[转帖]FIO 存储性能压测
一、 FIO简介
FIO 是一个多线程IO生成工具,可以生成多种IO模式(随机、顺序、读、写四大类),用来测试磁盘设备的性能。GFIO是FIO的图形监测工具,它提供了图形界面的参数配置,和性能监测图像。
在github上的链接为 https://github.com/axboe/fio
二、 FIO安装
1. yum安装
yum -y install fio.x86_64
2. 源码安装
- Best Open Source Mac Software Development Software 2023 下载FIO安装包 fio-2.1.10.tar.gz
- 安装libaio-devel依赖包(如果是先编译了fioz,发现报错才装libaio-devel的,需要先用make clean清理编译文件后再重新编译安装FIO )
yum -y install libaio* gcc wget make
- 安装gfio:基于gdk实现,是其图形界面版(可选)
yum -y install libgtk2.0-dev
- 解压FIO压缩包,进入FIO目录编译安装
-
./configure --enable-gfio #如果希望不支持gfio,只需去掉后面的--enable-gfio参数
-
make
-
make install
- 设置环境变量
-
vi .bash_profile
-
-
PATH=$PATH:$HOME/bin:/usr/local/bin
-
-
source .bash_profile
三、 常用参数
-
filename=/dev/emcpowerb 支持文件系统或者裸设备,-filename=/dev/sda2或-filename=/dev/sdb
-
direct=1 测试过程绕过机器自带的buffer,使测试结果更真实
-
rw=randwread 测试随机读的I/O
-
rw=randwrite 测试随机写的I/O
-
rw=randrw 测试随机混合写和读的I/O
-
rw=read 测试顺序读的I/O
-
rw=write 测试顺序写的I/O
-
rw=rw 测试顺序混合写和读的I/O
-
bs=4k 单次io的块文件大小为4k
-
bsrange=512-2048 同上,提定数据块的大小范围
-
size=5g 本次的测试文件大小为5g,以每次4k的io进行测试
-
numjobs=30 本次的测试线程为30
-
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止
-
ioengine=psync io引擎使用pync方式,如果要使用libaio引擎,需要yum install libaio-devel包
-
rwmixwrite=30 在混合读写的模式下,写占30%
-
group_reporting 关于显示结果的,汇总每个进程的信息
-
此外
-
lockmem=1g 只使用1g内存进行测试
-
zero_buffers 用0初始化系统buffer
-
nrfiles=8 每个进程生成文件的数量
四、 常用测试场景
1. 命令行测试
- 100%随机,100%读,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
- 100%随机,100%写,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
- 100%顺序,100%读,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
- 100%顺序,100%写,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
- 100%随机,70%读,30%写 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
2. 参数文件测试
FIO提供了不同场景的压测参数文件,修改其中配置然后直接执行即可。https://github.com/axboe/fio/tree/master/examples
fio examples/ssd-test.fio
上面这个参数文件用于测试ssd性能,参数文件内容如下:
