集群/分布式环境下,Session处理策略
前言
在搭建完集群环境后,不得不考虑的一个问题就是用户访问产生的session如何处理。如果不做任何处理的话,用户将出现频繁登录的现象。比如集中中存在A、B两台服务器,用户在第一次访问网站是,Nginx通过其负载均衡机制将用户请求转发到A服务器,这时A服务器就会给用户创建一个Session。当用户第二次发送请求时,Nginx将其负载均衡到B服务器,而这时候B服务器并不存在Session,所以就会将用户导航到登录页面。这样的话,肯定会大大降低用户的体验度,导致用户黏度下降。
我们应当对产生的Session进行处理,通过一些处理策略,来保证用户的体验度
下边,我将分析5中Session处理策略,并分析其优劣性。
第一种:粘性Session
原理:粘性Session是指将用户锁定到某一服务器上,比如上面讲的Demo,用户第一次请求时,Nginx将用户请求转发到了A服务器上,如果Nginx设置了粘性Session的话,那么用户以后的每次请求都会转发到A服务器。这样做,就相当于把用户和A服务器粘到了一起,这就是粘性的Session机制。
优点:简单,不需要对Session做任何处理
缺点:缺乏容错性,如果当前访问的服务器发生故障,用户被转移到第二个服务器上是,它的Session信息都将失效。
使用场景:发生故障后对客户产生的影响较小;服务器发生故障时小概率事件。
实现方式:以Nginx为例,在upstream模块配置ip_hash属性即可实现粘性Session。
upstream mycluster{
#这里添加的是上面启动好的两台Tomcat服务器
ip_hash;#粘性Session
server 192.168.22.229:8080 weight=1;
server 192.168.22.230:8080 weight=1;
}
第二种:服务器Session复制
原理:任何一个服务器上的Session发生改变(增删改),该节点会把这个Session的所有内容序列化,然后广播给所有其他节点,不管其他服务器需不需要Session,以此来保证Session同步。
优点:可容错,各个服务器间Session能够实时响应。
缺点:会对网络负荷造成一定压力,如果Session量大的话,可能会造成网络堵塞,拖慢服务器性能。
实现方式:
1、设置Tomcat,server.xml开启Tomcat集群功能

Address:填写本机IP即可,设置端口号,预防端口冲突。
2、在应用里增加信息:通知应用当前处于集群环境中,支持分布式。
在web.xml中添加选项:<distributable/>
第三种:Session共享
使用分布式缓存方案,比如memcached、Redis,但是要求Memcached或Redis必须是集群。
使用Session共享,也分为两种机制,如下:
1、粘性Session处理方式
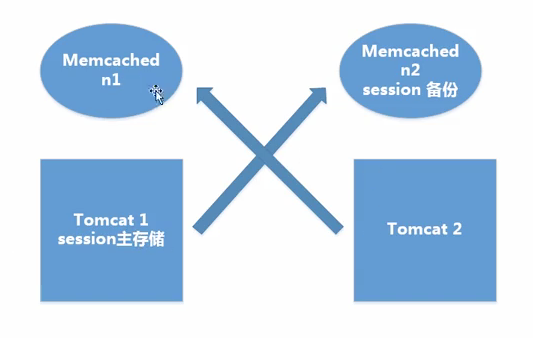
原理:不同的Tomcat指定访问不同的主memcached。多个memcached之间信息是同步的,能主从备份和高可用。用户访问时,首先在Tomcat中创建Session,然后将Session复制一份放到它对应的memcached上。memcached只起到备份左右,读写都在Tomcat上。当某一个Tomcat挂掉之后,集群将用户的访问定位到备Tomcat上,然后根据cookie中存储的SessionID找到Session,找不到时,再去相应的memcached上去寻找Session,找到之后将其复制到Tomcat上。
2、非粘性Session处理方式
原理:memcached做主从复制,写入Session在从memcached服务器上,读取Session从主memcached,Tomcat本身不存储Session。

优点:可容错,Session实时响应。
实现方式:用开源的msm插件解决Tomcat之间的Session共享:Memcached_Session_Manager(MSM)
a. 复制相关jar包到tomcat/lib 目录下
JAVA memcached客户端:spymemcached.jar
msm项目相关的jar包: 1. 核心包,memcached-session-manager-{version}.jar
2. Tomcat版本对应的jar包:memcached-session-manager-tc{tomcat-version}-{version}.jar
序列化工具包:可选kryo,javolution,xstream等,不设置时使用jdk默认序列化。
b. 配置Context.xml ,加入处理Session的Manager
粘性模式配置:

非粘性配置:

