MapReduce案例二:好友推荐
1.需求
推荐好友的好友
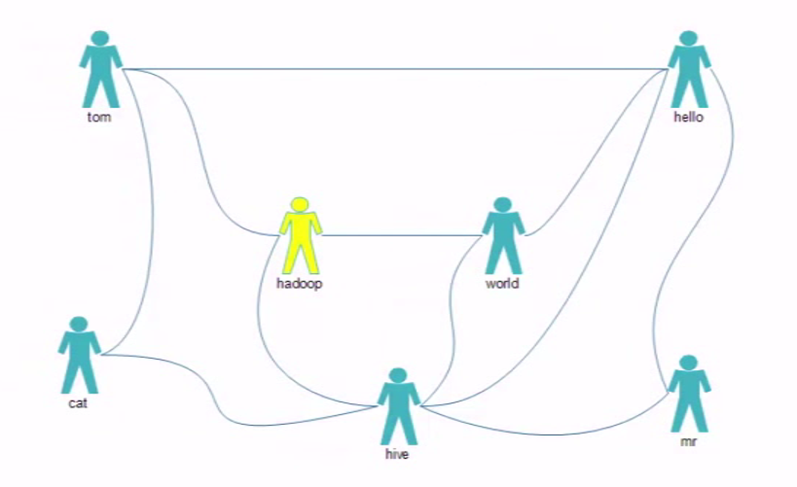
图1:


2.解决思路

3.代码
3.1MyFoF类代码
说明:
该类定义了所加载的配置,以及执行的map,reduce程序所需要加载运行的类
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyFoF { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//conf
Configuration conf = new Configuration(true); Job job=Job.getInstance(conf); job.setJarByClass(MyFoF.class); //map
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //map阶段的分区排序都使用默认的不用额外设置 job.setReducerClass(FReducer.class); //input ... output
Path input=new Path("/data/fof/input");
FileInputFormat.addInputPath(job, input); Path output=new Path("/data/fof/output");
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output);
}
FileOutputFormat.setOutputPath(job, output); //submit
job.waitForCompletion(true);
}
}
3.2FMapper类代码
说明:
该类的作用是编写map阶段的代码,对文本数据做一个预处理,按照规划比较每组的kv 做比较,这里面的k是偏移量longwritable类型,v是文本的字符串行 text类型。
代码逻辑:
1.双重for循环,外层循环比较直接关系,内层循环比较间接关系,最终map生成一个中间数据集,会有直接关系和间接关系。
2.将相同key的内容放在一起,交由reduce处理,如果是0代表为直接关系不作推荐,如果为1代表是间接关系,需要被推荐。
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey=new Text();
IntWritable mval=new IntWritable(); @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//tom hello hadoop cat String[] strs = StringUtils.split(value.toString(),' '); //双重for循环,外层循环比较直接关系,内层循环比较间接关系,最终map生成一个中间数据集,会有直接关系和间接关系,
//将相同key的内容放在一起,交由reduce处理,如果是0代表为直接关系不作推荐,如果为1代表是间接关系,需要被推荐。
for (int i = 0; i < strs.length; i++) {
mkey.set(getFoF(strs[0],strs[i]));
mval.set(0);
context.write(mkey, mval);
for (int j = i+1; j < strs.length; j++) {
mkey.set(getFoF(strs[i],strs[j]));
mval.set(1);
context.write(mkey, mval);
}
} } //定义一个比较方法如果前一个数s1小于后面一个数s2,就拼接为s1+s2,否则s2+s1
public static String getFoF(String s1,String s2){
if(s1.compareTo(s2)<0){
return s1+":"+s2;
}
return s2+":"+s1;
}
}
3.3FReducer类代码
说明:
该类的作用是对map的输出做进一步处理,两两出现的value不为0的相同key的value累加起来,将累加的结果赋给key
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable rval=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int flag=0;
int sum=0; //增加for循环迭代values
// hello:hadoop 0
// hello:hadoop 1
// hello:hadoop 0
for (IntWritable v : values) {
//如果获取到的values是0则将flag置为1,如果不为0则将所有的values叠加
if(v.get()==0){
flag=1;
}
sum+=v.get();
} //如果获取到的values不为0,就将相同key且values不为0的values叠加赋值给reduce中key中对应的值
if(flag==0){
rval.set(sum);
context.write(key, rval);
}
}
}
4.服务端执行
4.1创建文件输入目录
[root@node01 test]# hdfs dfs -mkdir -p /data/fof/input
4.2上传文件到hdfs
[root@node01 test]# cat fof.txt
tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr [root@node01 test]#hdfs dfs -put ./fof.txt /data/fof/input
4.3执行jar包
[root@node01 test]# hadoop jar ../jar_package/MyFOF.jar com.hadoop.mr.fof.MyFoF
4.4查看生成的输出文件
[root@node01 test]# hdfs dfs -ls /data/fof/output/
Found items
-rw-r--r-- root supergroup -- : /data/fof/output/_SUCCESS
-rw-r--r-- root supergroup -- : /data/fof/output/part-r-
[root@node01 test]# hdfs dfs -cat /data/fof/output/part-r-
