【Flink入门修炼】1-1 为什么要学习 Flink?
流处理和批处理是什么?
什么是 Flink?为什么要学习 Flink?
Flink 有什么特点,能做什么?
本文将为你解答以上问题。
一、批处理和流处理
早些年,大数据处理还主要为批处理,一般按天或小时定时处理数据,代表性的框架为 MapReduce、Hive、Spark 等。
但是,传统批处理的问题也很快显现:
- 实时性低,数据一般为 T-1 的数据
- 数据存储方式,无法按行进行修改,需要按分区重写
- 必须等数据都到了才能开始计算
- 计算处理时间一般较长
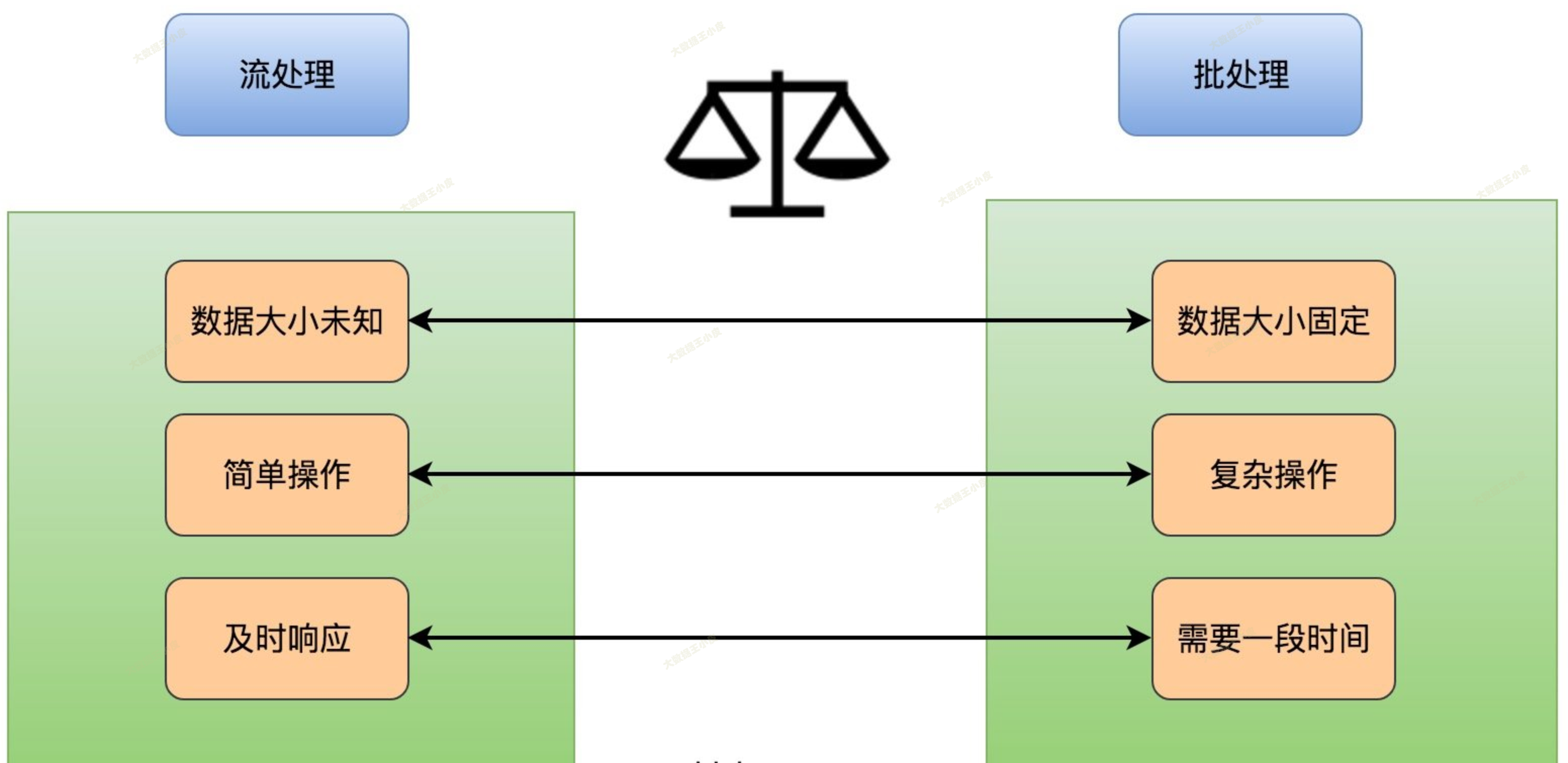
为了解决批处理的问题,流处理应运而生。
流处理能将实时产生的数据,实时计算。将延迟降低到秒级或者毫秒级。
流处理引擎也已经经过了几代的发展,需要一个高吞吐、低延迟、高性能的分布式处理框架。
Flink 作为如今的佼佼者,在各大公司大规模使用,下面我们来介绍下 Flink。
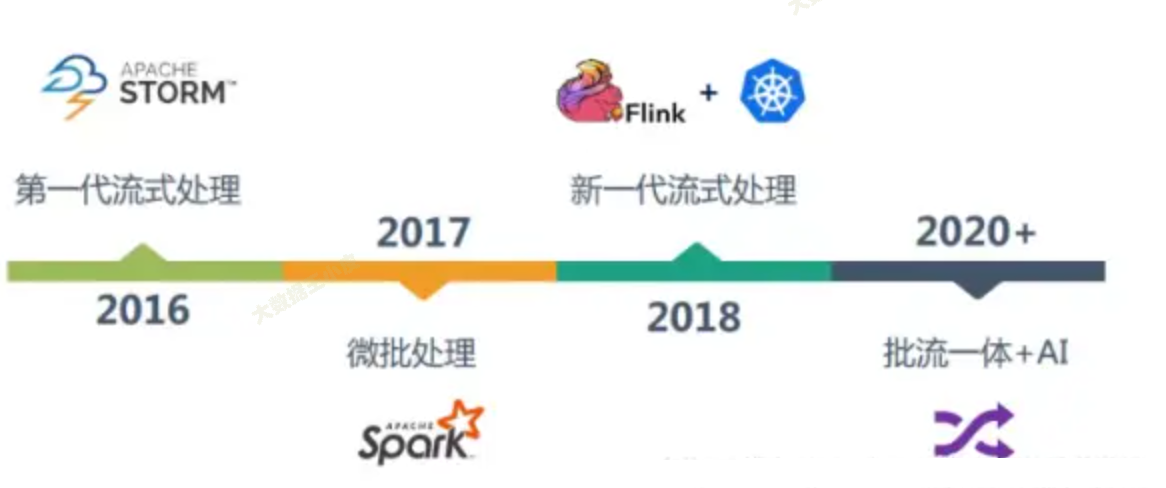
二、Flink是什么
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供流处理和批处理两种类型应用功能。
另一方面,Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行。
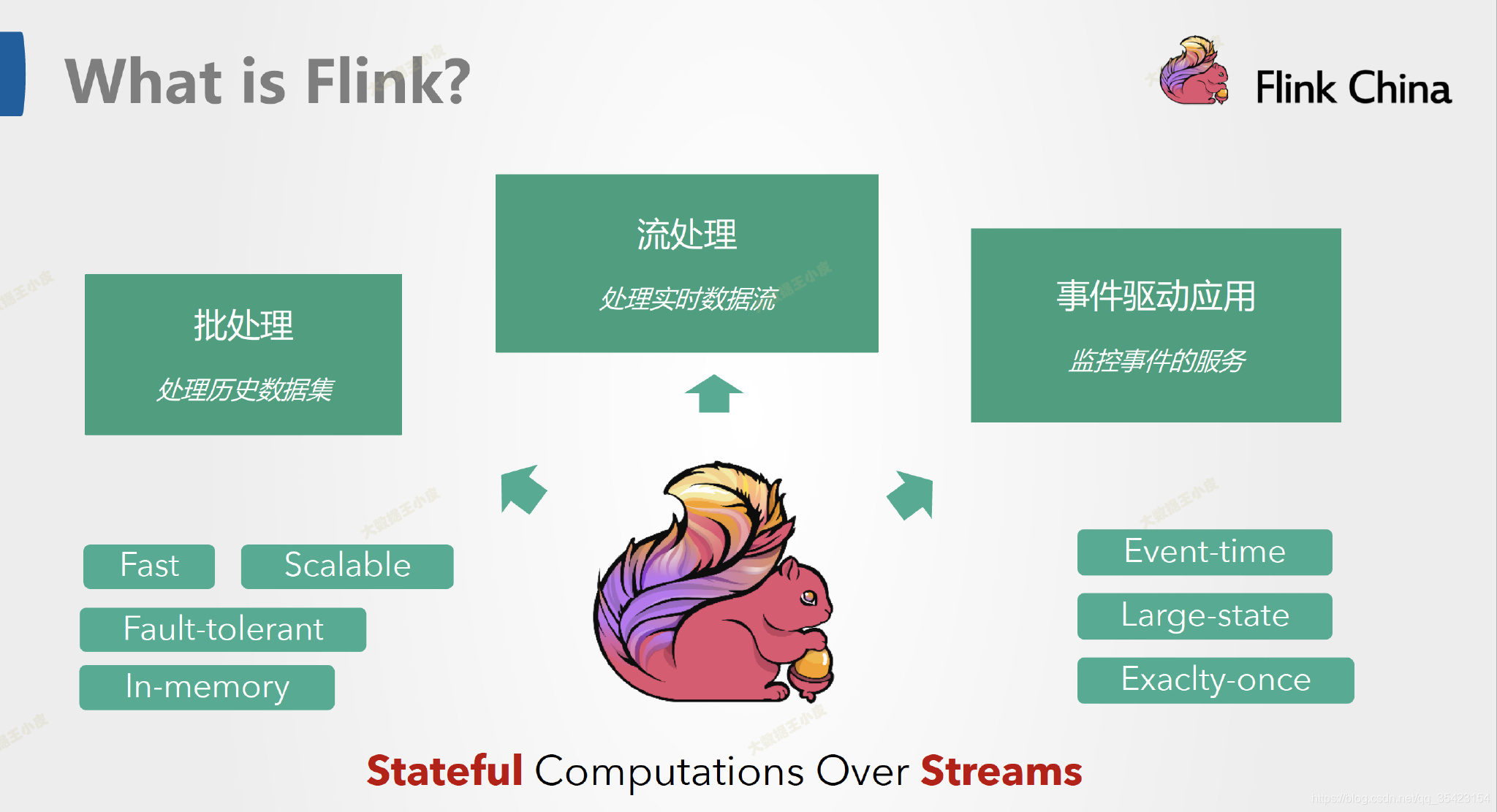

Flink 常见数据处理流程:

左边是数据源,可以是实时日志、数据库、文件系统等。
中间是Flink,负责对数据进行处理。
右边是输出,Flink可以将计算好的数据输出到其它应用中,或者存储系统中。
三、特点
