zookeeper【2】集群管理
Zookeeper 的核心是广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播 模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后, 恢复模式就结束了。
状态同步保证了leader和Server具有相同的系统状态。为了保证事务的顺序一致性,zookeeper采用了递增的事务id号 (zxid)来标识事务。
所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用 来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递 增计数。
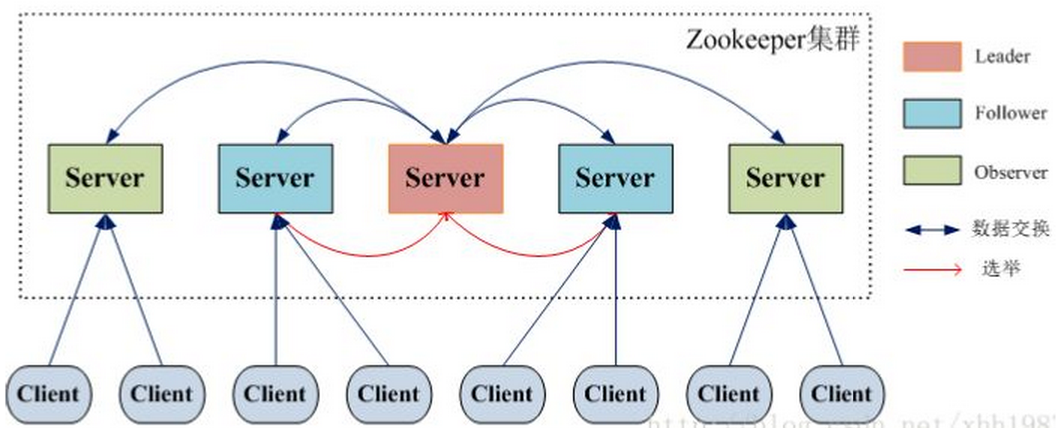
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
ZooKeeper的安装模式分为三种,分别为:单机模式、集群模式和集群伪分布模式
环境
CentOS7.0 (windows中使用就使用zkServer.cmd)
ZooKeeper最新版本
用root用户安装(如果用于hbase时将所有文件权限改为hadoop用户)
Java环境,最好是最新版本的。
分布式时多机间要确保能正常通讯,关闭防火墙或让涉及到的端口通过。
下载
去官网下载 :http://zookeeper.apache.org/releases.html#download
下载后放进CentOS中的/usr/local/ 文件夹中,并解压到当前文件中 /usr/local/zookeeper(怎么解压可参考之前的Haproxy的安装文章)
安装
单机模式
进入zookeeper目录下的conf子目录, 重命名 zoo_sample.cfg文件,Zookeeper 在启动时会找这个文件作为默认配置文件:
mv /usr/local/zookeeper/conf/zoo_sample.cfg zoo.cfg
配置zoo.cfg参数

# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
参数说明:
tickTime:毫秒值.这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataLogDir:顾名思义就是 Zookeeper 保存日志文件的目录
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
再创建上面配置的data和log文件夹:
mkdir /usr/local/zookeeper/data
mkdir /usr/local/zookeeper/log
启动zookeeper
先进入/usr/local/zookeeper文件夹
cd /usr/local/zookeeper
再运行
bin/zkServer.sh start
检测是否成功启动:执行
bin/zkCli.sh
或
echo stat|nc localhost 2181
伪集群模式
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例,模拟3台机。
将zookeeper的目录多拷贝2份:
zookeeper/conf/zoo.cfg文件与单机一样,只改为下面的内容:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
clientPort=2180
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
新增了几个参数, 其含义如下:
1 initLimit: zookeeper集群中的包含多台server, 其中一台为leader, 集群中其余的server为follower. initLimit参数配置初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s.
2 syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms.
3 server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 由于配置的是伪集群模式, 所以各个server的B, C参数必须不同.
参照zookeeper/conf/zoo.cfg, 配置zookeeper1/conf/zoo.cfg, 和zookeeper2/conf/zoo.cfg文件. 只需更改dataDir, dataLogDir, clientPort参数即可.在之前设置的dataDir中新建myid文件, 写入一个数字, 该数字表示这是第几号server. 该数字必须和zoo.cfg文件中的server.X中的X一一对应.
/usr/local/zookeeper/data/myid文件中写入0, /usr/local/zookeeper1/data/myid文件中写入1, /Users/apple/zookeeper2/data/myid文件中写入2.
分别进入/usr/local/zookeeper/bin, /usr/local/zookeeper1/bin, /usr/local/zookeeper2/bin三个目录, 启动server。启动方法与单机一致。
bin/zkServer.sh start
分别检测是否成功启动:执行
bin/zkCli.sh
或
echo stat|nc localhost 2181
集群模式
集群模式的配置和伪集群基本一致.
由于集群模式下, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样.
下面是一个示例:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
clientPort=2180
server.0=192.168.80.30:2888:3888
server.1=192.168.80.31:2888:3888
server.2=192.168.80.32:2888:3888
示例中部署了3台zookeeper server, 分别部署在192.168.80.30, 192.168.80.31, 192.168.80.32上.
需要注意的是, 各server的dataDir目录下的myid文件中的数字必须不同,192.168.80.30 server的myid为0, 192.168.80.31 server的myid为1, 192.168.80.32 server的myid为2
分别进入/usr/local/zookeeper/bin目录, 启动server。启动方法与单机一致。
bin/zkServer.sh start
分别检测是否成功启动:执行
bin/zkCli.sh
或
echo stat|nc localhost 2181
这时会报大量错误?其实没什么关系,因为现在集群只起了1台server,zookeeper服务器端起来会根据zoo.cfg的服务器列表发起选举leader的请求,因为连不上其他机器而报错,那么当我们起第二个zookeeper实例后,leader将会被选出,从而一致性服务开始可以使用,这是因为3台机器只要有2台可用就可以选出leader并且对外提供服务(2n+1台机器,可以容n台机器挂掉)。
ZooKeeper服务命令
1. 启动ZK服务: zkServer.sh start
2. 查看ZK服务状态: zkServer.sh status
3. 停止ZK服务: zkServer.sh stop
4. 重启ZK服务: zkServer.sh restart
zk客户端命令:
ZooKeeper 命令行工具类似于Linux的shell环境,使用它可以对ZooKeeper进行访问,数据创建,数据修改等操作.
