慢查询SQL排查
转载请注明出处️
作者:测试蔡坨坨
原文链接:caituotuo.top/c56bd0c5.html
你好,我是测试蔡坨坨。
在往期文章中,我们聊过数据库基础知识,可参考「数据库基础,看完这篇就够了!」。
学完数据库基础知识,要想更深入地了解数据库,就需要学习数据库进阶知识,今天我们就先来聊一聊慢SQL查询那些事儿。
在日常工作中,我们经常会遇到数据库慢查询问题,那么我们要如何进行排查呢?
假设一次执行20条SQL,我们如何判断哪条SQL是执行慢的烂SQL,这里就需要用到慢查询日志。
在SQL中,广义的查询就是CRUD操作,而狭义的查询仅仅是SELECT查询操作,而我们所说的慢查询其实指的是广义的查询,包括增删改查,一般是查询,所以称为慢查询。
什么是慢查询日志
MySQL提供的一种日志记录,用于记录MySQL中响应时间超过阈值[yù zhí]的SQL语句(也就是long_query_time的值,默认时间是10秒)。
慢查询日志默认是关闭的,开启会消耗一定的性能,一般是开发调优时打开,而部署时会关闭。
检查是否开启了慢查询日志
执行语句:
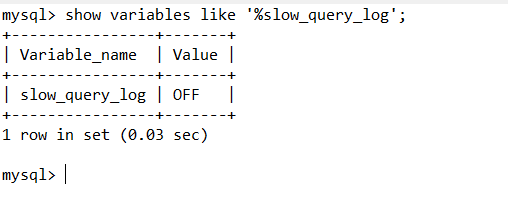
show variables like '%slow_query_log';
从以下执行结果可以看出,慢查询日志默认是OFF关闭状态:
如何开启慢查询日志
开启慢查询日志有两种方式,分别是临时开启和永久开启。
临时开启
一般使用临时开启,即在内存中开启,MySQL退出就会自动关闭,从而避免过多的性能开销:
set global slow_query_log = 1; // 1表示开启
set global slow_query_log_file="D:/MySQL Server 5.5/slow_query_log.log"; // 日志存储位置

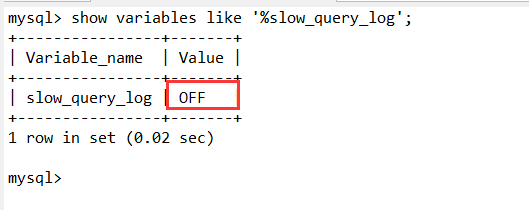
临时开启,重启MySQL服务后慢查询日志会变成OFF状态:
Linux重启MySQL服务:
service mysql restart
