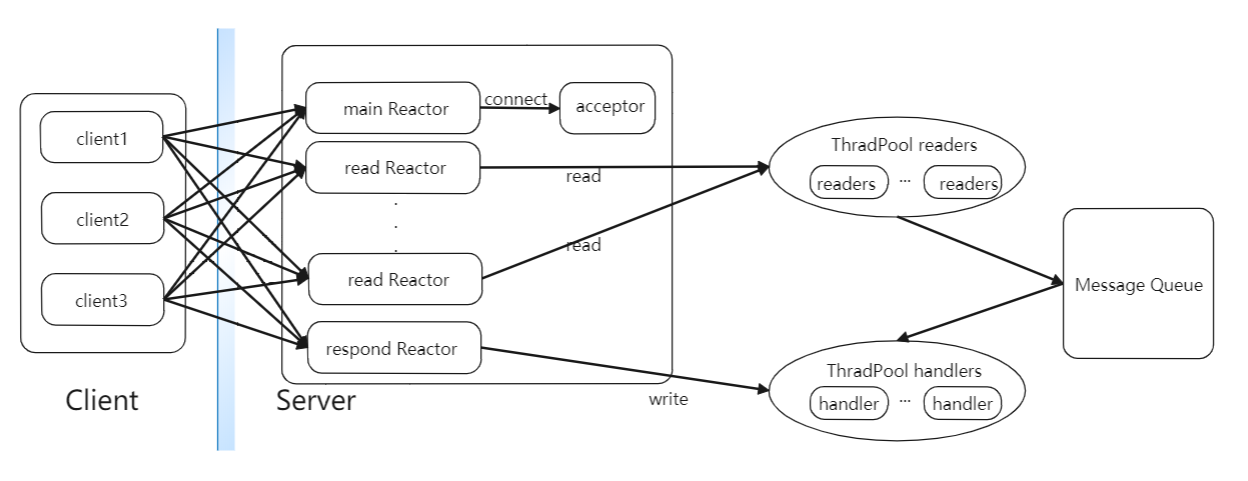
这里mainReactor负责监听socket连接事件,readReactor负责监听IO读事件,respondSelector负责监听IO写事件,这里会构造多个readReactor降低系统的负载,不同的Reader线程会根据一定的逻辑到不同的readReactor上注册IO读事件。当acceptor建立了socket连接后,会从readers线程池中取出一个reader线程去出发RPC请求的流程。Reader线程会根据一定的逻辑选出一个readReactor对象并在这个对象上注册读取RPC请求的IO事件。之后就会由该readReactor在网络监听是否有RPC请求到达,并出发Reader线程读取,当handler成功处理一个RPC请求后,就会向respondSelector注册写RPC响应IO事件,当socket输出流管道可以写数据时,sender类就可以将响应发送个客户端了。
3.3.4、server类的设计
server类的设计结构如下所示,基本和多个reactor多线程版本的设计模式类似。
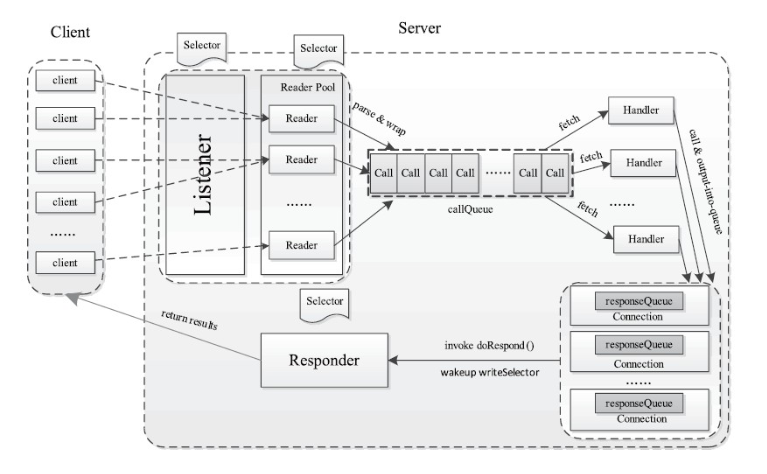
- Listener:类似于Reactor模式中的mainReactor,Listener对象中存在一个Selector对象acceptSelector,负责监听来自客户端的Socket请求,当acceptSelector监听到连接请求后,Listener对象会初始化这个连接,之后采用轮询的方式从readers线程池中选出一个reader线程处理RPC请求的读取操作。
- Reader:与Reactor模式中的Reader线程相同,用于RPC读取请求,Reader线程类中存在一个Selector对象readSelector,类似Reactor模式中的readReactor,这个对象用于监听网络中是否可以读取的RPC请求。当readSelector坚挺到有可读的RPC请求后,会唤醒Reader线程读取这个请求,并将请求封装在一个Call对象中,然后将这个Call对象放入CallQueue队列中。
- Handler:与Reactor模式中的Handler类似,用于处理RPC请求并发回响应,Handler对象会从CallQueue中不停的取出RPC请求,然后执行RPC请求对应的本地函数进行处理,最后封装响应发回给客户端。
- Responder:用于向客户端发送RPC响应,会在Responder内部的respondSelector上注册一个写响应事件,这里的respondSelector和Reactor中的respondSelector概念相同,当respondSelector坚挺到网络情况具备写响应的条件时,会通知Responder将剩余的响应发回给客户端
server类处理RPC请求的处理流程:
- Listener线程的acceptSelector在ServerSocketChannel上注册OP_ACCEPT事件,并且创建readers线程池,每个Reader的readSelector此时并不监控任何的Channel。
- Client发送socket连接请求,出发Listener的acceptSelector唤醒Listener线程。
- Listener调用ServerSocketChannel.accept()创建一个新的SocketChannel
- Listener从readers线程池中挑选一个线程,并在Reader的readSelector上注册OP_READ事件
- Client发送RPC请求数据报,出发Reader的selector唤醒Reader线程
- Reader从socketChannel中读取数据,封装成Call对象,然后放入共享对垒CallQueue中
- handlers线程池的线程都在CallQueue上阻塞,当有Call对象被放入后,其中一个Handler线程被唤醒,然后根据Call对象的信息滴哦用BlockingServer对象的callBlockingMethod()方法,然后Handler将响应写入SocketChannel中。
- 如果handler发现无法将响应完全写入到SocketChannel中,将在Responder的respondSelector上注册一个OP_WRITE时间,当socket恢复正常,Responder将被唤醒继续写响应。
