k-均值聚类算法 Primary
k-均值聚类算法(英文:k-means clustering)
定义:
k-均值聚类算法的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
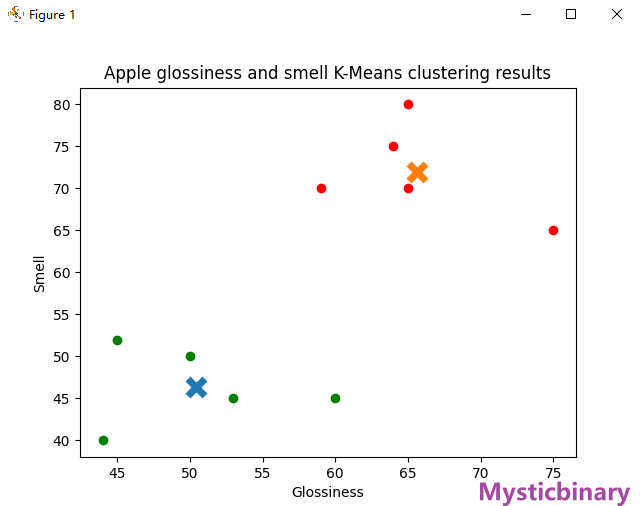
案例——区分好坏苹果(有Key)
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 生成随机样本数据
# 假设你采集数据是二维的,每个样本有两个特征 [光泽, 气味]
appleData = np.array([[44, 40], [60, 45], [59, 70], [65, 80], [50, 50],
[75, 65], [45, 52], [64, 75], [65, 70], [53, 45]])
# 将样本分成2类 : 好果、坏果
# 设置两个初始簇中心的位置,指定Key值
initial_centroids = np.array([[40, 20], [70, 80]])
# 创建KMeans对象,并指定初始簇中心位置
kmeans = KMeans(n_clusters=2, init=initial_centroids)
kmeans.fit(appleData)
# 获取每个样本的类别
labels = kmeans.labels_
# 提取聚类中心
centroids = kmeans.cluster_centers_
# 绘制散点图并着色
colors = ['g', 'r']
for i in range(len(appleData)):
plt.scatter(appleData[i][0], appleData[i][1], color=colors[labels[i]])
# 绘制聚类中心
for c in centroids:
plt.scatter(c[0], c[1], marker='x', s=150, linewidths=5, zorder=10)
# 添加标签和标题
plt.xlabel('Glossiness')
plt.ylabel('Smell')
plt.title('Apple glossiness and smell K-Means clustering results')
# 显示图形
plt.show()
show
案例——自动聚类(无Key)
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 生成随机样本数据
X = np.array([[60, 75], [59, 70], [65, 80], [80, 90], [75, 65],
[62, 75], [58, 68], [52, 60], [90, 85], [85, 90],
[70, 75], [65, 70], [55, 65], [75, 80], [80, 85],
[65, 75], [60, 70], [55, 60], [95, 95], [90, 90]])
# 将样本分成3类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# 获取每个样本的类别
labels = kmeans.labels_
# 提取聚类中心
centroids = kmeans.cluster_centers_
# 绘制散点图并着色
colors = ['r', 'g', 'b']
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], color=colors[labels[i]])
# 绘制聚类中心
for c in centroids:
plt.scatter(c[0], c[1], marker='x', s=150, linewidths=5, zorder=10)
# 添加标签和标题
plt.xlabel('Glossiness')
plt.ylabel('Smell')
plt.title('Apple glossiness and smell K-Means clustering results')
# 显示图形
plt.show()
show

k-均值聚类算法 Primary的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
随机推荐
- win32 - 关于GDI的RGB的数据分析
此文章为小结,仅供参考. 第一种情况,从桌面DC获取RGBA的数据. 32位 HDC hdc, hdcTemp; RECT rect; BYTE* bitPointer; int x, y; int ...
- 分层架构设计模式总结-MVC,洋葱架构,整洁架构,六边形架构,DDD等等
一.单层结构不分层 最开始开发项目时,由于需求较少,用一个单独的工程文件就可以满足开发的需求了,不需要进行划分. 二.MVC 分层和三层 到后面需求越来越多,于是就把文件进行分解,怎么分解?有人提出了 ...
- 深入理解Go语言(01): interface源码分析
分析接口的赋值,反射,断言的实现原理 版本:golang v1.12 interface底层使用2个struct表示的:eface和iface 一:接口类型分为2个 1. 空接口 //比如 var i ...
- 标准运算符替代函数之operator模块
# 官网参考示例地址 https://docs.python.org/zh-cn/3/library/operator.html # operator模块提供了一套与python的内置的运算符对应的高 ...
- 【Azure Redis 缓存】Redis连接无法建立问题的排查(注:Azure Redis集成在VNET中)
问题描述 在Azure App Service中部署的应用,需要连接到Redis中,目标Redis已经集成了虚拟网络(VNET)并且在Redis的网络防火墙中已经添加App Service的出站IP地 ...
- 十: SQL执行流程
SQL执行流程 1. MySQL 中的 SQL执行流程 MySQL的查询流程: 1.1 查询缓存 Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端:如果没 有,就进入 ...
- 阿里云Python UDP Server和client基础教程
壹: socket通信是常用的一种通信方式,熟练掌握,快速的入戏,是一个程序员必备的素质. 贰: 注意:udp和tcp的套接字: 服务端代码: #!/usr/bin/env python3 # -*- ...
- Navicat 15下载教程
Navicat 15下载_永久激活注册码(附图文安装教程) 欢迎关注博主公众号「java大师」, 专注于分享Java领域干货文章, 关注回复「资源」, 免费领取全网最热的Java架构师学习PDF, 转 ...
- Android 桌面小组件使用
原文: Android 桌面小组件使用-Stars-One的杂货小窝 借助公司上的几个项目,算是学习了Android桌面小组件的用法,记下踩坑记录 基本步骤 1.创建小组件布局 这里需要注意的事,小组 ...
- Android Swtich开关样式调整
原文:Android Swtich开关样式调整 - Stars-One的杂货小窝 接入百度人脸的demo时候,发现了内置的switch开关比较好看,看了下实现方法,原来只是改了下样式,记录一下 效果: ...