Windows重启MySQL服务:
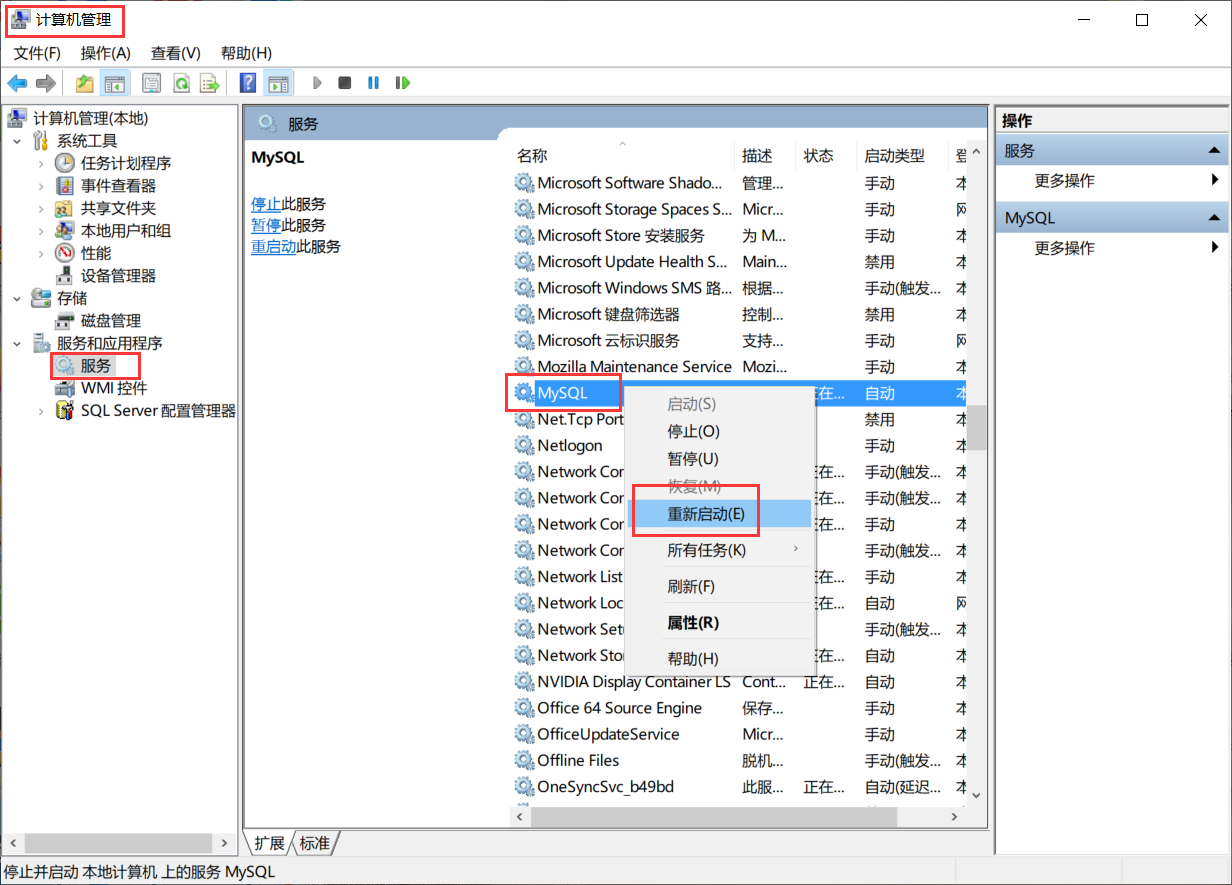
右击开始菜单——计算机管理——找到MySQL服务——重启:
重启后的可以看到慢查询日志变成OFF关闭状态:
永久开启
通过修改配置文件的方式可以永久开启慢查询日志。
Linux:在 /etc/my.cnf 中追加配置
vi /etc/my.cnf
[mysqld]
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow-query-log.log
Windows:D:\MySQL Server 5.5\my.ini
[mysqld]
slow_query_log=1
slow_query_log_file="D:/MySQL Server 5.5/slow_query_log.log"
永久开启后,即使重启MySQL服务,慢查询日志也不会关闭:

慢查询阈值修改
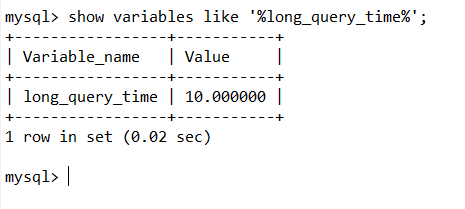
查看默认值
show variables like '%long_query_time%';
可以看到默认值是10s:
临时设置阈值
设置完毕后,需要重新登录MySQL才能生效(注意是重新登录MySQL,不是重启MySQL服务)。
set global long_query_time = 5;

永久设置阈值
通过修改配置文件的方式可以永久设置阈值(修改完成后需要重启MySQL服务):
[mysqld]
long_query_time=3

慢SQL排查测试
模拟慢SQL数据
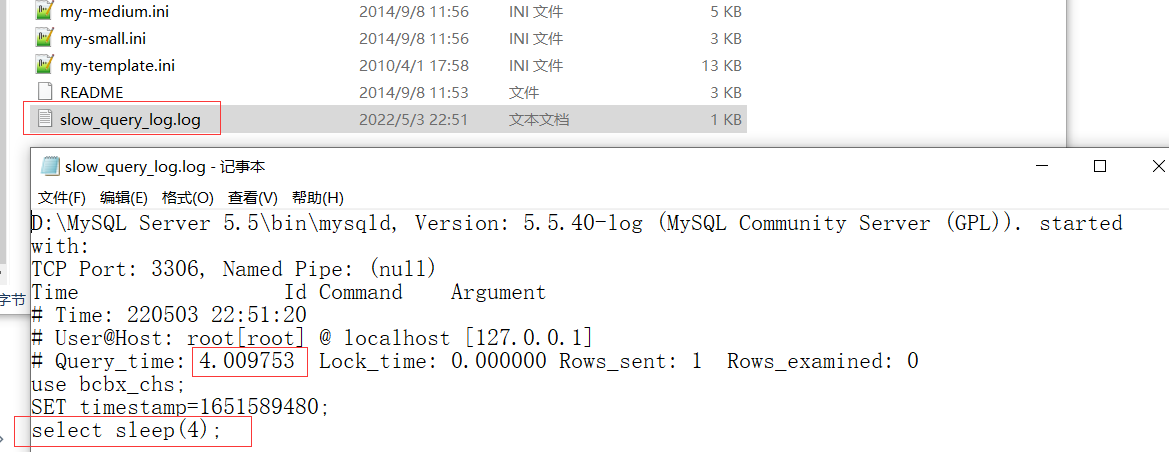
执行如下SQL语句休眠4秒,模拟慢SQL:
select sleep(4);
查询超过阈值的SQL的数量:
show global status like '%slow_queries%';
可以看到超过阈值的SQL数为1:

查询超过阈值的具体SQL语句
主要有两种方式可以定位到具体的慢SQL语句,分别为查看日志文件和使用mysqldumpslow工具查看。
