k-均值聚类算法 Primary
k-均值聚类算法(英文:k-means clustering)
定义:
k-均值聚类算法的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
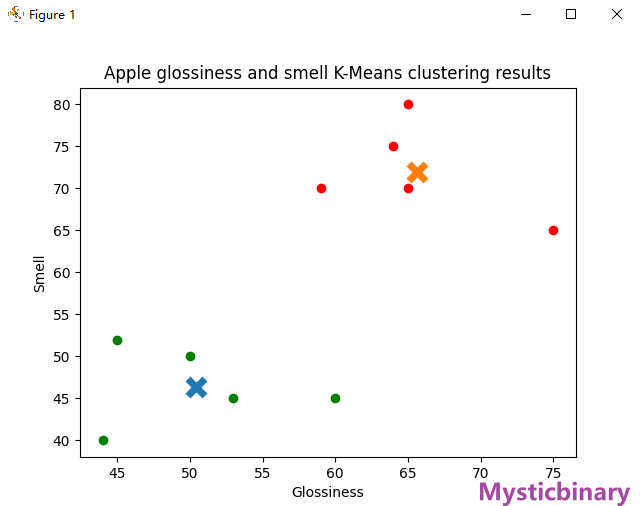
案例——区分好坏苹果(有Key)
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 生成随机样本数据
# 假设你采集数据是二维的,每个样本有两个特征 [光泽, 气味]
appleData = np.array([[44, 40], [60, 45], [59, 70], [65, 80], [50, 50],
[75, 65], [45, 52], [64, 75], [65, 70], [53, 45]])
# 将样本分成2类 : 好果、坏果
# 设置两个初始簇中心的位置,指定Key值
initial_centroids = np.array([[40, 20], [70, 80]])
# 创建KMeans对象,并指定初始簇中心位置
kmeans = KMeans(n_clusters=2, init=initial_centroids)
kmeans.fit(appleData)
# 获取每个样本的类别
labels = kmeans.labels_
# 提取聚类中心
centroids = kmeans.cluster_centers_
# 绘制散点图并着色
colors = ['g', 'r']
for i in range(len(appleData)):
plt.scatter(appleData[i][0], appleData[i][1], color=colors[labels[i]])
# 绘制聚类中心
for c in centroids:
plt.scatter(c[0], c[1], marker='x', s=150, linewidths=5, zorder=10)
# 添加标签和标题
plt.xlabel('Glossiness')
plt.ylabel('Smell')
plt.title('Apple glossiness and smell K-Means clustering results')
# 显示图形
plt.show()
show
案例——自动聚类(无Key)
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 生成随机样本数据
X = np.array([[60, 75], [59, 70], [65, 80], [80, 90], [75, 65],
[62, 75], [58, 68], [52, 60], [90, 85], [85, 90],
[70, 75], [65, 70], [55, 65], [75, 80], [80, 85],
[65, 75], [60, 70], [55, 60], [95, 95], [90, 90]])
# 将样本分成3类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# 获取每个样本的类别
labels = kmeans.labels_
# 提取聚类中心
centroids = kmeans.cluster_centers_
# 绘制散点图并着色
colors = ['r', 'g', 'b']
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], color=colors[labels[i]])
# 绘制聚类中心
for c in centroids:
plt.scatter(c[0], c[1], marker='x', s=150, linewidths=5, zorder=10)
# 添加标签和标题
plt.xlabel('Glossiness')
plt.ylabel('Smell')
plt.title('Apple glossiness and smell K-Means clustering results')
# 显示图形
plt.show()
show

k-均值聚类算法 Primary的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
随机推荐
- windows 上 ffmpeg 库的安装
真复杂啊 安装 ffmpeg 库有两种途径,一种是自己下载源码再去编译,另一种是使用 vcpkg 自动安装 一般情况下,第二种是最简单方便的,但是如果你需要使用 ffmpeg 的特定历史版本,那就有点 ...
- django中使用celery异步发送邮件
申请163网易发送邮件权限 在django中settings配置文件 #配置邮件服务器 EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBac ...
- 【LeetCode二叉树#02】二叉树层序遍历(广度优先搜索),十合一专题
二叉树层序遍历(广度优先搜索) 102 二叉树的层序遍历 力扣题目链接(opens new window) 给你一个二叉树,请你返回其按 层序遍历 得到的节点值. (即逐层地,从左到右访问所有节点). ...
- Linux的这些命令你需要掌握
查看进程: 查看所有进程:ps -ef 查看指定的进程: ps -ef|grep pid(进程号) 查看前40个内存占用的进程: ps auxw|head -1;ps auxw|sort -rn -k ...
- [vbs] 定时关闭进程代码
Dim bag,pipe do Set bag=GetObject("WinMgmts:") Set pipe=bag.execquery("select * from ...
- 手把手教你蜂鸟e203协处理器的扩展
NICE协处理器 赛题要求: 对蜂鸟E203 RISC-V内核进行运算算子(譬如加解密算法.浮点运算.矢量运算等)的扩展,可通过NICE协处理器接口进行添加,也可直接实现RISC-V指令子集(譬如 ...
- Java 常用类 String的常用方法(2)
1 /** 2 * String 常用方法(2) 3 * boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束 4 * boolean startsWith ...
- Java ----多线程 案例
1 package bytezero.threadtest2; 2 3 /** 4 * 银行有一个账户 5 * 有两个储户分别向同一个账户存 3000元,每次存1000,存三次,每次存完打印账户余额 ...
- 获取一段时间内,以月/季度为单位,第N天在各个月/季度是几几年几月几号
/** * 获取一段时间内(可跨年),以季度为单位,第N天在各个季度是几月几号 * @param $sTime 时间戳 * @param $eTime 时间戳 * @param $number 第N天 ...
- 回声消除AEC(Acoustic Echo Cancellation)概括介绍及基本原理分析
回声消除的基本概念 回音消除(Acoustic Echo Cancelling)是透过音波干扰方式消除麦克风与喇叭因空气产生回受路径(feedback path)而产生的杂音.通俗一点来说,回声消 ...