其中每一个[]代表一个测试分组,会为每组分别进行测试(比如下面有5组)。
-
# Do some important numbers on SSD drives, to gauge what kind of
-
# performance you might get out of them.
-
#
-
# Sequential read and write speeds are tested, these are expected to be
-
# high. Random reads should also be fast, random writes are where crap
-
# drives are usually separated from the good drives.
-
#
-
# This uses a queue depth of 4. New SATA SSD's will support up to 32
-
# in flight commands, so it may also be interesting to increase the queue
-
# depth and compare. Note that most real-life usage will not see that
-
# large of a queue depth, so 4 is more representative of normal use.
-
#
-
[global]
-
bs=4k
-
ioengine=libaio
-
iodepth=4
-
size=10g
-
direct=1
-
runtime=60
-
directory=/mount-point-of-ssd
-
filename=ssd.test.file
-
-
[seq-read]
-
rw=read
-
stonewall
-
-
[rand-read]
-
rw=randread
-
stonewall
-
-
[seq-write]
-
rw=write
-
stonewall
-
-
[rand-write]
-
rw=randwrite
-
stonewall
下面是一个模拟MySQL数据库的压测配置文件
-
# QPS: 40000(10 cores)
-
# Dataset: 200G
-
# R/W: 8/2
-
# ThreadPool Num: 64
-
# IO ThreadNum: 32
-
-
[global]
-
runtime=86400
-
time_based
-
group_reporting
-
directory=/your_dir
-
ioscheduler=deadline
-
refill_buffers
-
-
[mysql-binlog]
-
filename=test-mysql-bin.log
-
bsrange=512-1024
-
ioengine=sync
-
rw=write
-
size=24G
-
sync=1
-
rw=write
-
overwrite=1
-
fsync=100
-
rate_iops=64
-
invalidate=1
-
numjobs=64
-
-
[innodb-data]
-
filename=test-innodb.dat
-
bs=16K
-
ioengine=psync
-
rw=randrw
-
size=200G
-
direct=1
-
rwmixread=80
-
numjobs=32
-
-
thinktime=600
-
thinktime_spin=200
-
thinktime_blocks=2
-
-
[innodb-trxlog]
-
filename=test-innodb.log
-
bsrange=512-2048
-
ioengine=sync
-
rw=write
-
size=2G
-
fsync=1
-
overwrite=1
-
rate_iops=64
-
invalidate=1
-
numjobs=64
五、 测试结果解读
测试输出结果如下
-
fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=read -filename=/dev/sda -name="BS 4KB read test" -iodepth=16 -runtime=60
-
-
#输出
-
BS 4KB read test: (g=0): rw=write, bs=1M-1M/1M-1M/1M-1M, ioengine=libaio, iodepth=16
-
fio-2.8
-
Starting 1 process
-
Jobs: 1 (f=1): [W(1)] [100.0% done] [0KB/68198KB/0KB /s] [0/66/0 iops] [eta 00m:00s]
-
test: (groupid=0, jobs=1): err= 0: pid=4676: Thu Apr 7 17:22:37 2016
-
write: io=20075MB, bw=68464KB/s, iops=66, runt=300255msec #执行多少IO,平均带宽,线程运行时间
-
slat (usec): min=51, max=5732, avg=291.11, stdev=262.47 #提交延迟
-
clat (usec): min=1, max=2235.8K, avg=239043.28, stdev=153384.41 #完成延迟
-
lat (usec): min=367, max=2235.9K, avg=239337.72, stdev=153389.57 #响应时间
-
clat percentiles (usec):
-
| 1.00th=[ 221], 5.00th=[ 442], 10.00th=[ 1004], 20.00th=[108032],
-
| 30.00th=[228352], 40.00th=[248832], 50.00th=[257024], 60.00th=[268288],
-
| 70.00th=[280576], 80.00th=[301056], 90.00th=[342016], 95.00th=[477184],
-
| 99.00th=[806912], 99.50th=[864256], 99.90th=[1122304], 99.95th=[1171456],
-
| 99.99th=[1646592]
-
bw (KB/s): min= 170, max=204800, per=100.00%, avg=68755.07, stdev=27034.84
-
lat (usec) : 2=0.01%, 4=0.13%, 50=0.06%, 100=0.26%, 250=1.04%
-
lat (usec) : 500=4.53%, 750=2.61%, 1000=1.33%
-
lat (msec) : 2=1.18%, 4=0.15%, 10=0.77%, 20=0.77%, 50=1.50%
-
lat (msec) : 100=4.43%, 250=23.48%, 500=53.23%, 750=3.09%, 1000=1.30%
-
lat (msec) : 2000=0.19%, >=2000=0.01%
-
cpu : usr=0.03%, sys=2.11%, ctx=19066, majf=0, minf=7
-
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=103.8%, 32=0.0%, >=64=0.0% #io队列
-
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% #单个IO提交要提交的IO数
-
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
-
issued : total=r=0/w=20060/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
-
latency : target=0, window=0, percentile=100.00%, depth=16 #IO完延迟的分布
-
-
Run status group 0 (all jobs):
-
WRITE: io=20075MB, aggrb=68464KB/s(group总带宽), minb=68464KB/s(最小平均带宽), maxb=68464KB/s(最大平均带宽), mint=300255msec(group中线程的最短运行时间), maxt=300255msec(group中线程的最长运行时间)
-
-
Disk stats (read/write):
-
sda: ios=23/41769(所有group总共执行的IO数), merge=0/149(总共发生的IO合并数), ticks=706/9102766(Number of ticks we kept the disk busy), in_queue=9105836(花费在队列上的总共时间), util=100.00%(磁盘利用率)
输出参数介绍(详情参考 Fio Output Explained)
- io=执行了多少M的IO
- bw=平均IO带宽(吞吐量)
- iops=IOPS
- runt=线程运行时间
- slat=提交延迟,提交该IO请求到kernel所花的时间(不包括kernel处理的时间)
- clat=完成延迟, 提交该IO请求到kernel后,处理所花的时间
- lat=响应时间
- bw=带宽
- cpu=利用率
- IO depths=io队列
- IO submit=单个IO提交要提交的IO数
- IO complete=Like the above submit number, but for completions instead.