方式一:通过查看日志文件,也就是前面设置的slow_query_log_file
方式二:通过mysqldumpslow工具快速定位慢SQL
假设执行了1000条SQL,其中有30条SQL都超过了阈值,如果直接查看日志文件,无法快速定位到具体的SQL,所以需要使用mysqldumpslow工具,通过一些过滤条件,快速查找出慢SQL。
Linux:
mysqldumpslow命令
--help命令查看帮助文档:
mysqldumpslow --help
-s ORDER排序 what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count(访问次数)
l: lock time(锁的时间)
r: rows sent(返回的记录数)
t: query time(查询时间)
-r:逆序 reverse the sort order (largest last instead of first)
-l:锁定时间 don't subtract lock time from total time
-g:后面跟一个正则匹配模式,大小写不敏感
-t:top n,即为返回前面多少条的数据
举栗:
获取返回记录最多的3个SQL
mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow-query-log.log
获取访问次数最多的3个SQL
mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow-query-log.log
按照时间排序,前10条包含left join查询语句的SQL
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/localhost-slow-query-log.log
Windows:
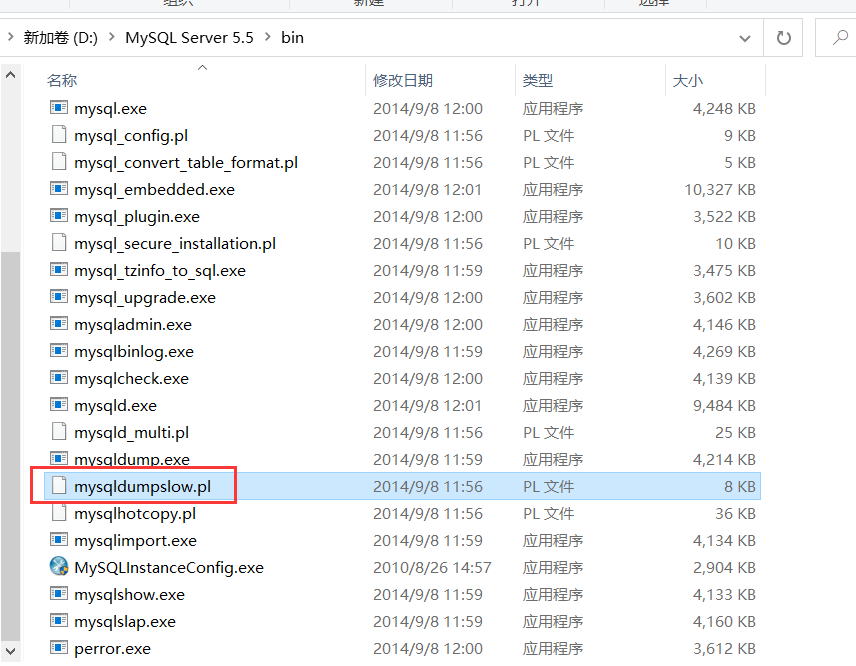
MySQL安装后以后在bin下有mysqldumpslow.pl文件,如果没有可以自行下载。
