Python--urllib3库
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
1、 线程安全
2、 连接池
3、 客户端SSL/TLS验证
4、 文件分部编码上传
5、 协助处理重复请求和HTTP重定位
6、 支持压缩编码
7、 支持HTTP和SOCKS代理
8、 100%测试覆盖率
Urllib3功能非常强大,但是用起来却十分简单:

安装:
Urllib3 能通过pip来安装:
$pip install urllib3
你也可以在github上下载最新的源码,解压之后进行安装:
$git clone git://github.com/shazow/urllib3.git
$python setup.py install
urllib3的使用:
生成请求(request):
首先,你必须导入urllib3模块:

然后你需要一个PoolManager实例来生成请求,由该实例对象处理与线程池的连接以及线程安全的所有细节,不需要任何人为操作:

通过request()方法创建一个请求:

request()方法返回一个HTTPResponse对象。
你还可以通过request()方法向请求(request)中添加一些其他信息,如:

请求(request)中的数据项(request data)可包括:
Headers:
在request()方法中,可以定义一个字典类型(dictionary),并作为headers参数传入:
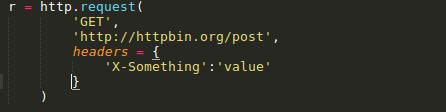
Query parameters:
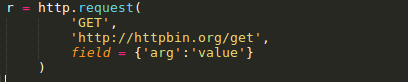
对于GET、HEAD和DELETE请求,可以简单的通过定义一个字典类型作为fields参数传入即可:
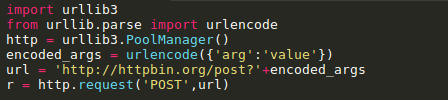
对于POST和PUT请求(request),需要手动对传入数据进行编码,然后加在URL之后:
Form data:
对于PUT和POST请求(request),urllib3会自动将字典类型的field参数编码成表格类型.
JSON:
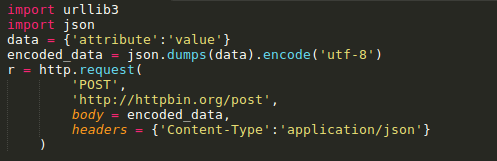
在发起请求时,可以通过定义body 参数并定义headers的Content-Type参数来发送一个已经过编译的JSON数据:
Files & binary data:
使用multipart/form-data编码方式上传文件,可以使用和传入Form data数据一样的方法进行,并将文件定义为一个元组的形式 (file_name,file_data):
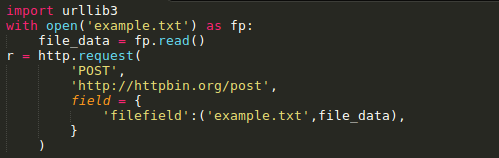
文件名(filename)的定义不是严格要求的,但是推荐使用,以使得表现得更像浏览器。同时,还可以向元组中再增加一个数据来定义文件的 MIME类型:
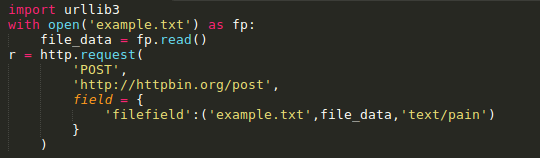
如果是发送原始二进制数据,只要将其定义为body参数即可。同时,建议对header的Content-Type参数进行设置:

Timeout :
使用timeout,可以控制请求的运行时间。在一些简单的应用中,可以将timeout参数设置为一个浮点数:

要进行更精细的控制,可以使用Timeout实例,将连接的timeout和读的timeout分开设置:

如果想让所有的request都遵循一个timeout,可以将timeout参数定义在PoolManager中:

或者

当在具体的request中再次定义timeout时,会覆盖PoolManager层面上的timeout。
请求重试(retrying requests):
Urllib3 可以自动重试幂等请求,原理和handles redirect一样。可以通过设置retries参数对重试进行控制。Urllib3默认进行3次请求重 试,并进行3次方向改变。
给retries参数定义一个整型来改变请求重试的次数:

关闭请求重试(retrying request)及重定向(redirect)只要将retries定义为False即可:

关闭重定向(redirect)但保持重试(retrying request),将redirect参数定义为False即可:

要进行更精细的控制,可以使用retry实例,通过该实例可以对请求的重试进行更精细的控制。
例如,进行3次请求重试,但是只进行2次重定向:

如果想让所有请求都遵循一个retry策略,可以在PoolManager中定义retry参数:

或者

当在具体的request中再次定义retry时,会覆盖 PoolManager层面上的retry。
Python--urllib3库的更多相关文章
- python常用库
本文由 伯乐在线 - 艾凌风 翻译,Namco 校稿.未经许可,禁止转载!英文出处:vinta.欢迎加入翻译组. Awesome Python ,这又是一个 Awesome XXX 系列的资源整理,由 ...
- Python Requests库:HTTP for Humans
Python标准库中用来处理HTTP的模块是urllib2,不过其中的API太零碎了,requests是更简单更人性化的第三方库. 用pip下载: pip install requests 或者git ...
- Python Requests库
背景 Requests is an elegant and simple HTTP library for Python, built for human beings. Requests是一个优雅简 ...
- 大概看了一天python request源码。写下python requests库发送 get,post请求大概过程。
python requests库发送请求时,比如get请求,大概过程. 一.发起get请求过程:调用requests.get(url,**kwargs)-->request('get', url ...
- Python常用库大全
环境管理 管理 Python 版本和环境的工具 p – 非常简单的交互式 python 版本管理工具. pyenv – 简单的 Python 版本管理工具. Vex – 可以在虚拟环境中执行命令. v ...
- python requests库学习笔记(上)
尊重博客园原创精神,请勿转载! requests库官方使用手册地址:http://www.python-requests.org/en/master/:中文使用手册地址:http://cn.pytho ...
- Python HTTP库requests中文页面乱码解决方案!
http://www.cnblogs.com/bitpeng/p/4748872.html Python中文乱码,是一个很大的坑,自己不知道在这里遇到多少问题了.还好通过自己不断的总结,现在遇到乱码的 ...
- python的库小全
环境管理 管理 Python 版本和环境的工具 p – 非常简单的交互式 python 版本管理工具. pyenv – 简单的 Python 版本管理工具. Vex – 可以在虚拟环境中执行命令. v ...
- 转--Python标准库之一句话概括
作者原文链接 想掌握Python标准库,读它的官方文档很重要.本文并非此文档的复制版,而是对每一个库的一句话概括以及它的主要函数,由此用什么库心里就会有数了. 文本处理 string: 提供了字符集: ...
- python 三方库
---------------- 这又是一个 Awesome XXX 系列的资源整理,由 vinta 发起和维护.内容包括:Web框架.网络爬虫.网络内容提取.模板引擎.数据库.数据可视化.图片处理. ...
随机推荐
- spark学习11(Wordcount程序-本地测试)
wordcount程序 文件wordcount.txt hello wujiadong hello spark hello hadoop hello python 程序示例 package wujia ...
- 怎么用Python提取域名中的主域名
从一个域名里面提取主域名,初想起来,貌似很简单,不就是数点[.]的个数吗?取最后一个点前后的字符串,那 abc.txt 是域名吗?那再加个验证,加上国家码,.com,.cn,.org结尾的才算,那这个 ...
- tomcat集群基于Nginx——共享同一个应用
1.首先准备两个tomcat,也可以一个复制两个.和一个Nginx tomcat官方下载连接——安装版&绿色版 Nginx官网下载链接:http://nginx.org/download/ 博 ...
- Rancher+K8S部署手册
目前创建K8S集群的安装程序最受欢迎的有Kops,Kubespray,kubeadm,rancher,以及个人提供的脚本集等. Kops和Kubespary在国外用的比较多,没有处理中国的网络问题,没 ...
- codevs 1017 乘积最大 dp
1017 乘积最大 时间限制: 1 s 空间限制: 128000 KB 题目描述 Description 今年是国际数学联盟确定的“2000——世界数学年”,又恰逢我国著名数学家华罗庚 ...
- 谈谈你对Glide和Picasso他们的对比的优缺点
1.Picasso和Glide的withi后面的参数不同 Picasso.with(这里只能传入上下文) . Glide.with,后面可以传入上下文,activity实例,FragmentA ...
- selenium学习笔记(HTMLTestRunner测试报告)
之前提到selenium加入unittest框架.可以引入HTMLTestRunner扩展.以此来生成测试报告 首先是分享下载的百度云地址 http://pan.baidu.com/s/1pKUItW ...
- scrapy框架解读--深入理解爬虫原理
scrapy框架结构图: 组成部分介绍: Scrapy Engine: 负责组件之间数据的流转,当某个动作发生时触发事件 Scheduler: 接收requests,并把他们入队,以便后续的调度 Do ...
- 交换机上的trunk,hybrid,access配置和应用(转)
交换机上的trunk,hybrid,access配置和应用 以太网端口的链路类型: Access类型:端口只能属于一个vlan,一般用于连接计算机. Trunk类型:端口可以属于端个vlan,可以接收 ...
- [转]linux将一个服务器上的文件或者文件夹复制到另一台服务器上
本文转载自<linux 将一个服务器上的文件或者文件夹复制到另一台服务器上>,有时间实践一把 使用scp将一个Linux系统中的文件或文件夹复制到另一台Linux服务器上 复制文件或文件夹 ...