使用 zkCli.sh -server 192.168.80.31:2181 连接到 ZooKeeper 服务,连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息。命令行工具的一些简单操作如下:
1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容
2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据
3. 创建文件,并设置初始内容: create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串
4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串
5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置
6. 删除文件: delete /zk 将刚才创建的 znode 删除
7. 退出客户端: quit
8. 帮助命令: help
zookeeper【2】集群管理的更多相关文章
- 一步到位分布式开发Zookeeper实现集群管理
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- zookeeper配置管理+集群管理实战
引言 之前就了解过kafka,看的似懂非懂,最近项目组中引入了kafka,刚好接着这个机会再次学习下. Kafka在很多公司被用作分布式高性能消息队列,kafka之前我只用过redis的list来做简 ...
- zookeeper安装和应用场合(名字,配置,锁,队列,集群管理)
安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个稳定版本为基础,最新的版本可以通过官网http://hadoop.apache.org/zookeeper/ 来获取,Zookee ...
- 2 weekend110的zookeeper的原理、特性、数据模型、节点、角色、顺序号、读写机制、保证、API接口、ACL、选举、 + 应用场景:统一命名服务、配置管理、集群管理、共享锁、队列管理
在hadoop生态圈里,很多地方都需zookeeper. 启动的时候,都是普通的server,但在启动过程中,通过一个特定的选举机制,选出一个leader. 只运行在一台服务器上,适合测试环境:Zoo ...
- 基于zookeeper+mesos+marathon的docker集群管理平台
参考文档: mesos:http://mesos.apache.org/ mesosphere社区版:https://github.com/mesosphere/open-docs mesospher ...
- 搞懂分布式技术5:Zookeeper的配置与集群管理实战
搞懂分布式技术5:Zookeeper的配置与集群管理实战 4.1 配置文件 ZooKeeper安装好之后,在安装目录的conf文件夹下可以找到一个名为“zoo_sample.cfg”的文件,是ZooK ...
- 【拆分版】Docker-compose构建Zookeeper集群管理Kafka集群
写在前边 在搭建Logstash多节点之前,想到就算先搭好Logstash启动会因为日志无法连接到Kafka Brokers而无限重试,所以这里先构建下Zookeeper集群管理的Kafka集群. 众 ...
- ZooKeeper之(五)集群管理
在一台机器上运营一个ZooKeeper实例,称之为单机(Standalone)模式.单机模式有个致命的缺陷,一旦唯一的实例挂了,依赖ZooKeeper的应用全得完蛋. 实际应用当中,一般都是采用集群模 ...
- 初始zookeeper与集群搭建实例
zookeeper是什么 Zookeeper,一种分布式应用的协作服务,是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务,它包含一个简单的原语集,应用于分布式应用的协作服务, ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
随机推荐
- OCP 12c最新考试原题及答案(071-3)
3.(4-10) choose the best answer:The user SCOTT who is the owner of ORDERS and ORDER_ITEMS tables iss ...
- php.ini中safe_mode开启之后对于PHP系统函数的影响
safe_mode是提供一个基本安全的共享环境. 在一个多用户共享的phpweb服务器上,当这台服务器开启了safe_mode模式,有以下函数将会受到影响. 首先,以下尝试访问文件系统的函数将会被限制 ...
- [ActionScript 3.0] 对数组中的元素进行排序Array.sort()的方法
对数组中的元素进行排序. 此方法按 Unicode 值排序. (ASCII 是 Unicode 的一个子集.) 默认情况下,Array.sort()按以下方式进行排序: 1. 排序区分大小写(Z优先于 ...
- 参照跟老男孩学linux运维搭建nagios实验小结
nagios效果示例 http://192.168.0.236/nagios 用户名:hong 密码:123 一. 服务端安装准备 1. 更新源 cd /etc/y ...
- PyQt5(4)——菜单栏(使用外部exe)
图像化建立菜单栏: ① 双击输入名称 就可以喽 如何添加工具栏呢: 新建一个快捷工具,拖到快捷栏,出现红色的小竖线. 至此 就完成了菜单栏和快捷方式的建立. 补充: python 如何调用外部的e ...
- python高级(二)—— python内置序列类型
本文主要内容 序列类型分类: (1)容器序列.扁平序列 (2)可变序列.不可变序列 列表推导式 生成器表达式 元组拆包 切片 排序(list.sort方法和sorted函数) bisect pytho ...
- Oracle批量插入数据SQL语句太长出错:无效的主机/绑定变量名
Oracle数据库,用mybatic批量插入数据: <insert id="saveBatch" parameterType="io.renren.entity.N ...
- Angular material mat-icon 资源参考_Images
ul,li>ol { margin-bottom: 0 } dt { font-weight: 700 } dd { margin: 0 1.5em 1.5em } img { height: ...
- Javascript 定时器的使用陷阱 (setInterval)
setTimeout(function(){ // 其他代码 setTimeout(arguments.callee, interval); }, interval); setInterval会产生回 ...
- python学习15-序列化(转载)
序列化是指把内存里的数据类型转换成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘和网络传输时只能接受bytes 一.pickle 把python对象写入到文件中的一种解决方案,但是写入到文件 ...