聊聊图数据库和图数据库的小知识 Vol.02

2010 年前后,对于社交媒体网络研究的兴起带动了图计算的大规模应用。
2000 年前后热门的是 信息检索 和 分析 ,主要是 Google 的带动,以及 Amazon 的 e-commerce 所用的协同过滤推荐,当时 collaborative filtering也被认为是 information retrieval 的一个细分领域,包括 Google 的 PageRank 也是在信息检索领域研究较多。后来才是 Twitter,Facebook 的崛起带动了网络科学 network science的研究。
图理论和图算法不是新科学,很早就有,只是最近 20 年大数据,网络零售和社交网络的发展, big data、social networks、e-commerce 、IoT让图计算有了新的用武之地,而且硬件计算力的提高和分布式计算日益成熟的支持也使图在高效处理海量关联数据成为可能。
上文摘录了#聊聊图数据库和图数据库小知识# Vol.01 的【图数据库兴起的契机】,在本次第二期#聊聊图数据库和图数据库小知识#我们将了解以下内容,如果有感兴趣的图数据库话题,欢迎添加 Nebula 小助手微信号:NebulaGraphbot 为好友进群来交流图数据库心得。
本文目录
- 图数据库和图数据库设计
- 传统数据库通过设计良好的数据结构是不是可以实现图数据库的功能
- 图数据库会出于什么考虑做存储计算分离
- 数据量小,业务量小的情况下,是否单机部署图数据库性能也不错。
- 图数据库 shared-storage 和 shared-nothing 的比较
- 图数据库顶点和边输出及超级顶点输出优化
- 如何处理图数据库中大数据量的点?
- Nebula Graph 实践细节
- Nebula Graph 元数据(Meta Service)使用 etcd 吗?
- Nebula Graph Cache 位于那一层
- Nebula Graph 集群中的 Partition 多大
- 如何理解 Nebula Graph Partition
️ 图数据库和图数据库设计
在这个部分,我们会摘录一些图数据库设计通用的设计思路,或者已有图数据库的实践思考。
传统数据库通过设计良好的数据结构是不是可以实现图数据库的功能
图数据库相对传统数据库优化点在于,数据模型。传统数据库是一个关系型,是一种表结构做 Join,但存储结构表明了很难支持多度拓展,比如一度好友,两度好友,一度还支持,使用一个 Select 和 Join 就可完成,但是二度查询开销成本较大,更别提多度 Join 查询开销更大。图数据库的存储结构为面向图存储,更利于查询多度关系。特别的,有些图上特有的操作,用关系型数据库比较难实现和表达,比如最短路径、子图、匹配特定规则的路径这些。
图数据库会出于什么考虑做存储计算分离
存储与计算分离主要出于以下四方面的考虑:
- 存储和计算资源可以独立扩展,使资源利用更充分,达到缩减成本的目的。
- 更容易利用异构机型。
- 解耦计算节点,计算资源可以更大程度地做到线性扩展。基于之前的项目经历,存储计算不分离的分布式架构,计算能力的水平扩展会比较不方便。举个例子,在好友关系这种场景——基于好友关系查询再做一些排序和计算,在某个节点查询执行过程中需要去其他节点获取数据,或者将某个子计算交给其他节点,如果执行过程中需要的数据存储在本地,相较存储计算分离效率可能会高;但当涉及到和其他节点通信问题时,为了扩容计算资源而增加的机器会使得计算过程中的网络开销相应增加,抵消了相当一部分的计算能力。如果存储计算分离,计算和存储一对一,不存在节点越多网络通讯开销越大的问题。
- Nebula Graph在存储层提供基于图的查询接口,但不具备运算能力,方便对接外部的批量计算,比如 Spark,可以将图存储层当作为图索引存储,直接批量扫描、遍历图自行计算,这样操作更灵活。存储层支持做一些简单的过滤计算,比如找寻 18 岁好友等过滤操作。
