ICML 2017-Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Key
Gradient Descent+TRPO+policy Gradient
训练模型的初始参数,模型在新任务上只需参数通过一个或多个用新任务的少量数据计算的梯度步骤更新后,就可以最大的性能。而不是通过大量的新任务重新学习,而是调整学习。
解决的主要问题
- 想要让系统能够快速学习,尽快适应新任务
文章内容
Introduction
人工智能需要快速学习,才更像人类的智力。之前元学习方法:学习更新功能或学习规则;本文提出的算法不会扩展学习参数的数量,也不会对模型架构施加约束(通过要求循环模型或Siamese网络)
两种理解方式:- 特征学习角度:通过梯度训练参数,其实是在构建一个广泛适用于许多任务的内部表示。如果内部表示适合许多任务,简单地微调参数(例如,主要修改前馈模型的顶层权重)可以产生良好的结果。
- 动态系统角度:本文的学习过程可以被视为最大化新任务的损失函数相对于参数的灵敏度:当灵敏度很高时,对参数的小的局部变化可以导致任务损失的大幅度改善
Model-Agnostic Meta-Learning
set-up
aim:model f(观测x到输出a的映射)
每个任务由四部分表示(由损失函数,初始观测分布,过渡分布,和episode长度)
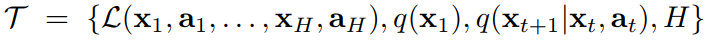
- 训练:从任务分布中采样task,交互k次,计算task下的loss梯度,更新当前task的参数。batch tasks分别计算和更新完后,即完成了第一次梯度更新。
最后根据累计loss的梯度来更新model参数。注意:此处是根据第一次梯度更新得到的参数来计算each task的loss,从而计算第二次梯度更新。
文章中解释为:采样任务上的测试误差充当元学习过程的训练误差。即第二次梯度计算利用的loss为每个task的test error,并利用该损失进一步更新参数θ
理解:即θ'为task更新后的参数,想要测试该θ'的效果,需要测试,即在new task上用θ'的loss来作为测试误差。
注意:训练objective:使得采样tasks的累计loss的梯度minimize - 测试:从任务分布中采样新任务,在K个样本中学习后的model表现来衡量模型的性能
- 训练:从任务分布中采样task,交互k次,计算task下的loss梯度,更新当前task的参数。batch tasks分别计算和更新完后,即完成了第一次梯度更新。
MAML Algorithm

Species of MAML
分别讲述了小样本学习和强化学习。
这里主要讲述RL:
f为状态xt在each t对应的at概率分布,设置each task的loss:
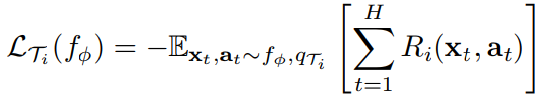
注意:由于政策梯度是一种on-policy算法,在fθ适应过程中,每一个额外的梯度步骤都需要来自当前政策fθi'的新样本。

Experimental evaluation
problem:
是否能够快速学习适应新任务
是否适用于不同的领域domains
用MAML学习的模型可以通过额外的梯度更新 和/或 示例继续改进吗文章实验分别在回归、分类、RL领域进行了实验。
RL:- 在2D Navigation和Locomotion环境中进行实验,利用vanilla策略梯度(REINFORCE)进行梯度更新的计算;使用信任区域策略优化(TRPO)作为元优化器
- 为了避免TRPO三次导数,使用有限差分计算TRPO的Hessian-vector
- 对于learning和meta-learning更新,使用标准线性特征基线,在批次中每个采样任务的每个迭代中分别拟合。并且与三个基线进行比较(pretraining one policy,andomly initialized weights,oracle policy)
Discussion and Future Work
使大容量可伸缩模型(如深度神经网络)能够通过小数据集快速训练的关键因素是 重用来自过去任务的知识。
未来:进行使多任务初始化成为深度学习和强化学习的标准成分
文章方法的优缺点
- 优点
- 加速了使用神经网络策略的策略梯度强化学习的微调
- 只需最小的修改,就可以轻松地处理不同的架构和不同的问题设置,包括分类、回归和策略梯度强化学习。
- 没有引入任何学习参数,不会扩展学习参数的数量,也不会对模型架构施加约束
- 缺点
- 在MAML用于RL中,由于PG是on-policy,每次task训练需要根据更新前后的参数分别进行两次样本采样。
- 需要知道任务分布,才能进行采样。
Summary
该文章不再像之前基于RNN的meta-RL思想,按照该文章的理解,那是在给模型架构施加约束条件。然而,此次的方法不需要任何架构和参数的改变,只是调整了参数更新的方式。
通过利用采样到的每个task根据loss更新到的单个task的参数,来再次计算新参数下的task loss。最后根据累计的新参数loss总和进行model参数的更新。
我理解是最后使得model参数让每个任务的loss最小,这样就能快速适应新任务。因为任务分布内的task是相近的,即有共同特点,model参数是融合了tasks相似的特点。利用训练模型的参数,在适应新任务的时候,就可以只需要少量的梯度更新。
论文链接
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权
ICML 2017-Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks的更多相关文章
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks ICML 2017 Paper:https://arxiv.org/ ...
