Hive之 hive-1.2.1 + hadoop 2.7.4 集群安装
一、 相关概念
Hive Metastore有三种配置方式,分别是:
Embedded Metastore Database (Derby) 内嵌模式
Local Metastore Server 本地元存储
Remote Metastore Server 远程元存储
1.1 Metadata、Metastore作用
metadata即元数据。元数据包含用Hive创建的database、tabel等的元信息。
元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
1.2三种配置方式区别
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
本地元存储和远程元存储都采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.在这里我们使用MySQL。
本地元存储和远程元存储的区别是:本地元存储不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。远程元存储需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程元存储的metastore服务和hive运行在不同的进程里。
在生产环境中,建议用远程元存储来配置Hive Metastore。
前提: 已经安装好三个节点的 hadoop 集群,参考 http://blog.csdn.net/zhang123456456/article/details/77621487
这里选用mySql作为元数据库,将mySql和Hive安装在master服务器上
统一给放到/usr/local/hadoop
1.下载安装文件,并解压:
cd /usr/local/hadoop
wget http://mirrors.cnnic.cn/apache/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/hadoop
-- 如果 hive 有专属的用户,记得赋权
sudo chown -R XXX:XXX /usr/local/hadoop/apache-hive-1.2.1-bin
2.设置环境变量
sudo vim /etc/profile
在最后加上
export HIVE_HOME=/usr/local/hadoop/apache-hive-1.2.1-bin(这儿是你的hive的解压路径)
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile ->使配置文件生效
安装mysql , 参考 http://blog.csdn.net/zhang123456456/article/details/53608554 ,注意MySQL数据库不能设置为BINLOG_FORMAT = STATEMENT,否则报Cannot execute statement: impossible to write to binary log 。
3. 在 mysql 数据库中创建 hive 专属数据库 与 用户
mysql -u root -p ->输入之后会提示你输入之前你设置的root密码
create database hiveDB; -> 建立数据库
create user 'hive' identified by 'hive'; ->创建用户
grant all privileges on hivedb.* to 'hive'@'%' identified by 'hive'; ->将允许从任意地点登陆的hive用户对hiveDB数据库的所有表执行增删查改四种操作
flush privileges; -> 刷新系统权限表
4.拷贝JDBC驱动包
将mySql的JDBC驱动包复制到Hive的lib目录下
cp mysql-connector-java-5.1.34-bin.jar /usr/local/hadoop/apache-hive-1.2.1-bin/lib
5.修改Hive配置文件:
cd apache-hive-1.2.1-bin/conf/
cp hive-default.xml.template hive-site.xml
vi hive-site.xml #修改相应配置