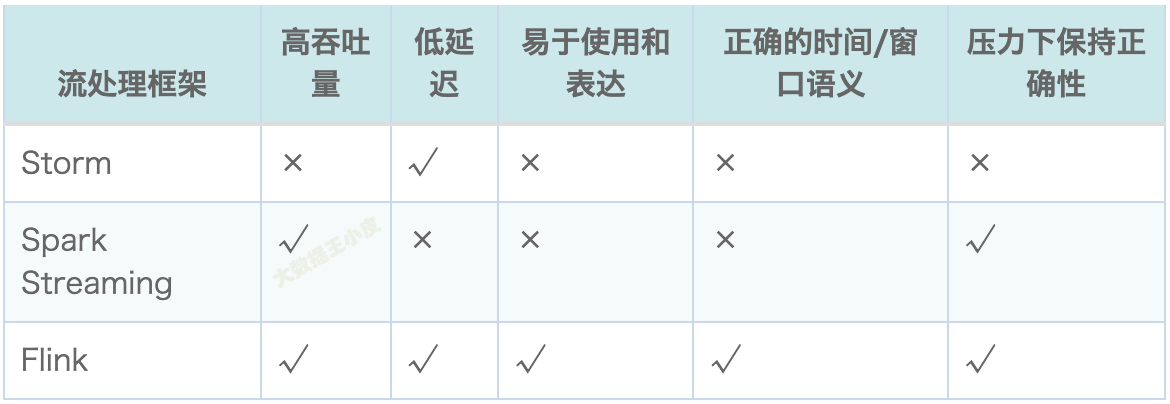
1、高吞吐、低延迟、高性能。
Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式处理框架。
像 Spark 使用微批处理方式,使其在流式计算中无法做到低延迟保障;
而 Storm 无法满足高吞吐的要求。
2、同时支持事件时间和处理时间语义。
处理时间好理解,就是数据到达框架开始计算的时间,此方式也方便实现。
另一个,事件时间是指的数据产生时间。由于数据从产生到传入计算框架,中间会经过多个服务,也会因各种网络问题造成延迟,导致数据并不是按照产生时间的先后顺序到达计算框架的。如何处理乱序数据,是框架需要处理的一个重要问题。
Flink 则能够同时支持 事件时间 和 处理时间 进行窗口计算。
3、支持有状态计算,并提供精确一次的状态一致性保障。
所谓状态,就是之前数据计算得到的结果,这个结果不光是输出的部分,还包括中间算子的计算结果(如 pv、uv 等)。
这样当有下一个数据流入时,不再需要将之前的数据再加上新数据重新计算,直接用原来的结果继续算就行。这种方式极大地提升了系统的性能,并降低了数据计算过程的资源消耗。
4、基于轻量级分布式快照实现的容错机制。
Flink 能够分布式运行在上千个节点上,将一个大型计算任务的流程拆解成小的计算过程,然后将 Task 分布到并行节点上进行处理。
通过基于分布式快照技术的 Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常终止,Flink 就能够从 Checkpoints 中进行任务的自动恢复,以确保数据中处理过程中的一致性。
5、保证了高可用,动态扩展。