D:\MySQL Server 5.5\bin\mysqldumpslow.pl:
mysqldumpslow是一个perl脚本,要想在Windows执行,首先需要安装Perl。
安装过程比较简单,从官网 http://strawberryperl.com/ 下载windows安装包,安装完成后通过perl -v命令测试是否安装成功,如果能显示版本号,表示安装成功。
百度网盘:
链接:https://pan.baidu.com/s/1MiJ3FNUGEoSE1U6dJzOsAg
提取码:slt7
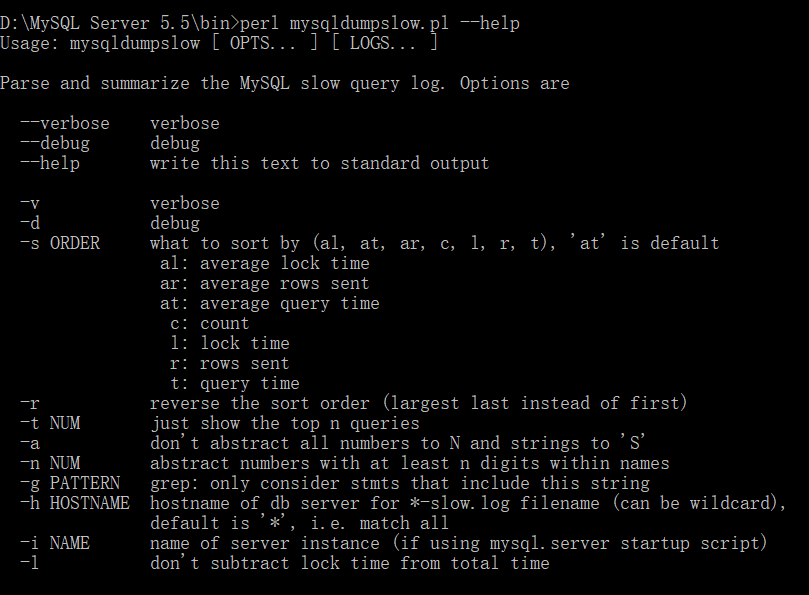
查看帮助文档:
perl mysqldumpslow.pl --help
举栗:
获取返回记录最多的3个SQL
perl mysqldumpslow.pl -s r -t 3 "D:/MySQL Server 5.5/slow_query_log.log"
获取访问次数最多的3个SQL
perl mysqldumpslow.pl -s c -t 3 "D:/MySQL Server 5.5/slow_query_log.log"
按照时间排序,前10条包含left join查询语句的SQL
perl mysqldumpslow.pl -s t -t 10 -g "left join" "D:/MySQL Server 5.5/slow_query_log.log"
慢查询SQL排查的更多相关文章
- 快速学会慢查询SQL排查
转载请注明出处️ 作者:测试蔡坨坨 原文链接:caituotuo.top/c56bd0c5.html 你好,我是测试蔡坨坨. 在往期文章中,我们聊过数据库基础知识,可参考「数据库基础,看完这篇就够了! ...
- 解Bug之路-记一次中间件导致的慢SQL排查过程
解Bug之路-记一次中间件导致的慢SQL排查过程 前言 最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,正好博客也好久不更新了,就以此为素材写出了本篇文章 ...
