使用python操作HDF5文件
HDF
Hierarchical Data Format,又称HDF5
在深度学习中,通常会使用巨量的数据或图片来训练网络。对于如此大的数据集,如果对于每张图片都单独从硬盘读取、预处理、之后再送入网络进行训练、验证或是测试,这样效率太低。如果将这些图片都放入一个文件中再进行处理效率会更高。有多种数据模型和库可完成这种操作,如HDF5和TFRecord。
一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,存放dataset和其他group。在使用h5py的时候需要牢记一句话:groups类比词典,dataset类比Numpy中的数组。
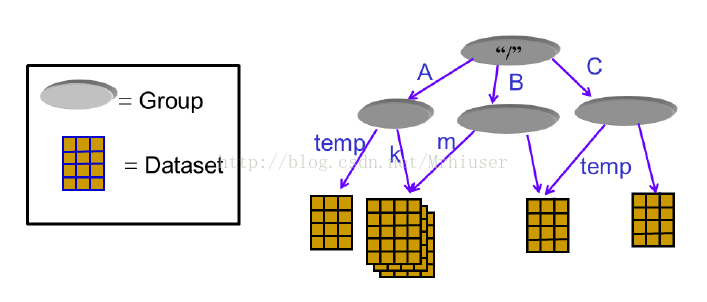
HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。HDF5 文件结构中有 2 primary objects: Groups 和 Datasets。
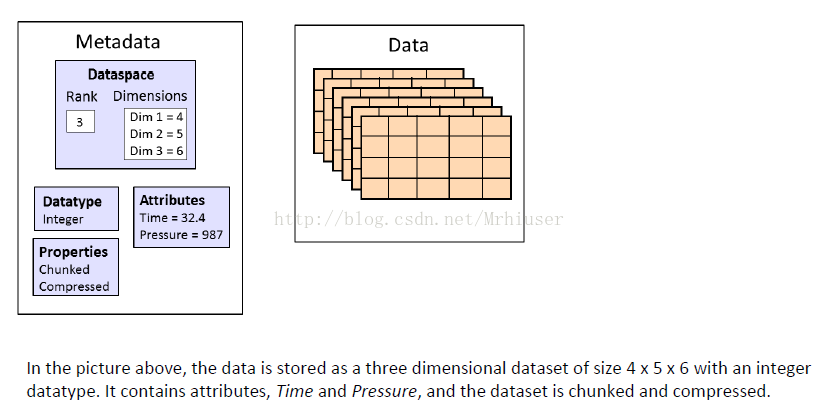
每个 dataset 可以分成两部分: 原始数据 (raw) data values 和 元数据 metadata (a set of data that describes and gives information about other data => raw data)。对于每一个dataset 而言,除了数据本身之外,这个数据集还会有很多的属性 attribute,。在hdf5中,还同时支持存储数据集对应的属性信息,所有的属性信息的集合就叫做metadata.
安装:
pip install h5py
对于数据集需要: 先创建h5文件,再去读h5文件 将dataset放在group里利用group进行层次嵌套.
1 f = filename.file得到文件的根目录
2 f.create_group("...../group_name")
3 f.create_dataset("...../dataset_name")
一般:
HDF5格式文件保存的是 : Model weights(字典,没有顺序)
JSON 和 YAML 格式文件保存的是: Model structure(顺序靠json描述)
h5格式:可以同时保存weights和structure
利用numpy数据初始化
1 #还可以直接用np数组给dataset初始化,此时data就涵盖了shape和dtype,即shape = data.shape,....
2 arr = np.arange(100)
3 dset = f.create_dataset("/mydataset1",data = arr)#i4:32位的integer[-2^31,2^31]
数据处理上的用途
利用python的文件操作及数组等方式将训练数据及测试数据集标签,按数据划分方法,将文件名写入到python数组,最终将这些处理好的数组写入hdf5格式文件给dataset初始化.
示例
1 import h5py
2 import numpy as np
3 coco = h5py.File("D:/annot_coco.h5","r")#coco.name == / 根节点
4 # print(coco)
5 # print(coco["bndbox"])
6 #只是遍历直接相连的一级节点
7 for name in coco:
8 # 本身就是字符串
9 print(coco[name])
10 print(coco[name][:2])
11
12 # def printname(name):
13 # print(name)
14 #
15 #
16 #
17 # #遍历整个coco下的节点
18 # coco.visit(printname)
19 #dataset.attrs
20 #dataset对象可以有自己的属性, 但所有属性数据的长度加起来不能超过64K, 包括属性名字.