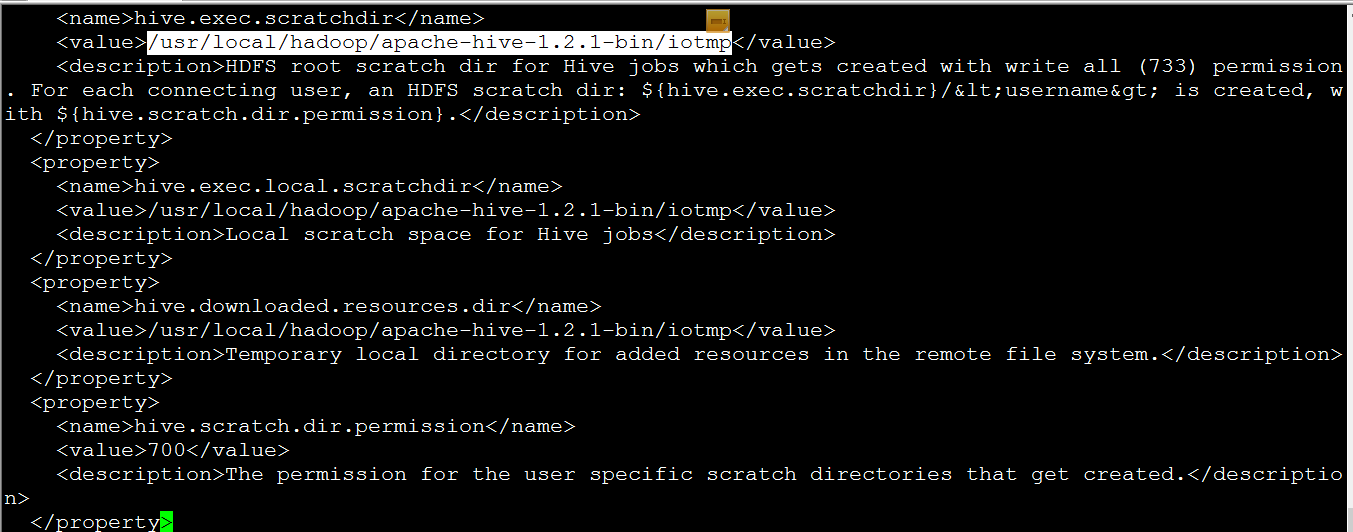
hive.exec.scratchdir ## 所有${system: java.io.tmpdir}和@{system:user.name} 都替换掉
java.io.tmpdir}和@{system:user.name} 都替换掉
/usr/local/hadoop/apache-hive-1.2.1-bin/iotmp
javax.jdo.option.ConnectionURL
jdbc:mysql://HadoopMaster:3306/hivedb?useUnicode=true&characterEncoding=UTF-8&createDatabaseIfNotExist=true
jdbc:mysql://hadp-master:3306/hivedb?useUnicode=true&createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
hive.metastore.warehouse.dir
/user/hive/warehouse
location of default database for the warehouse


说明:
hive.exec.scratchdir->执行HIVE操作访问HDFS用于临时存储数据的目录。目录权限设置为733。我这儿用的是/tmp/hive目录。
javax.jdo.option.ConnectionURL -> 设置hive通过JDBC链接MYSQL数据库存储metastore存放的数据库地址
javax.jdo.option.ConnectionDriverName ->设置链接mysql的驱动名称。
javax.jdo.option.ConnectionUserName -> 设置存储metastore内容的数据库用户名
javax.jdo.option.ConnectionPassword -> 设置存储metastore内容的数据库用户名密码
hive.metastore.warehouse.dir -> 设置用于存放hive元数据的目录位置,改配置有三种模式,内嵌模式,本地元数据,远程元数据。如果hive.metastore.uris是空,则是本地模式。否则则是远程模式。
②配置hive-env.sh,这个文件也是没有的,是hive-env.sh.template复制过来的
sudo cp hive-env.sh.template hive-env.sh
sudo vim hive-env.sh
将jdk的路径和hadoop的家目录导入到这个文件中:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4/
6.分发Hive分别到slave1,slave2上
scp -r /usr/local/hadoop/apache-hive-1.2.1-bin hadp-node1:/usr/local/hadoop/
scp -r /usr/local/hadoop/apache-hive-1.2.1-bin hadp-node2:/usr/local/hadoop/
配置环境变量如同master。
7.测试Hive
进入到Hive的安装目录,命令行:
cd $HIVE_HOME/bin
./hive --service metastore &
./hive --service hiveserver2 &
./hive
hive> show tables;
OK
Time taken: 1.995 seconds
Hive之 hive-1.2.1 + hadoop 2.7.4 集群安装的更多相关文章
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
- hadoop 2.2.0集群安装
相关阅读: hbase 0.98.1集群安装 本文将基于hadoop 2.2.0解说其在linux集群上的安装方法,并对一些重要的设置项进行解释,本文原文链接:http://blog.csdn.net ...
- Hadoop 2.6.1 集群安装配置教程
集群环境: 192.168.56.10 master 192.168.56.11 slave1 192.168.56.12 slave2 下载安装包/拷贝安装包 # 存放路径: cd /usr/loc ...
