scrapy框架解读--深入理解爬虫原理

scrapy框架结构图:
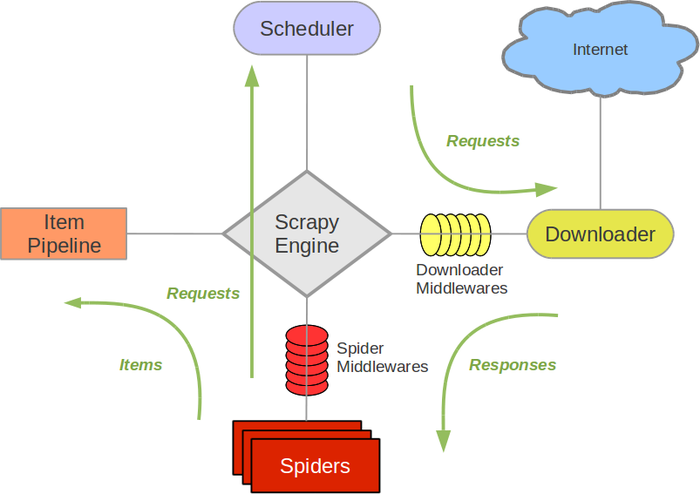
组成部分介绍:
Scrapy Engine:
负责组件之间数据的流转,当某个动作发生时触发事件Scheduler:
接收requests,并把他们入队,以便后续的调度Downloader:
负责抓取网页,并传送给引擎,之后抓取结果将传给spiderSpiders:
用户编写的可定制化的部分,负责解析response,产生items和URLItem Pipeline:
负责处理item,典型的用途:清洗、验证、持久化Downloader middlewares:
位于引擎和下载器之间的一个钩子,处理传送到下载器的requests和传送到引擎的response(若需要在Requests到达Downloader之前或者是responses到达spiders之前做一些预处理,可以使用该中间件来完成)Spider middlewares:
位于引擎和抓取器之间的一个钩子,处理抓取器的输入和输出
(在spiders产生的Items到达Item Pipeline之前做一些预处理或response到达spider之前做一些处理)
Scrapy中的数据流:
- Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的spider,并向该spider请求第一个要爬取的url(s);
- 引擎从spider中获取到第一个要爬取的url并在调度器(scheduler)以requests调度;
- 引擎向调度器请求下一个要爬取的url;
- 调度器返回下一个要爬取的url给引擎,引擎将url通过下载器中间件(请求requests方向)转发给下载器(Downloader);
- 一旦页面下载完毕,下载器生成一个该页面的responses,并将其通过下载器中间件(返回responses方向)发送给引擎;
- 引擎从下载器中接收到responses并通过spider中间件(输入方向)发送给spider处理;
- spider处理responses并返回爬取到的Item及(跟进的)新的resquests给引擎
- 引擎将(spider返回的)爬取到的Item给Item Pipeline,将(spider返回的)requests给调度器;
- (从第二部)重复直到(调度器中没有更多的request)引擎关闭该网站
中间件的编写:
down loader middle ware – 查看文档151页
spider middle wares – 查看文档162页
scrapy框架解读--深入理解爬虫原理的更多相关文章
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- Scrapy框架解读
1. Scrapy组件a. 主体部分i. 引擎(Scrapy):处理整个系统的数据流处理,触发事务(框架核心)ii. 调度器(Scheduler):1) 用来接受引擎发过来的请求, 压入队列中, 并在 ...
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 网络爬虫第五章之Scrapy框架
第一节:Scrapy框架架构 Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- python高级之scrapy框架
目录: 爬虫性能原理 scrapy框架解析 一.爬虫性能原理 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 1.同步执行 impor ...
- 都是干货---真正的了解scrapy框架
去重规则 在爬虫应用中,我们可以在request对象中设置参数dont_filter = True 来阻止去重.而scrapy框架中是默认去重的,那内部是如何去重的. from scrapy.dupe ...
随机推荐
- http://element.eleme.io/#/zh-CN/component/quickstart
http://element.eleme.io/#/zh-CN/component/quickstart
- 常用的SQLalchemy 字段类型
https://blog.csdn.net/weixin_41896508/article/details/80772238 常用的SQLAlchemy字段类型 类型名 python中类型 说明 In ...
- Runtime Error! R6025-pure virtual function call 问题怎么解决
一.故障现象:1.360软件的木马查杀.漏洞修复等组件不能使用,提示runtime error2.暴风影音等很多软件不能正常使用3.设备管理器不能打开,提示“MMC 不能打开文件”4.部分https安 ...
- javaweb项目中嵌入webservice--axis2
由于最近项目中需要搭建webservice服务端,由于原项目是javaweb项目,所以需要整合.之前用cxf试了,启动老是报错,maven依赖冲突.后来索性换成axis2 百度了一圈,下面这个博客 h ...
- window7安装MongoDB详细步骤
1.下载安装包 下载地址:https://www.mongodb.com/download-center/community 2.鼠标右击安装包,进行安装 3.选自定义安装 4.千万不要勾选 5.打开 ...
- 设置EditText明文切换
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/mingyue_1128/article/details/37651793 if (!isChecke ...
- 购物单问题—WPS使用excel
**** 180.90 88折 **** 10.25 65折 **** 56.14 9折 **** 104.65 ...
- iptables练习题(四)
设有一台Linux服务器,利用iptables作为防火墙,要求新建一条名为MYCHAIN的新链,来实现只允许开放本机的http服务,其余协议和端口均拒绝. 脚本: [root@miyan ~]# ca ...
- linux安装tree命令
安装 yum install -y tree 使用,比如显示/root的2层树结构 tree -L 2 /root 效果 /root ├── \033 ├── code │ └── hellowo ...
- [StringUtil ] isEmpty VS isBlank
昨天才意识到这两个的存在. Blank(空字符串 blank) StringUtils.isNoneBlank(null) = false StringUtils.isNoneBlank(null, ...