- IO issued=The number of read/write requests issued, and how many of them were short.
- IO latencies=IO完延迟的分布
- io=总共执行了多少size的IO
- aggrb=group总带宽
- minb=最小平均带宽
- maxb=最大平均带宽
- mint=group中线程的最短运行时间
- maxt=group中线程的最长运行时间
- ios=所有group总共执行的IO数
- merge=总共发生的IO合并数
- ticks=Number of ticks we kept the disk busy
- io_queue=花费在队列上的总共时间
- util=磁盘利用率
六、 测试建议
- 使用顺序IO和较大的blocksize测试吞吐量和延迟
- 使用随机IO和较小的blocksize测试IOPS和延迟
- 在配置numjobs和iodeph前,建议深入了解应用采用的是同步IO还是异步IO(是多进程并发IO还是一次提交一批IO请求)
备注
- 磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
- 磁盘的吞吐量,也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小。
- 每秒 I/O 吞吐量= IOPS* 平均 I/O SIZE。
七、 简单自动压测脚本

八、 输出结果解析命令
我们一般记录框里的值
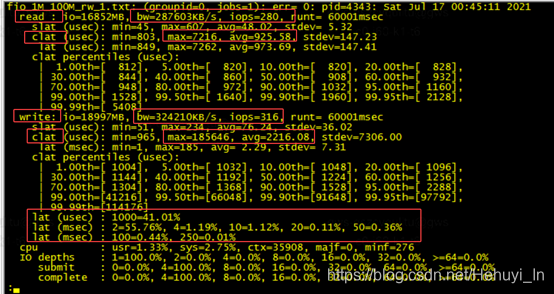
读IO提交延迟
cat fio_* |grep -A 3 read |grep clat > read.tmp
写IO提交延迟
cat fio_* |grep -A 3 write |grep clat > write.tmp
带宽与iops
读
cat fio_* |grep bw|grep iops|grep read > r_iops.tmp
写
cat fio_* |grep bw|grep iops|grep write > w_iops.tmp
直方图信息(记录最大比例)
cat -n fio_* | grep 'lat (' | grep -v min > histos.tmp

参考
FIO使用说明_半遮雨的博客-CSDN博客_fio util结果100%
</article>
[转帖]FIO 存储性能压测的更多相关文章
- 软件性能测试分析与调优实践之路-JMeter对RPC服务的性能压测分析与调优-手稿节选
一.JMeter 如何通过自定义Sample来压测RPC服务 RPC(Remote Procedure Call)俗称远程过程调用,是常用的一种高效的服务调用方式,也是性能压测时经常遇到的一种服务调用 ...
- MySQL 性能压测工具-sysbench,从入门到自定义测试项
sysbench是一个开源的.基于LuaJIT(LuaJIT 是 Lua 的即时编译器,可将代码直接翻译成机器码,性能比原生 lua 要高) 的.可自定义脚本的多线程基准测试工具,也是目前用得最多的 ...
- 性能压测诡异的Requests/second 响应刺尖问题
最近一段时间都在忙着转java项目最后的冲刺,前期的coding翻代码.debug.fixbug都逐渐收尾,进入上线前的性能压测. 虽然不是大促前的性能压测要求,但是为了安全起见,需要摸个底心里有个数 ...
- jmeter系列-如何实现像loadrunner一样,多个并发用户先通过登录初始化,然后做并发的接口性能压测
自动转开发后,就很少关注性能测试方面的东西,最近在帮朋友做一个性能压测,由于朋友那边的公司比较小,环境比较简单,而且是对http服务进行的压测,所以最终 选用了jmeter来实现这个压测. 如下就是我 ...