第四种:Session持久化到数据库
原理:拿一个数据库专门用来存储Session信息,保证Session的持久化。
优点:服务器出现问题,Session不会丢失。
缺点:如果网站的访问量很大,把Session存储到数据库中,会对数据库造成很大压力,还需要增加额外的开销,维护数据库。
第五种:Terracotta实现Session复制
原理:Terracotta的基本原理是对于集群间共享的数据,在当一个节点发生变化的时候,Terracotta只把变化的部分发送给Terracotta服务器,然后由服务器把它转发给真正需要这个数据的节点。这种方案可以看成是对第二种方案的优化。
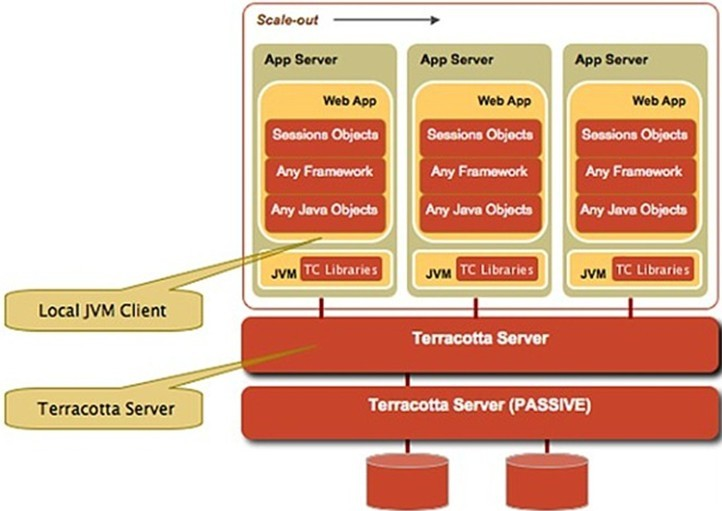
优点:这样对网络的压力非常小,各个节点也不必浪费CPU时间和内存进行大量的序列化操作。把这种集群间数据共享的机制应用在Session同步上,既避免了对数据库的依赖,又能达到负载均衡和灾难恢复的效果。
总结
以上就是在集群或者分布式环境下,Session处理的5中策略。其中就应用广泛性而言,第三种方式,也就是基于第三方缓存框架共享Session,应用的最为广泛,无论是效率还是扩展性都还可以。而Terracotta作为一个JVM级的开源集群框架,不仅仅提供HTTP Session复制,它还能做分布式缓存,POJO群集,跨越群集的JVM来实现分布式应用程序协调等。
原文地址:http://blog.csdn.net/u010028869/article/details/50773174
集群/分布式环境下,Session处理策略的更多相关文章
- 【架构师之路】集群/分布式环境下5种session处理策略
[架构师之路]集群/分布式环境下5种session处理策略 转自:http://www.cnblogs.com/jhli/p/6557929.html 在搭建完集群环境后,不得不考虑的一个问题就是 ...
- 集群/分布式环境下5种session处理策略
转载自:http://blog.csdn.net/u010028869/article/details/50773174?ref=myread 前言 在搭建完集群环境后,不得不考虑的一个问题就是用户访 ...
- 【转】集群/分布式环境下5种session处理策略
转载至:http://blog.csdn.net/u010028869/article/details/50773174 在搭建完集群环境后,不得不考虑的一个问题就是用户访问产生的session如何处 ...
- ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境 本文主要参考 给力星的博文——Hadoop集群安 ...
- Hadoop入门(五) Hadoop2.7.5集群分布式环境搭建
本文接上文内容继续: server01 192.168.8.118 jdk.www.fengshen157.com/ hadoop NameNode.DFSZKFailoverController(z ...
- Hadoop安装教程_集群/分布式配置
配置集群/分布式环境 集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slav ...
- 【转】分布式环境下5种session处理策略(大型网站技术架构:核心原理与案例分析 里面的方案)
前言 在搭建完集群环境后,不得不考虑的一个问题就是用户访问产生的session如何处理.如果不做任何处理的话,用户将出现频繁登录的现象,比如集群中存在A.B两台服务器,用户在第一次访问网站时,Ngin ...
- redis内存分配管理与集群环境下Session管理
##################内存管理############### 1.Redis的内存管理 .与memcache不同,没有实现自己的内存池 .在2..4以前,默认使用标准的内存分配函数(li ...
- redis 与java的连接 和集群环境下Session管理
redis 的安装与设置开机自启(https://www.cnblogs.com/zhulina-917/p/11746993.html) 第一步: a) 搭建环境 引入 jedis jar包 co ...
随机推荐
- maven更换下载镜像源-解决下载慢问题
Maven是当前流行的项目管理工具,但官方的库在国外经常连不上,连上也下载速度很慢.国内oschina的maven服务器很早之前就关了.今天发现阿里云的一个中央仓库,亲测可用. 1 <mirro ...
- javascript打开新页面的方法
方案一: A标签: 这里要注意target的设置,_Blank是指新窗口,也可以用js来模拟创建. <a href="http://www.cnblogs.com" targ ...
- 403.14-Forbidden Web 服务器被配置为不列出此目录的内容
第二次碰到这个问题了,记录一下 解决方案:1. 运行->cmd 2. cd C:\Windows\Microsoft.NET\Framework64\v4.0.30319 3. aspnet_ ...
- log4j.appender.AFile.File日志的相对路径
log4j.appender.AFile=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.AFile.DatePattern='.'yy ...
- 简单Trace类实现
<C++沉思录>27章内容修改后所得: /************************************************************************/ ...
- 安装Charles报错
去年用的是charles4.1.2版本,今年这个版本的安装包始终安装报错,不管公司电脑还是自己电脑........ 我的解决方案很Lower的.......... 登录Charles官网:https: ...
- 跨平台TTS eSpeak Windows开发
转摘请说明出处:http://www.cnblogs.com/luochengor/p/3511165.html以及作者,谢谢. eSpeak是最为流行的开源跨平台的文本转语音程序.这两天进行了简单的 ...
- cylance做的机器学习相关材料汇总
https://www.cylance.com/en_us/products/our-products/protect----threatzero.html 产品介绍 关键!!!! https://w ...
- 慕课网:4-2—— 使用DB facade实现CURD (09:11)
public function test1() { //新增数据: /* $bool=DB::insert('insert into student(name,age) VALUES (?,?)', ...
- dataGridView的使用经验
1.dataGridView是dataGrid的替代品,包含了dataGrid的全部功能. 2.为dataGridView赋值,一般将其数据设置为一个DataTabel.例子如下: DataTable ...