cat:hadoop
cat:hello
cat:mr
cat:world
hadoop:hello
hadoop:mr
hive:tom
mr:tom
mr:world
tom:world
说明:通过图1可以发现
cat 和hadoop、hello都有2个共同的朋友tom、hive
cat和mr、world有1个共同的朋友hive
hadoop和hello有3个共同的朋友 tom、world、hive
hadoop和hive有1个共同的朋友world
hive和tom有3个共同的朋友cat、hadoop、hello
mr和tom有1个共同的朋友hello
mr和world有2个共同的朋友hello、hive
tom和world有2个共同的朋友hello、hadoop
5.报错解决
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /data/fof/output. Name)
这个异常表示hadoop处于安全状态,而你又对它进行了上传,修改,删除文件的操作。
刚启动完hadoop的时候,hadoop会进入安全模式,此时不能对hdfs进行上传,修改,删除文件的操作。
命令是用来查看当前hadoop安全模式的开关状态
hdfs dfsadmin -safemode get
命令是打开安全模式
hdfs dfsadmin -safemode enter
命令是离开安全模式
hdfs dfsadmin -safemode leave
离开安全模式再次执行即可。
MapReduce案例二:好友推荐的更多相关文章
- 【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 最应该推荐的好友TopN,如何排名 ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- MapReduce案例-好友推荐
用过各种社交平台(如QQ.微博.朋友网等等)的小伙伴应该都知道有一个叫 "可能认识" 或者 "好友推荐" 的功能(如下图).它的算法主要是根据你们之间的共同好友 ...
- MapReduce -- 好友推荐
MapReduce实现好友推荐: 张三的好友有王五.小红.赵六; 同样王五.小红.赵六的共同好友是张三; 在王五和小红不认识的前提下,可以通过张三互相认识,给王五推荐的好友为小红, 给小红推荐的好友是 ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- 19-hadoop-fof好友推荐
好友推荐的案例, 需要两个job, 第一个进行好友关系度计算, 第二个job将计算的关系进行推荐 1, fof关系类 package com.wenbronk.friend; import org.a ...
- 使用MapReduce实现二度人脉搜索算法
一,背景介绍 在新浪微博.人人网等社交网站上,为了使用户在网络上认识更多的朋友,社交网站往往提供类似“你可能感兴趣的人”.“间接关注推荐”等好友推荐的功能,其中就包含了二度人脉算法. 二,算法实现 原 ...
- Houdini学习笔记——【案例二】消散文字制作
[案例二]Houdini消散文字制作 一.Overview 文字通过时间轴中frame变化而碎裂从两边开始向着中间消散并向镜头移动. 效果 二.Sop(Surface OPerators or ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:qq好友推荐算法
实验目的 初步认识图计算的知识点 复习mapreduce的知识点,复习自定义排序分组的方法 学会设计mapreduce程序解决实际问题 实验原理 QQ好友推荐算法是所有推荐算法中思路最简单的,我们利用 ...
随机推荐
- angularJS新增 品优购新增品牌
前台代码 brand.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"&g ...
- Nginx反向代理两个tomcat服务器
第一步,在Linux上安装两个tomcat,修改好端口号后,启动起来. 第二步,配置本地的DNS解析,即修改host文件: 第三步,配置Nginx配置文件 反向代理的配置虚拟主机配置差不多也要配置虚拟 ...
- XML 树结构,语法规则,元素,属性,验证及其解析
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶". 一个 XML 文档实例 XML 文档使用简单的具有自我描述性的语法: <?xml v ...
- UIColor延伸:判断两个颜色是否相等
不管UIColor使用CIColor,CGColor还是其他方式初始化的,其CGColor属性都是可用的.CoreGraphics中提供一个函数,用于判断两个CGColor是否相等,因此我们可以通过这 ...
- HDU 4771 (DFS+BFS)
Problem Description Harry Potter has some precious. For example, his invisible robe, his wand and hi ...
- LoaderManager与CursorLoader用法
一.基本概念 1.LoaderManager LoaderManager用来负责管理与Activity或者Fragment联系起来的一个或多个Loaders对象. 每个Activity或者Fragme ...
- 二叉树系列 - [LeetCode] Symmetric Tree 判断二叉树是否对称,递归和非递归实现
Given a binary tree, check whether it is a mirror of itself (ie, symmetric around its center). For e ...
- Robotframework Web自动化实战课程
想学习的小伙伴,现在可以报名了!!!7月1日正式开课本期课程主要是web自动化为主,根据平时工作经验整理的一套流程以及使用过程中常见的问题总结.学完后能很快上手,即学即用,课后遇到问题在线解答,远程协 ...
- ES6 利用集合Set解决数组 交集 并集 差集的问题
根据阮一峰老师的ES6教程自己体会而写的,希望能给一些朋友有帮助到 let a = new Set([1,2,3,4]) let b = new Set([2,3,4,5,]) 并集 let unio ...
- Eclipse srever起来时,时间超过45s。
双击servere的名字,在属性界面上进行修改. 如下图: 修改TimeOut中的值即可.