支持高可用性配置(无单点失效),和 Kubernetes、YARN、Apache Mesos 紧密集成,快速故障恢复,动态扩缩容作业等。基于上述特点,它可以7 X 24小时运行流式应用,几乎无须停机。
当需要动态更新或者快速恢复时,Flink 通过 Savepoints 技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的 Savepoints 恢复原有的计算状态,使得任务继续按照停机之前的状态运行。
6、支持高度灵活的窗口操作。
Flink将窗口划分为基于 Time、Count、Session,以及 Data-driven 等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。
四、应用场景
在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、互联网订单数据、GPS定位数据、传感器信号、移动终端产生的数据、通信信号数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生,然后再传输到下游的分析系统。
针对这些数据类型主要包括以下场景,Flink 对这些场景都有非常好的支持。暂时不理解如何起作用的没关系,有个大概印象即可。
1、实时智能推荐
利用Flink流计算帮助用户构建更加实时的智能推荐系统,对用户行为指标进行实时计算,对模型进行实时更新,对用户指标进行实时预测,并将预测的信息推送给Web/App端,帮助用户获取想要的商品信息,另一方面也帮助企业提高销售额,创造更大的商业价值。
2、复杂事件处理
例如工业领域的复杂事件处理,这些业务类型的数据量非常大,且对数据的时效性要求较高。我们可以使用Flink提供的CEP(复杂事件处理)进行事件模式的抽取,同时应用Flink的SQL进行事件数据的转换,在流式系统中构建实时规则引擎。
