mysql中联合查询
联合查询union
一个翻译问题的解释:
在mysql的手册中,将连接查询(Join)翻译为联合查询;
而联合查询(union),没有明确翻译。
但:
在通常的书籍或文章中,join被翻译为“连接”查询;而union才被翻译为联合查询。
基本概念
将两个具有相同字段数量的查询语句的结果,以“上下堆叠”的方式,合并为一个查询结果。
图示如下:
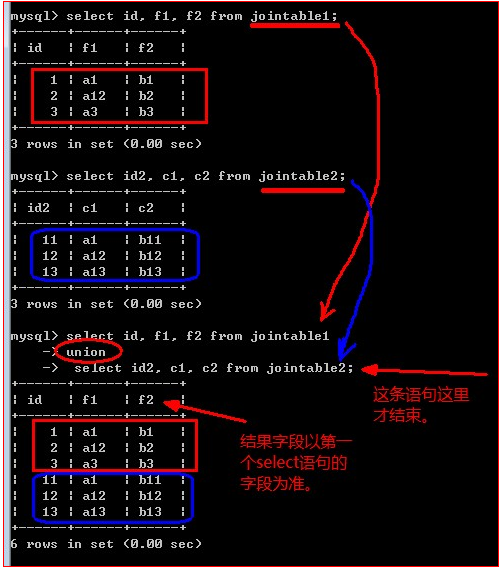
可见:
1,两个select语句的查询结果的“字段数”必须一致;
2,通常,也应该让两个查询语句的字段类型具有一致性;
3,也可以联合更多的查询结果;
语法形式
select 语句1
union 【all | distinct】
select 语句2;
此联合查询语句,默认会“自动消除重复行”,即默认是distinct
如果想要将所有数据都显示(允许重复行),就使用all
即,这里,写all才有意义;
对比普通select语句:
select 【all | distinct】 。。。。
对于select语句,写distinct才有意义;
细节:
应该将这个联合查询的结果理解为最终也是一个“表格数据”,且默认使用第一个select语句中的字段名;
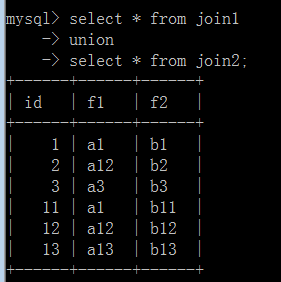 对比
对比 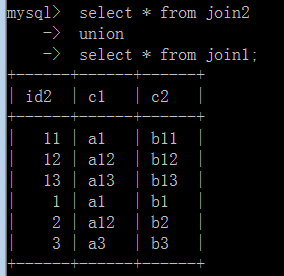
默认情况下,order by子句和limit子句只能对整个联合之后的结果进行排序和数量限定:select... union select... order by XXX limit m,n;
基本用法:
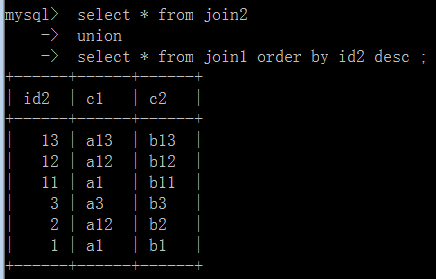
不对的做法:

无效的做法:
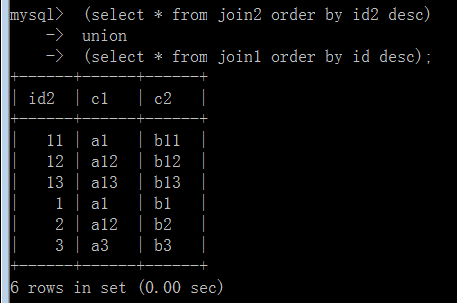
如果第一个select语句中的列有别名,则order by子句中就必须使用该别名。

修改为:
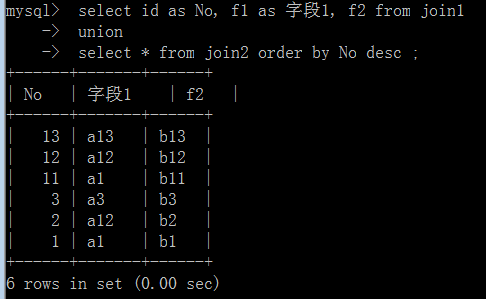
最后,来一个“应用”:
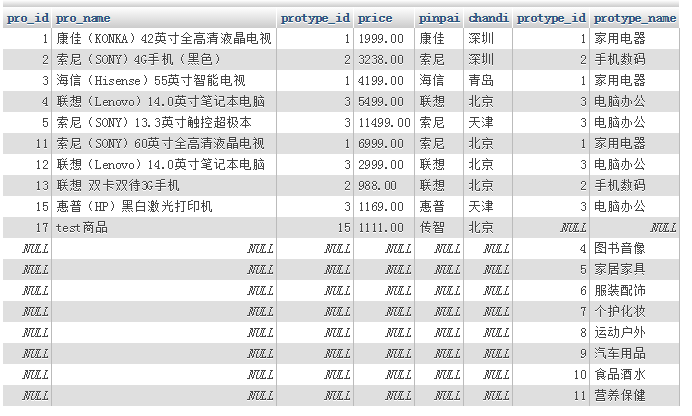
实现“全外连接”:
select * f rom 表1 left join 表2 on 条件
union
select * f rom 表1 right join 表2 on 条件

