Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
按我的理解,所谓Hive中的分桶,实际就是指的MapReduce中的分区。根据Reduce的数量,分成不同个数的文件。
我们以一个demo进行说明。
创建分桶表
drop table stu_buck;
create table stu_buck(id int, name string, score double)
clustered by(id) into 4 buckets
row format delimited
fields terminated by ',';
设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
我们从另外一个表student查询数据放到该表中,student中的表数据如下:

开始往创建的分桶表插入数据(插入数据需要是已分桶, 且排序的)
可以使用distribute by(id) sort by(id asc)
排序和分桶的字段相同的时候也可以使用Cluster by(字段)
注意使用cluster by 就等同于分桶+排序(sort)
可以尝试以下几种方式:
insert into table stu_buck
select id,name,score from student distribute by(id) sort by(id asc); insert overwrite table stu_buck
select id,name,score from student distribute by(id) sort by(id asc); insert overwrite table stu_buck
select id,name,score from student cluster by(id); insert overwrite table stu_buck
select id,name,score from student cluster by(id) sort by(id); 报错,cluster 和 sort 不能共存
效果:

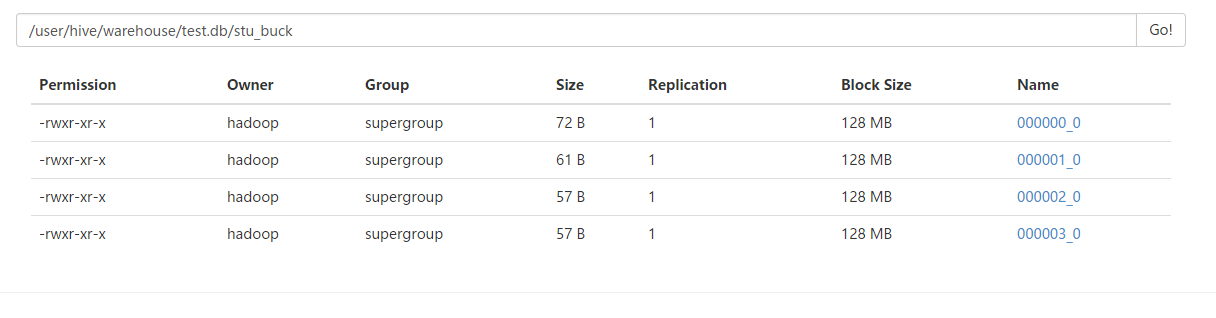
我们来查看以下文件的内容:
dfs -cat /user/hive/warehouse/test.db/stu_buck/000000_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000001_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000002_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000003_0;

注:1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
5、创建分桶表并不意味着load进数据也是分桶的,你必须先分好桶,然后再放到表中。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
分桶表的作用:最大的作用是用来提高join操作的效率;但是两者的分桶数要相同或者成倍数。
为什么可以提高join操作的效率呢?因为按照MapReduce的分区算法,是Id的HashCode值模上ReduceTaskNumbers,所以一个ID会分到同一个桶中,这样合并就不用整个表遍历求笛卡尔积了,对应的桶合并就可以了。
Hive学习笔记——Hive中的分桶的更多相关文章
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记-表操作
Hive数据类型 基本数据类型 tinyint,smallint,int,biging,float,double,decimal,char,varchar,string,binary,boolean, ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
随机推荐
- springMVC配置静态资源访问的<mvc:resources>标签的使用
在springmvc中,为了引用资源的访问不会类似Controller一样被拦截,区分出关注的资源的访问,一般我们在springMVC里面的拦截都会配置为"/",拦截所有的.但是这 ...
- My97DatePicker日历控件配置
一. 简介 1. 简介 目前的版本是:4.72 2. 注意事项 My97DatePicker目录是一个整体,不可破坏里面的目录结构,也不可对里面的文件改名,可以改目录名 My97DatePicker. ...
- 【Django】依赖auth.user的数据库迁移,以及admin用户非交互式创建
admin用户非交互式创建: echo "from django.contrib.auth.models import User; User.objects.create_superuser ...
- RocketMQ 拉取消息-文件获取
看完了上一篇的<RocketMQ 拉取消息-通信模块>,请求进入PullMessageProcessor中,接着 PullMessageProcessor.processRequest(f ...
- JVM性能监控工具(一)-jdk命令行工具
转载:http://blog.csdn.net/top_code/article/details/51456186 当系统出bug需要定位问题的时候,知识.经验是关键基础,数据是依据,工具是运用知识处 ...
- TestNG测试报告美化
因TestNG自带的测试报告不太美观,可以使用testng-xslt进行美化 1.下载testng-xslt包 2.把/src/main/resources/TestNG-results.xsl放到你 ...
- MSSQL数据库迁移到Oracle(二)
上一篇文章采用的PowerDesigner实现对MSSQL数据库迁移到Oracle,后来博友建议用ESF Database Migration Toolkit进行迁移会更加简单方便,本文就是通过一个实 ...
- eslint for...in 报错处理
示例代码: <!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF ...
- 数字图像和视频处理的基础-第4周运动预计matlab练习题
In this problem you will perform block matching motion estimation between two consecutive video fram ...
- Linux-查看C语言手册及man的特殊用法
man命令可以查看c语言库函数的函数原型, 比如 $ man malloc 如果显示 "No manual entry for malloc", 则需要安装 "man-p ...