21
22 dset.attrs['length'] = 100
23 dset.attrs['name'] = 'This is a dataset'
24 for attr in dset.attrs:
25 print attr, ":", dset.attrs[attr]
26 length : 100
27 name : This is a dataset
注意:
1 imgname_array = coco["imgname"][:]#不一样的,这是标准用法,还是要先取到全部,再去索引,否则结果维度不一样
2 # imgname_ = coco["imgname"][:1]#轴不会减少
3 # print(imgname_array.shape)
4 # print(imgname_)#[1,16]
5 # print(type(imgname_dataset))
6 # print(type(imgname_array))
7 img = imgname_array[0]
写字符串到h5文件
1 test_h5 = h5py.File("D:/test.h5","w")
2 imgname = np.fromstring('000000262145.jpg',dtype=np.uint8).astype('float64')#str_imgname------>float64
3 test_h5 .create_dataset('imgname', data=imgname)#变成f8之后就可以直接往h5中写了
4 test_h5.close()
5 """
6 最后得出来的矩阵长度是字符串的长度。---1个字符串的长度就是对应编码的h5向量的长度
7 如果想将多个字符串拼成一个大的numpy矩阵,写到h5文件中,必须先将字符串转换成相同长度。
8 通常的做法是在字符串后面补上\x00。
9 """
从h5数据读出字符串格式
1 test_h5 = h5py.File("D:/test.h5","r")
2 img = test_h5['imgname'][:]
3 img = img.astype(np.uint8).tostring().decode('ascii')
4 print(img)
5 test_h5.close()
使用python操作HDF5文件的更多相关文章
- Python操作Zip文件
Python操作Zip文件 需要使用到zipfile模块 读取Zip文件 随便一个zip文件,我这里用了bb.zip,就是一个文件夹bb,里面有个文件aa.txt. import zipfile # ...
- 使用h5py操作hdf5文件
HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件.HDF 最早由美国国家超级计算应用中心 NCSA 开发,目前在非盈利组织 HDF ...
- python操作txt文件中数据教程[4]-python去掉txt文件行尾换行
python操作txt文件中数据教程[4]-python去掉txt文件行尾换行 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文章 python操作txt文件中数据教程[1]-使用pyt ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- python操作txt文件中数据教程[2]-python提取txt文件
python操作txt文件中数据教程[2]-python提取txt文件中的行列元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果-将txt中元素提取并保存在c ...
- python操作txt文件中数据教程[1]-使用python读写txt文件
python操作txt文件中数据教程[1]-使用python读写txt文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果 程序实现 filename = '. ...
- python 操作Excel文件
1 安装xlrd.xlwt.xlutils cmd下输入: pip install xlrd #读取excel pip install xlwt #写入excel pi ...
- python操作xml文件
一.什么是xml? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. abc.xml <?xml version="1.0&q ...
- Python操作yaml文件
基本的yaml语法 http://ansible-tran.readthedocs.io/en/latest/docs/YAMLSyntax.html YAML 还有一个小的怪癖. 所有的 YAML ...
随机推荐
- Selenium多浏览器处理 (Chrome/Firefox/IE)
测试用例文件:test_selenium/test_hogwarts.py 使用pytest框架 定义一个变量,通过外部传入变量,确定使用哪个浏览器 browser = os.getenv(" ...
- three.js 材质翻转
刚学.这个鸟玩意儿卡了半天,记录一下. var skyBox = new THREE.Mesh(skyGeometry, skyMaterial); //创建一个完整的天空盒,填入几何模型和材质的参数 ...
- 鸿蒙内核源码分析(物理内存篇) | 怎么管理物理内存 | 百篇博客分析OpenHarmony源码 | v17.01
百篇博客系列篇.本篇为: v17.xx 鸿蒙内核源码分析(物理内存篇) | 怎么管理物理内存 | 51.c.h .o 内存管理相关篇为: v11.xx 鸿蒙内核源码分析(内存分配篇) | 内存有哪些分 ...
- P4240-毒瘤之神的考验【莫比乌斯反演,平衡规划】
正题 题目链接:https://www.luogu.com.cn/problem/P4240 题目大意 \(Q\)组数据给出\(n,m\)求 \[\sum_{i=1}^n\sum_{j=1}^m\va ...
- Javascript 常见的高阶函数
高阶函数,英文叫 Higher Order function.一个函数可以接收另外一个函数作为参数,这种函数就叫做高阶函数. 示例: function add(x, y, f) { return f( ...
- 微服务Cloud整体聚合工程创建过程
1.父工程创建及使用 使用idea开发工具,选择File-new- project ,在选项中选择Maven工程,选择jdk版本1.8,勾选maven-archetype-site,点击next,输入 ...
- 打开属性页,分别在Debug和Release下将其配置类型改为:静态库(.lib);
右键工程->属性 配置类型里面的下拉菜单选择静态库
- 洛谷3721 HNOI2017单旋(LCT+set+思维)
这题难道不是spaly裸题吗? 言归正传QWQ 一看到这个题目,其实第一反应是很懵X的 从来没有见过类似的题目啊,什么\(spaly\),单旋.QWQ很懵逼啊 不过,我们可以注意到这么一件事情,就是我 ...
- uoj21 缩进优化(整除分块,乱搞)
题目大意: 给定一个长度为\(n\)的序列 让你找一个\(x\),使得\(ans\)尽可能小 其中$$ans=\sum_{i=1}^{n}\lfloor\frac{a_i}{x}\rfloor + \ ...
- MySQL中如何选择合适的备份策略和备份工具
数据库备份的重要性毋庸置疑,可以说,它是数据安全的最后一道防线.鉴于此,对于备份,我们通常会做以下要求: 多地部署 对于核心数据库,我们通常有两地三中心的部署要求.对于备份来说,也是如此. 一个备份 ...