结果为:
mysql中联合查询的更多相关文章
- MySQL 中联合查询效率分析
目前我有两个表,一个keywords和一个news表.keyword存放关键词是从news中提取,通newsid进行关联,两表关系如图: keywords中存有20万条数据,news中有2万条数据,现 ...
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
- mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- 【原创】7. MYSQL++中的查询结果获取(各种Result类型)
在本节中,我将首先介绍MYSQL++中的查询的几个简单例子用法,然后看一下mysqlpp::Query中的几个与查询相关的方法原型(重点关注返回值),最后对几个关键类型进行解释. 1. MYSQL++ ...
- mysql中如何查询最近24小时、top n查询
MySQL中如何查询最近24小时. where visittime >= NOW() - interval 1 hour; 昨天. where visittime between CURDATE ...
- Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 1 2 3 SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM ...
- mysql中in查询中排序
mysql中in查询条件的时候,很多时候排序是不规则的,如何按照in里面的条件进行排序呢? mysql中给出了办法,在in后面加order by field,order by field的首个条件是按 ...
- 下面介绍mysql中模糊查询的四种用法:
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- 【面经】面试官:如何以最高的效率从MySQL中随机查询一条记录?
写在前面 MySQL数据库在互联网行业使用的比较多,有些小伙伴可能会认为MySQL数据库比较小,存储不了很多的数据.其实,这些小伙伴是真的不了解MySQL.MySQL的小不是说使用MySQL存储的数据 ...
随机推荐
- 【 C 】字符串常量
当一个字符串常量出现在表达式中时,它的值是个指针常量.编译器把这些指定字符的一份拷贝存储在内存的某个位置,并存储一个指向第一个字符的指针.但是,当数组名用于表达式中时,它们的值也是个指针常量.我们可以 ...
- Linux入门进阶第一天——vim文本编辑器
一.VI / VIM概述 [更新]:VIM资料参见:http://www.runoob.com/linux/linux-vim.html 是什么? 是一个文本编辑器. Vim是从 vi 发展出来的一个 ...
- mysql的启动,停止与重启
启动mysql:方式一:sudo /etc/init.d/mysql start 方式二:sudo start mysql方式三:sudo service mysql start 停止mysql:方式 ...
- KDTable如何添加合计行?
/** * 功能:添加合计行 * * @param table * 指定的KDTable * @param fields * 需要合计的列 */ public static void apendFoo ...
- 1111: [POI2007]四进制的天平Wag
1111: [POI2007]四进制的天平Wag 链接 题意: 用一些四进制数,相减得到给定的数,四进制数的数量应该尽量少,满足最少的条件下,求方案数. 分析: 这道题拖了好久啊. 参考Claris的 ...
- cdh中hdfs非ha环境迁移Namenode与secondaryNamenode,从uc机器到阿里;
1.停掉外部接入服务: 2 NameNode Metadata备份: 2.1 备份fsimage数据,(该操作适用HA和非HA的NameNode),使用如下命令进行备份: [root@cdh01 df ...
- MySQLdb in Python: “Can't connect to MySQL server on 'localhost'”
因为我使用的是win64,所以在此系统下,需要设置为 127.0.0.1 #coding=utf-8 import MySQLdb if __name__ == '__main__': # 打开数据库 ...
- 搜索引擎ElasticSearch系列(二): ElasticSearch2.4.4 Head插件安装
一:ElasticSearch Head插件简介 elasticsearch-head is a web front end for browsing and interacting with an ...
- XAF-物料管理信息工作日志
前段时间已经开始了第一阶段验收了,客户方并未把重点放在业务流程上面,一直在调整一些界面问题.有点小纠结. 今天要调一下菜单位置. 没修改时,是这样的: 到了列表界面,会多一个全文检索出来. 后来,客户 ...
- 探究linux设备驱动模型之——platform虚拟总线(二)
上回说到,platform_match是驱动和设备之间的媒人婆,那么platform_match是如何匹配驱动和设备的呢?platform总线定义的匹配条件很简单,主要就是查看驱动结构体和设备结构体的 ...