- Hadoop 2.4.x集群安装配置问题总结
配置文件:/etc/profile export JAVA_HOME=/usr/java/latest export HADOOP_PREFIX=/opt/hadoop-2.4.1 export HA ...
- CentOS系统下Hadoop 2.4.1集群安装配置(简易版)
安装配置 1.软件下载 JDK下载:jdk-7u65-linux-i586.tar.gz http://www.oracle.com/technetwork/java/javase/downloads ...
- Hadoop完全高可用集群安装
架构图(HA模型没有SNN节点) 用vm规划了8台机器,用到了7台,SNN节点没用 NN DN SN ZKFC ZK JNN RM NM node1 * * node2 * ...
- Hadoop 2.5.1集群安装配置
本文的安装只涉及了hadoop-common.hadoop-hdfs.hadoop-mapreduce和hadoop-yarn,并不包含HBase.Hive和Pig等. http://blog.csd ...
- hadoop 2.7.3 集群安装
三台虚拟机,centos6.5 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 :: loca ...
- hadoop 1.0.1集群安装及配置
1.hadoop下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/core/ 2.下载java6软件包,分别在三台安装 3.三台虚拟机,一台作为mast ...
随机推荐
- php 用户向微信发送信息
1:制作微信菜单栏 <?phpheader("Content-type: text/html; charset=utf-8");function request_post($ ...
- [置顶] SNMPv3认证和加密过程
前面的一些文章详细讲解了SNMPv3的报文内容,下面主要的内容就是SNMPv3的加密和认证过程! USM的定义为实现以下功能: 鉴别 数据加密 密钥管理 时钟同步化 避免延时和重播攻击 1.UsmSe ...
- Python3:Requests模块的异常值处理
Python3:Requests模块的异常值处理 用Python的requests模块进行爬虫时,一个简单高效的模块就是requests模块,利用get()或者post()函数,发送请求. 但是在真正 ...
- RocEDU.阅读.写作《苏菲的世界》书摘(六)
* 身为一个经验主义者,休姆期许自己要整理前人所提出的一些混淆不清的思想与观念,包括中世纪到十七世纪这段期间,理性主义哲学家留传下来的许多言论和著作.休姆建议,人应回到对世界有自发性感觉的状态.他说, ...
- 操作数据库的时候,使用自带的DbProviderFactory类 (涉及抽象工厂和工厂方法)
微软自带的DbProviderFactory https://msdn.microsoft.com/en-us/library/system.data.common.dbproviderfactory ...
- SDOI2011_染色
SDOI_染色 背景:很早就想学习树链剖分,趁着最近有点自由安排的时间去学习一下,发现有个很重要的前置知识--线段树.(其实不一定是线段树,但是线段树应该是最常见的),和同学吐槽说树剖的剖和分都很死板 ...
- BZOJ 1566 【NOI2009】 管道取珠
题目链接:管道取珠 这道题思路还是很巧妙的. 一开始我看着那个平方不知所措……看了题解后发现,这种问题有一类巧妙的转化.我们可以看成两个人来玩这个游戏,那么答案就是第二个人的每个方案在第一个人的所有方 ...
- Hadoop平台的基本组成与生态系统
Hadoop系统运行于一个由普通商用服务器组成的计算集群上,该服务器集群在提供大规模分布式数据存储资源的同时,也提供大规模的并行化计算资源. 在大数据处理软件系统上,随着Apache Hadoop系统 ...
- Vue 组件设计
Vue 组件设计 Vue 作为 MVVM 框架一员,不管是写业务还是基础服务,都少不了书写组件.本文总结一下书写业务组件的一些心得. 为什么要写组件? 我们知道,只要是组件,就需要在引用的时候与 vi ...
- Java IO流-合并流
2017-11-05 20:15:28 SequenceinputStream SequenceinputStream:SequenceInputStream 表示其他输入流的逻辑串联.它从输入流的有 ...