3、实时欺诈检测
在金融领域的业务中,常常出现各种类型的欺诈行为。运用Flink流式计算技术能够在毫秒内就完成对欺诈判断行为指标的计算,然后实时对交易流水进行规则判断或者模型预测,这样一旦检测出交易中存在欺诈嫌疑,则直接对交易进行实时拦截,避免因为处理不及时而导致的经济损失
4、实时数仓与ETL
结合离线数仓,通过利用流计算等诸多优势和SQL灵活的加工能力,对流式数据进行实时清洗、归并、结构化处理,为离线数仓进行补充和优化。另一方面结合实时数据ETL处理能力,利用有状态流式计算技术,可以尽可能降低企业由于在离线数据计算过程中调度逻辑的复杂度,高效快速地处理企业需要的统计结果,帮助企业更好的应用实时数据所分析出来的结果。
5、流数据分析
实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略,在各类投放、无线智能推送领域有大量的应用。流式计算技术将数据分析场景实时化,帮助企业做到实时化分析Web应用或者App应用的各种指标。
6、实时报表分析
实时报表分析说近年来很多公司采用的报表统计方案之一,其中最主要的应用便是实时大屏展示。利用流式计算实时得出的结果直接被推送到前段应用,实时显示出重要的指标变换,最典型的案例就是淘宝的双十一实时战报。
五、小结
本文从批处理和流处理的区别入手,为了处理实时数据,流处理应运而生。在一代代流处理框架的演进过程中,Flink 通过其高吞吐、低延迟、高性能的特点,成为了当前炙手可热的流处理框架。
后面介绍了 Flink 框架的一些基本特点和应用场景,带大家初步了解了 Flink 框架。
后续将带大家深入了解 Flink 框架的内存,敬请期待。
参考文章:
什么是流处理和批处理?