Server类的内部类介绍:
- Listener类:是一个线程类,整个Server中只会有一个Listener线程,用于监听来自客户端的Socket连接请求,对于每一个新到达的socket连接请求,Listener都会从readers线程池中选择一个Reader线程处理,Listener中定义了一个Selector对象,负责监听SelectionKey.OP_ACCEPT事件。
- Reader类:是一个线程类,每个Reader线程都会负责读取若干个客户端连接发来的RPC请求,而在Server类中会存在多个Reader线程构成一个readers线程池,readers线程池并发的读取RPC请求,提高了Server处理RPC请求速度,Reader类定义了自己的readSelector字段,用于箭筒SelectionKey.OP_READ事件。
- Connection类:维护Server和Client之间的Socket连接,Reader线程会调用readAndProcess()方法从IO流中读取一个RPC请求
- Handler类:一个线程类,负责执行RPC请求对应的本地函数,然后将结果返回给客户端。Handler线程类的主方法会循环从共享队列CallQueue中取出待处理的Call对象,然后调用Server.call()方法执行RPC调用对应的本地函数。
- Responder类:一个线程类,一个Server中只有一个Responder对象,Responder内部包含一个Selector对象responseSelector,用于监听SelectionKey.OP_WRITE事件。responseSelector会循环监控网络环境中是否具备发送数据的条件,之后responseSelector会触发Responder线程发送未完成的响应结果到客户端。
3.4、基于RPC的优化
知道了RPC的原理后,下面的优化自然而然就懂了。
- Handler线程数目。在Hadoop中,ResourceManager和NameNode分别是YARN和HDFS两个子系统中的RPC Server,其对应的Handler数目分别由参数yarn.resourcemanager.resource-tracker.client.thread-count和dfs.namenode.service.handler.count指定,默认值分别为50和10,当集群规模较大时,这两个参数值会大大影响系统性能
- 客户端最大重试次数。在分布式环境下,因网络故障或者其他原因迫使客户端重试连接是很常见的,但尝试次数过多可能不利于对实时性要求较高的应用。客户端最大重试次数由参数ipc.client.connect.max.retries指定,默认值为10,也就是会连续尝试10次(每两次之间相隔1秒)
- 每个Handler线程对应的最大Call数目。由参数ipc.server.handler.queue.size指定,默认是100,也就是说,默认情况下,每个Handler线程对应的Call队列长度为100。比如,如果Handler数目为10,则整个Call队列(即共享队列callQueue)最大长度为:100×10=1000
- ipc.server.listen.queue.size控制了服务端socket的监听队列长度,即backlog长度,默认值是128。而Linux的参数net.core.somaxconn默认值同样为128。当服务端繁忙时,如NameNode,128是远远不够的。这样就需要增大backlog,例如3000台集群就将ipc.server.listen.queue.size设成了32768,为了使得整个参数达到预期效果,同样需要将kernel参数net.core.somaxconn设成一个大于等于32768的值。
参考:《Hadoop 2.x HDFS源码剖析》《Hadoop技术内幕 :深入解析YARN架构与实现原理》
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://blog.csdn.net/lemon89/article/details/17354887
对hadoop之RPC的理解的更多相关文章
- Hadoop的RPC通信原理
RPC调用: RPC(remote procedure call)远程过程调用: 不同java进程间的对象方法的调用. 一方称作服务端(server),一方称为客户端(client): server端 ...