- 性能压测,SQL查询异常
早上测试对性能压测,发现取sequence服务大量超时报错,查询线上的监控SQL: 大量这个查询,我在DeviceID和Isdelete上建有复合索引,应该很快,而且我测试了一下,取值,执行效率很高, ...
- jmeter性能压测瓶颈排查-网络带宽
问题: 有一台机器做性能压测的时候,无论开多少个线程,QPS一直压不上去,而服务器和数据库的性能指标(主要是CPU和内存)一直维持在很低的水平. 希望帮忙排查一下原因. 过去看了下进行压测的接口代码, ...
- 性能压测中的SLA,你知道吗?
本文是<Performance Test Together>(简称PTT)系列专题分享的第6期,该专题将从性能压测的设计.实现.执行.监控.问题定位和分析.应用场景等多个纬度对性能压测的全 ...
- 并发模式与 RPS 模式之争,性能压测领域的星球大战
本文是<如何做好性能压测>系列专题分享的第四期,该专题将从性能压测的设计.实现.执行.监控.问题定位和分析.应用场景等多个纬度对性能压测的全过程进行拆解,以帮助大家构建完整的性能压测的理论 ...
- [SCF+wetest+jmeter]简单云性能压测工具使用方案
前言 压测太难?局域网压力无法判断服务器网络指标?无法产生非常大的并发量?云性能太贵? 也许我们可以把各种简单的工具拼起来进行压力测试! 准备 https://cloud.tencent.com/pr ...
- EMQ X 系统调优和性能压测
前言 如果使用 EMQ 来承载百万级别的用户连接可以吗?毕竟在 MQTT 官方介绍上说 EMQ X 可以处理千万并发客户端,而 EMQ X 自己官方称 4.x 版本 MQTT 连接压力测试一台 8 核 ...
随机推荐
- bazel 使用 gtest/gmock 报错 Constraints from @bazel_tools//platforms have been removed
问题描述 运行 bazel test 命令,遇到错误:"Constraints from @bazel_tools//platforms have been removed. Please ...
- .NET开源免费功能最全的商城项目
前言 今天给大家推荐一个功能丰富.免费.灵活且可定制的开源电子商务解决方案:nopCommerce.大家假如有商城需求可以直接使用该项目进行二次开发,省时省力. 项目介绍 nopCommerce在.N ...
- NebulaGraph实战:2-NebulaGraph手工和Python操作
图数据库是专门存储庞大的图形网络并从中检索信息的数据库.它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上.本文以示例数据集basket ...
- 日常Bug排查-应用Commit报错事务并没有回滚
日常Bug排查-应用Commit报错事务并没有回滚 前言 日常Bug排查系列都是一些简单Bug排查,笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材_. 应用Commit报错并不一定回滚 事 ...
- 小熊派开发实践丨漫谈LiteOS之传感器移植
摘要:本文基于小熊派开发板简单介绍了如何在LiteOS中移植传感器,从而实现对于传感器的相关控制. 1 hello world 相信大家无论在学习编程语言开始的第一个函数应该是HelloWorld,本 ...
- 大数据场景下Volcano高效调度能力实践
摘要:本篇文章将会从Spark on Kubernetes 发展历程以及工作原理,以及介绍一下Spark with Volcano,Volcano如何能够帮助 Spark运行地更高效. Spark o ...
- 带你探索CPU调度的奥秘
摘要:本文将会从最基础的调度算法说起,逐个分析各种主流调度算法的原理,带大家一起探索CPU调度的奥秘. 本文分享自华为云社区<探索CPU的调度原理>,作者:元闰子. 前言 软件工程师们总习 ...
- 鲲鹏BoostKit虚拟化使能套件,让数据加密更安全
摘要:借助华为鲲鹏BoostKit虚拟化使能套件(简称鲲鹏BoostKit虚拟化),可加速迈向云计算之旅.本次KAE加速引擎让数据加密更安全直播将介绍鲲鹏BoostKit加速库全景,基于BoostKi ...
- Google Guava ListeningExecutorService
POM <!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> < ...
- 面对科技公司的制裁,俄罗斯放出封印7年的神兽:RuTracker
大家好,我是DD! 最近俄乌冲突引发的科技公司站队,Oracle.微软.三星等全球知名科技公司都开始对俄罗斯实施制裁与封锁.就连崇尚自由的开源社区GitHub也发文会严格限制俄罗斯获得维持其咄咄逼人的 ...