数据量小,业务量小的情况下,是否单机部署图数据库性能也不错。
单机按分布式架构部署,有一定网络开销因为经过网卡,所以性能还行。一定要分布式架构部署的原因在于强一致、多副本的业务需求,你也可以按照业务需求部署单副本。
图数据库 Shared-storage 和 Shared-nothing 的比较
【提问】对于图数据库来说,是不是 shared-storage 相比 shared-nothing 方式更好呢。因为图的节点间是高度关联的,shared-nothing 方式将这种联系拆掉了。对于多步遍历等操作来说,需要跨节点。而且由于第二步开始的不确定性,要不要跨节点好像没法提前通过执行计划进行优化。
【回复】交流群群友 W:errr,单个 storage 能不能放下那么多数据,特别数据量增加了会是个比较麻烦的问题。另外第二步虽然是随机的,但是取第二步数据的时候可以从多台机器并发
【回复】交流群群友 W:主要的云厂商,比如 AWS 的共享存储可以到 64 T,存储应该够,而且这种方式存储内部有多副本。顺便提一句:AWS 的 Neptune 的底层存储用的也是 Aurora 的那个存储。网络这块的优化,可参考阿里云的 Polarstore,基本上网络已经不是什么问题了。
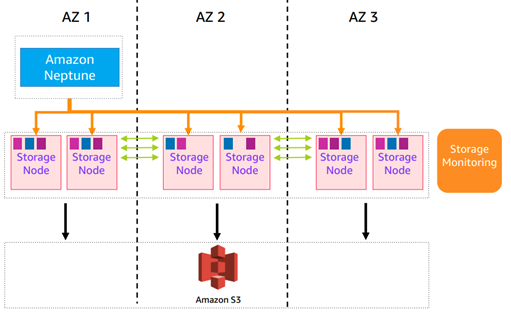
此外,“第二步虽然是随机的,但是取第二步数据的时候可以从多台机器并发吧”这个倒是,Nebula 有个 storage server 可以做这个事情,但逻辑上似乎这个应该是 query engine 应该干的。
【回复】交流群群友 W:“网络这块的优化,可参考阿里云的 polarstore,基本上网络已经不是什么问题了。” 网络这问题,部署环境的网络不一定可控,毕竟机房质量参差不齐,当然云厂商自己的机房会好很多。
【回复】交流群群友 W:这个确实。所以开源的创业公司走 shared-nothing,云厂商走 shared-storage,也算是都利用了各自的优势
【回复】交流群群友 S:其实,shared-storage 可以被看成是一个存储空间极大的单机版,并不是一个分布式系统
【回复】交流群群友 W:嗯嗯。不过 Neptune 那种跟单机版的区别在于计算那部分是可扩展的,一写多读,甚至 Aurora 已经做到了多写。不过就像前面所说的,开源的东西基于那种需定制的高大上存储来做不现实。想了下拿 AWS 的存储做对比不大合适,存储内部跨网络访问的开销还是一个问题,拿 Polarstore 这种 RDMA 互联更能说明。可能 2 种方案都差不多,本质上都是能否减少跨网络访问的开销。
图数据库顶点和边输出及超级顶点输出优化
【提问】请教一个问题。Nebula 的顶点和出边是连续存放的。那么在查询语句进行 IO 读取时,是顶点和出边会一起读出来呢,还是根据查询语句的不同而不同?
【回复】交流群群友 W:会一个 block 一起读出来
【回复】交流群群友 W:恩恩。对于 supernode 这种情况,有没有做什么优化?Titian/Janusgraph 有一个节点所有边的局部索引,Neo4j 应该有在 object cache 中对一个节点的边按照类型组织
【回复】交流群群友 S:Nebula 也是用 index 来解决这个问题
【回复】交流群群友 W:Neo4j 的 relationship group 是落在存储上的,请教下,Nebula 的这种 index 和 Janusgraph 的 vertex centric 索引类似麽,还是指存储格式里面的 ranking 字段啊
【回复】交流群群友 S:类似于 Janusgraph 的索引,但是我们的设计更 general,支持 multi-column 的索引
【回复】交流群群友 W:ranking 字段其实给客户用的,一般可以拿来放时间戳,版本号之类的。
如何处理图数据库中大数据量的点?