- MySQL - 常用命令及常用查询SQL
常用查询SQL #查看临时目录 SHOW VARIABLES LIKE '%tmp%'; #查看当前版本 SELECT VERSION(); 常用命令 #查看当前版本,终端下未进入mysql mysq ...
- 【ORACLE】记录通过执行Oracle的执行计划查询SQL脚本中的效率问题
记录通过执行Oracle的执行计划查询SQL脚本中的效率问题 问题现象: STARiBOSS5.8.1R2版本中,河北对帐JOB执行时,无法生成发票对帐文件. 首先,Quartz表达式培植的启 ...
- 查询sql语句所花时间
--1:下面这种是SQL Server中比较简单的查询SQL语句执行时间方法,通过查询前的时间和查询后的时间差来计算的: declare @begin_date datetime declare @e ...
- 跨服务器查询sql语句样例
若2个数据库在同一台机器上:insert into DataBase_A..Table1(col1,col2,col3----)select col11,col22,col33-- from Data ...
- 查询sql表列名
--查询sql 查询表列名Select Name FROM SysColumns Where id=Object_Id('Tab') --查询sql数据库表列名称select name from sy ...
- 批量查询sql脚本
远程批量查询sql脚本 for i in {1..50} do sql_ip=172.168.0.${i} information=`mysql -h ${sql_ip} -uroot -ppas ...
- [转]查询 SQL Server 系统目录常见问题
查询 SQL Server 系统目录常见问题 http://msdn.microsoft.com/zh-cn/library/ms345522.aspx#_FAQ4 下列部分按类别列出常见问题. 数据 ...
- 一条查询sql的执行流程和底层原理
1.一条查询SQL执行流程图 2.查询SQL执行流程之发送SQL请求 (1)客户端按照Mysql通信协议将SQL发送到服务端,SQL到达服务端后,服务端会单起一个线程执行SQL. (2)执行时Mysq ...
随机推荐
- JS实现提示文本框可输入剩余字数
最近在设计写博客功能时,涉及到留言框输入字数限制,需要给用户剩余数字提示. 参考文章:https://www.cnblogs.com/crazytrip/p/4968230.html 实现效果: 源码 ...
- OpenCV开发笔记(六十六):红胖子8分钟带你总结形态学操作-膨胀、腐蚀、开运算、闭运算、梯度、顶帽、黑帽(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- django中一些快捷函数
1.get_object_or_404() 接收两个参数,参数1为模型类,参数2为查询参数 查询到对象则返回对象,查询不到则返回http404,但是不会返回模型的DoesNotExist异常 示例: ...
- django项目中使用nginx+fastdfs上传图片和使用图片的流程
自定义文件存储类 1.先弄清楚django中默认的上传文件存储FileSystemStorage类 https://docs.djangoproject.com/zh-hans/2.2/ref/fil ...
- React 中 Ref 引用
不要因为别人的评价而改变自己的想法,因为你的生活是你自己的. 1. React 中 Ref 的应用 1.1 给标签设置 ref 给标签设置 ref,ref="username", ...
- 02、etcd单机部署和集群部署
上一章我们认识了etcd,简单的介绍了 etcd 的基础概念,但是理解起来还是比较抽象的.这一章我们就一起来部署下 etcd .这样可以让我们对 etcd 有更加确切的认识. 1.etcd单实例部署 ...
- book 电子书转换 在线工具
https://convertio.co/download/911d3a3f39db0b2e39ed6e3c8acb31f6be786a/ Convertio
- Java 异常整合练习
1 package com.bytezero.throwable2; 2 3 /** 4 * 5 * @Description 异常练习 6 * @author Bytezero·zhenglei! ...
- nginx rewrite 语法
nginx rewrite 语法 一 定义 Rewrite主要实现url地址重写, 以及地址重定向,就是将用户请求web服 务器的地址重新定向到其他URL的过程. 二 语法格式 reweite fia ...
- xxl-job的基本使用
xxl-job的基本使用 xxl-job是分布式的调度平台调度执行器执行任务,使用的是DB锁(for update)来保证集群分布式调用的一致性,学习简单,操作容易,成本不高. 准备阶段 服务端配置 ...