Flink(2):为什么选择Flink - 掘金
Flink01:快速了解Flink:什么是Flink、Flink架构图、Flink三大核心组件、Flink的流处理与批处理、Storm vs SparkStreaming vs Flink-CSDN博客
【Flink入门修炼】1-1 为什么要学习 Flink?的更多相关文章
- Flink入门宝典(详细截图版)
本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本.需要安装Netcat进行简单调试. 这里简述安装过程,并使用IDEA进行开发一个简单流处理程序 ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
- Flink入门(五)——DataSet Api编程指南
Apache Flink Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾批处理,流处理的特性,Flink ...
- 记一次flink入门学习笔记
团队有几个系统数据量偏大,且每天以几万条的数量累增.有一个系统每天需要定时读取数据库,并进行相关的业务逻辑计算,从而获取最新的用户信息,定时任务的整个耗时需要4小时左右.由于定时任务是夜晚执行,目前看 ...
- 不一样的Flink入门教程
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
我们右键运行时相当于在本地启动了一个单机版本.生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数. 本课时我们主要介绍 Flink 的入门程序以及 SQ ...
- Flink入门使用
完全参考:Flink1.3QuickStart 启动本地运行 首先找一台安装了hadoop的linux. 将安装包解压,到bin目录启动local模式的脚本. tar -zxvf flink-1.3. ...
随机推荐
- uni-app返回上一级,页面不刷新,bug
uniapp 生命周期(onLoad跟onLoadonShow的区别) 一.uniapp生命周期分两种 : 1.应用生命周期:仅可在App.vue中监听,在其它页面监听无效. 2.页面生命周期:仅在p ...
- C#之RabbitMQ
本文内容整理自https://blog.csdn.net/by_ron/category_6167618.html RabbitMQ–环境搭建 能点进来相信你明白RabbitMQ是干什么的了,这个系列 ...
- ASP.NET Core 5.0 MVC 页面标记帮助程序的使用
什么是标记帮助程序 标记帮助程序使服务器端代码可以在 Razor 文件中参与创建和呈现 HTML 元素.标记帮助程序使用 C# 创建,基于元素名称.属性名称或父标记以 HTML 元素为目标. 创建标记 ...
- C语言基础之理论概述
C语言介绍 C语言是一种高级程序设计语言,由贝尔实验室的Dennis Ritchie在1972年开发.C语言是结构化编程语言,支持变量.数据类型.运算符.表达式.流程控制语句和函数等基本程序设计元素. ...
- Elasticsearch 索引与文档的常用操作总结二:复杂条件查询
本文为博主原创,未经允许不得转载: 1. 查询所有:match_all GET /es_db/_doc/_search { "query":{ "match_all&q ...
- Python定位错误:段错误 (核心已转储)
技术背景 在各种编程语言中都有可能会遇到这样一个报错:"段错误 (核心已转储)".显然是编写代码的过程中有哪里出现了问题,但是这个报错除了这几个字以外没有任何的信息,我们甚至不知道 ...
- 部署开源项目管理工具focalboard
前言 focalboard是一款开源项目管理工具,类似Jira.Trello.官网地址 组件 版本 说明 Debian 12.1 操作系统 docker 20.10.7 容器运行时 docker-co ...
- [转帖]S3FS 简介及部署
PS:文章一般都会先首发于我的个人Blog上:S3FS 简介及部署 · TonghuaRoot's BloG. ,有需要的小伙伴可以直接订阅我的Blog,获取最新内容. 0x00 前言 S3FS可以把 ...
- [转帖]Jmeter学习笔记(十七)——jmeter目录结构
原文链接:http://www.cnblogs.com/zichuan/p/6938772.html 一.bin目录examples: 目录中有CSV样例 jmeter.bat windows ...
- [转帖]dd 自动压测与结果解析脚本
测试串行.并发.读.写 4类操作,每类操作又可以指定各种bs及count值,循环压测.每种场景一般执行3次,取平均值. 一. 串行写 #!/bin/sh bs_list=(256k 1024k 10M ...