【提问】:Nebula 的存储模型中属性和边信息一起存储在顶点上,针对大顶点问题有好的解决方案吗?属性和关系多情况下,针对这种实体的查询该怎么处理,比如:比如美国最有名的特产,中国最高的人,浙江大学年龄最大的校友
【回复】交流群群友 W:如果可以排序,那分数可以放在 key 上,这样其实也不用 scan 太多了,ranking 字段就可以放这个。要不然还有个办法是允许遍历的过程中截断或者采样,不然很容易爆炸的。
【回复】交流群群友 B:在做实时图数据库的数据模型设计时,尽量避免大出入度的节点。如果避免不了,那至少避免此类节点再往后的 traversal。如果还是避免不了,那别指望这样的查询会有好的性能
【回复】交流群群友 H:单纯的大点如果不从它开始 traversal,其实问题也不大。load 的 unbalance 都是有办法解决的。数据的 unbalance 因为分 part 存储,在分配 part 到 host 时可加入 part 数据量的权重,而 load 的 unbalance,对于读,可通过拓展只读副本 + cache 解决,写的话,可做 group commit,client 也可以做本地 cache。
【回复】交流群群友 B:图数据库的一个查询的性能最终取决于 physical block reads 的数量。不同方案会导致最后 block reads 不一样,性能会有差别。任何一种方案不可能对所有查询都是优化的,最终往往就是 tradeoff。主要看你大部分实际的 query pattern 和数据分布式如何,该数据库实现是否有优化。拆边和不拆边,各有其优缺点。
Nebula Graph 实践细节
在这个部分我们会摘录一些开源的分布式图数据库 Nebula Graph 在实践过程中遇到的问题,或者用户使用图数据库 Nebula Graph 中遇到的问题。
Nebula Graph 元数据(Meta Service)使用 etcd 吗?
不是。Meta Service的架构其实和 Storage Service 架构类似,是个独立服务。
Nebula Graph Cache 位于哪一层
A:KV 那层。目前只有针对顶点的 Cache,顶点的访问具有随机性,如果没有 Cache,性能较差。Query Plan 那层现在还没有。
如何理解 Nebula Graph Partition
partition 是个逻辑概念,主要目的是为了一个 partition 内的数据可以一起迁移到另外一台机器。partition 数量是由创建图空间时指定的 partition_num 确立。而单副本 partition 的分布规则如下
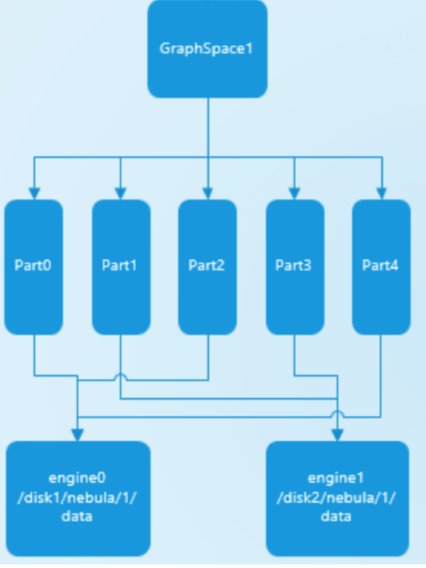
通过算子:partID%engine_size,而多副本的情况,原理类似,follower 在另外两个机器上。
Nebula Graph 集群中的 Partition 多大
A:部署集群时需要设置 Partition 数,比如 1000 个 Partition。插入某个点时,会针对这个点的id做 Hash,找寻对应的 Partition 和对应 Leader。PartitionID 计算公式 = VertexID % num_Partition
单个 Partition 的大小,取决于总数据量和 Partition 个数;Partition 的个数的选择取决于集群中最大可能的机器节点数,Partition 数目越大,每个 Partition 数据量越小,机器间数据量不均匀发生的概率也就越小。
最后,这里是开源的分布式图数据库 Nebula Graph 的 GitHub 地址:https://github.com/vesoft-inc/nebula,欢迎给我们提 issue~~
推荐阅读

聊聊图数据库和图数据库的小知识 Vol.02的更多相关文章
- 设计数据库 ER 图太麻烦?不妨试试这两款工具,自动生成数据库 ER 图!!!
忙,真忙 点赞再看,养成习惯,微信搜索『程序通事』,关注就完事了! 点击查看更多精彩的文章 这两个星期真是巨忙,年前有个项目因为各种莫名原因,一直拖到这个月才开始真正测试.然后上周又接到新需求,马不停 ...
- mysql快速导出数据库ER图和数据字典(附navicat11安装教程及资源)
♣ mysql使用navicat11快速导出数据库ER图 ♣ mysql使用navicat11快速导出数据库数据字典 ♣ navicat11 for mysql (这里是mysql5.7.12)专业版 ...
- 如何图形化创建oracle数据库
需要注意的几点 1.如果用oracle客户端访问服务器的话必须把服务器的主机名写成(计算机的名称)Oracle创建数据库的方法 2.navigate如何远程oracle数据库 E:\app\lenov ...
- 用mysql workbench导出mysql数据库关系图
用mysql workbench导出mysql数据库关系图 1. 打开mysql workbench,选择首页中间"Data Modeling"下方的第二栏"Create ...