- hadoop的RPC机制 -源码分析
这些天一直奔波于长沙和武汉之间,忙着腾讯的笔试.面试,以至于对hadoop RPC(Remote Procedure Call Protocol ,远程过程调用协议,它是一种通过网络从远程计算机程序上 ...
- Hadoop的RPC机制源码分析
分析对象: hadoop版本:hadoop 0.20.203.0 必备技术点: 1. 动态代理(参考 :http://www.cnblogs.com/sh425/p/6893662.html )2. ...
- 源码级强力分析hadoop的RPC机制
分析对象: hadoop版本:hadoop 0.20.203.0 必备技术点: 1. 动态代理(参考 :http://weixiaolu.iteye.com/blog/1477774 )2. Java ...
- Hadoop的RPC分析
一.基础知识 原理 http://www.cnblogs.com/edisonchou/p/4285817.html,这个谢了一些rpc与hadoop的例子. 用到了java的动态代理,服务端实现一个 ...
- Hadoop的RPC框架介绍
为什么会引入RPC: RPC采用客户机/服务器模式.请求程序就是一个客户机,而服务提供程序就是一个服务器.当我们讨论HDFS的,通信可能发生在: Client-NameNode之间,其中NameNod ...
- Hadoop之RPC
Hadoop的RPC主要是通过Java的动态代理(Dynamic Proxy)与反射(Reflect)实现,代理类是由java.lang.reflect.Proxy类在运行期时根据接口, ...
- Hadoop之RPC简单使用(远程过程调用协议)
一.RPC概述 RPC是指远程过程调用,也就是说两台不同的服务器(不受操作系统限制),一个应用部署在Linux-A上,一个应用部署在Windows-B或Linux-B上,若A想要调用B上的某个方法me ...
- Hadoop的RPC机制及简单实现
1.RPC简介 Remote Procedure Call 远程过程调用协议 RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些 ...
随机推荐
- MyEclipse 设置打开 jsp 文件的默认编辑器
MyEclipse 版本信息 MyEclipse Enterprise Workbench Version: 2014 Build id: 12.0.0-20131202 菜单 Window > ...
- QTree1 【题解】
题目背景 数据规模和spoj上有所不同 题目描述 给定一棵n个节点的树,有两个操作: CHANGE i ti 把第i条边的边权变成ti QUERY a b 输出从a到b的路径中最大的边权,当a=b的时 ...
- Mysql的Sql语句优化
在Mysql中执行Sql语句经常会遇到有的语句执行时间特别长的情况,出现了这种情况我们就需要静下心分析分析. 首先,我们需要确定系统中哪些语句执行时间比较长.这个可以使用Mysql的慢日志来跟踪.下面 ...
- JavaScript常用对象介绍
目录 对象(object) 对象的创建方式 点语法 括号表示法 内置对象 Array 数组创建方式 检测数组 转换方法 分割字符串 栈方法 队列方法 重排序方法 操作方法 位置方法 迭代方法 Stri ...
- Prometheus入门教程(二):Prometheus + Grafana实现可视化、告警
文章首发于[陈树义]公众号,点击跳转到原文:https://mp.weixin.qq.com/s/56S290p4j9KROB5uGRcGkQ Prometheus UI 提供了快速验证 PromQL ...
- 用Pycharm创建指定的Django版本
最近在学习胡阳老师(the5fire)的<Django企业级开发实战>,想要使用pycharm创建django项目时,在使用virtualenv创建虚拟环境后,在pycharm内,无论如何 ...
- C++ concurrent_queue
ConcurrentQueue 用C++11提供的多线程类实现一个线程安全的队列: #include <queue> #include <mutex> #include < ...
- cmake引入三方库
目录结构 . |-- cmake | |-- CompilerSettings.cmake | |-- Options.cmake | `-- ProjectJsonCpp.cmake |-- CMa ...
- go语言安装使用
go语言安装使用 下载地址 https://golang.google.cn/dl/ https://studygolang.com/dl windows https://studygolang.co ...
- swoft 事件监听和触发 打印sql日志
需求 打印出swoft的所有sql日志到控制台或者文件 只要打开listener 下面 Dbranlisten.php 里面最后一行注释即可,swoft已经帮我们实现好了 ____ _____ ___ ...