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks(用于深度网络快速适应的元学习)
摘要:我们提出了一种不依赖模型的元学习算法,它与任何梯度下降训练的模型兼容,适用于各种不同的学习问题,包括分类.回归和强化学习.元学习的目标是在各种学习任务上训练一个模型,这样它只需要少量的训练样本就 ...
- 深度学习材料:从感知机到深度网络A Deep Learning Tutorial: From Perceptrons to Deep Networks
In recent years, there’s been a resurgence in the field of Artificial Intelligence. It’s spread beyo ...
- (转)Paper list of Meta Learning/ Learning to Learn/ One Shot Learning/ Lifelong Learning
Meta Learning/ Learning to Learn/ One Shot Learning/ Lifelong Learning 2018-08-03 19:16:56 本文转自:http ...
- 什么是 Meta Learning / Learning to Learn ?
Learning to Learn Chelsea Finn Jul 18, 2017 A key aspect of intelligence is versatility – the cap ...
- The Rise of Meta Learning
The Rise of Meta Learning 2019-10-18 06:48:37 This blog is from: https://towardsdatascience.com/the- ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 【MetaPruning】2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning-论文阅读
MetaPruning 2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning Zechun ...
- [转载]Meta Learning单排小教学
原文链接:Meta Learning单排小教学 虽然Meta Learning现在已经非常火了,但是还有很多小伙伴对于Meta Learning不是特别理解.考虑到我的这个AI游乐场将充斥着Meta ...
随机推荐
- Hyperf安装
转载网址: https://www.cnblogs.com/lyc94620/p/12821723.html
- 开学考--MIS系统(javaweb的开学练习--网络新闻发布系统)
关于本次考试的相关理解 看到题目的时候,第一反应是这道题不难,之前已经做过十分类似的题目了,然后对于难度是很有自信的(当然,对于用户的权限管理部分,还是很懵): 而第二反应就是,题量挺大的,我在这有限 ...
- buildroot交叉编译ros过程中遇到的问题
问题:Download error on https://pypi.python.org/simple/python-dateutil/:unknown url type:https --Some p ...
- BeautifulSoup模块的使用方法
本篇文章主要讲bs4模块(BeautifulSoup),这个模块能做么呢?用一句话来概括的话:beautifulsoup4 从HTML或XML文件中提取数据的Python库,用它来解析爬取回来的xml ...
- MySQL 数据库死锁问题
在分析案例之前,我们先了解一下MySQL INNODB.在MySQL INNODB引擎中主键是采用聚簇索引的形式,即在B树的叶子节点中既存储了索引值也存储了数据记录,即数据记录和主键索引是存在一起的. ...
- 机器学习基础04DAY
scikit-learn数据集 我们将介绍sklearn中的数据集类,模块包括用于加载数据集的实用程序,包括加载和获取流行参考数据集的方法.它还具有一些人工数据生成器. sklearn.dataset ...
- VUE零碎小技巧1
1.回顾 创建项目 vue create myapp 准备 scss 库 修改了页面的主结构 App.vue 构建页面的基本结构 分离页面主结构,创建各个页面组件 views views/home/i ...
- Python常见面试题016. 请实现如下功能|谈谈你对闭包的理解
016. 请实现如下功能|谈谈你对闭包的理解 摘自<流畅的python> 第七章 函数装饰器和闭包 实现一个函数(可以不是函数)avg,计算不断增加的系列值的平均值,效果如下 def av ...
- 对抗 ChatGPT,免费体验 Claude
对抗 ChatGPT,免费体验 Claude Claude 是 Anthropic 构建的大型语言模型(LLM),对标ChatGPT. Anthropic 创始团队多是前openai研究员和工程师,C ...
- Semantic Kernel 入门系列:📅 Planner 计划管理
Semantic Kernel 的一个核心能力就是实现"目标导向"的AI应用. 目标导向 "目标导向"听起来是一个比较高大的词,但是却是实际生活中我们处理问题的 ...