- Oracle数据库及图形化界面安装教程详解
百度云盘oracle数据库及图形化界面安装包 链接: https://pan.baidu.com/s/1DHfui-D2n1R6_ND3wDziQw 密码: f934 首先在电脑D盘(或者其他不是C盘 ...
- 新人浅谈__(数据库的设计__数据库模型图,数据库E-R图,三大范式)
>>>> 为什么需要规范的数据库设计 在实际的项目开发中,如果系统的数据存储量较大,设计的表比较多,表和表之间的关系比较复杂,就需要首先考虑规范的数据库设计,然后进行创建库, ...
- 《GO Home Trash!》UML类图,ER图以及数据库设计
<Go Home Trash!>UML类图 ER图以及数据库中数据表 分析: 这款软件经过我们前期的讨论以及需求分析,确定了用户,客服以及管理员三个实体.在设计UML类图时,对各个实体之间 ...
- mysql数据库E-R图
学会绘制E-R图 绘制E-R图首先要了解什么是实体,什么是属性,什么是联系. 1.首先实体是指现实世界中具有区分其他事物的特征或属性与其他实体有联系的实体,针对于数据库中的表而言实体是指表中一行一行特 ...
- 数据库设计规范、E-R图、模型图
(1)数据库设计的优劣: 糟糕的数据库设计: ①数据冗余冗余.存储空间浪费. ②数据更新和插入异常. ③程序性能差. 良好的数据库设计 ①节省数据的存储空间. ②能够保证数据的完整新. ③方便进行数据 ...
- SQL Server 新建 数据库关系图 时弹出警告提示此数据库没有有效所有者,因此无法安装数据库关系图支持对象。
今天创建数据库关系图,发现提示此数据库没有有效所有者,因此无法安装数据库关系图支持对象.若要继续,请首先使用 数据库属性 对话框的文件页或 ALTER AUTHORIZAITION 语句将数据库所有者 ...
随机推荐
- js遍历树形结构并返回所有的子节点id值
场景 很多时候我么需要返回返回tree结构下的所有自己节点 很显然这个时候需要遍历了 废话不多说 直接递归遍历 数据结构 var treeData = [{ id: 111, title: " ...
- Ant Design Vue分页Pagination
<template> <div> <a-pagination show-quick-jumper v-model:current="current1" ...
- 【k哥爬虫普法】简历大数据公司被查封,个人隐私是红线!
我国目前并未出台专门针对网络爬虫技术的法律规范,但在司法实践中,相关判决已屡见不鲜,K 哥特设了"K哥爬虫普法"专栏,本栏目通过对真实案例的分析,旨在提高广大爬虫工程师的法律意识, ...
- [1] HEVD 学习笔记:HEVD 环境搭建
1. HEVD 概述 + 环境搭建 HEVD作为一个优秀的内核漏洞靶场受到大家的喜欢,这里选择x86的驱动来学习内核漏洞,作为学习笔记记录下来 实验环境 环境 备注 调试主机操作系统 Window ...
- MySQL【二】---数据库查询详细教程{查询、排序、聚合函数、分组}
1.数据准备.基本的查询(回顾一下) 创建数据库 create database python_test charset=utf8; 查看数据库: show databases; 使用数据库: use ...
- 火遍外网的Keychron测评,带你入坑;ps马上5.20了送一个给你的心爱的她/他。
那些年用过的机械键盘 如果你经常上YouTube或Instagram,然后你又对键盘感兴趣,我相信你肯定看到过他--Keychron K2,他真的是一款曝光量很高的键盘. 1.键盘keychron k ...
- Linux 文件目录操作命令
Linux 基础的文件目录操作命令,融合多部Linux经典著作,去除多余部分,保留实用部分. 显示目录或文件: 显示目标列表,在Linux系统中是使用率较高的命令.ls命令的输出信息可以进行彩色加亮显 ...
- ASP.NET Core 6.0+Vue.js 3 实战开发(视频)
大家好,我是张飞洪,感谢您的阅读,我会不定期和你分享学习心得,希望我的文章或视频能成为你成长路上的垫脚石. 录制视频的体验 这是一个收费的视频,很抱歉,让您失望了. 我尝试做点收费的视频,不是因为我不 ...
- Sea-Search03总结&&un finish
使用到的设计模式 Facade门面模式 为何使用? 在搜索项目中,由于使用Mvc架构且数据库中各种不同类型的数据源并没有放在同一张表,于是我们不可避免的在Controller中需要注入多个servic ...
- MySQL百万级数据大分页查询优化的实现
前言:在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取. 一.MySQL分页起点越大查询速度越慢 直接用limit start, cou ...