delta源码阅读
阅读思路:
1、源码编译
2、功能如何使用
3、实现原理
4、源码阅读(通读+记录+分析)
源码结构
源码分析
元数据
位置:org.apache.spark.sql.delta.actions下的actions文件
Protocol: 当对协议进行向后不兼容的更改时,用于阻止旧客户端读取或写入日志。在执行任何其他操作之前,readers和writers负责检查它们是否满足最低版本
SetTransaction: 设置给定应用程序的提交版本
AddFile: 往table中添加一个新文件
RemoveFile: 从存储库中逻辑删除给定文件
AddCDCFile: 一个包含CDC数据的变化文件
Metadata: 表的元数据信息
CommitInfo: 保存有关表更改的来源信息
事务
位置:org.apache.spark.sql.delta.OptimisticTransaction
关键方法:
def commit(actions: Seq[Action], op: DeltaOperations.Operation): Long = recordDeltaOperation(
deltaLog,
"delta.commit") {
...
}
主要分成以下三步:
- prepareCommit
- doCommitRetryIteratively
- postCommit
prepareCommit
提交之前对协议版本、元数据合法性、一次事务中元数据改动次数等actions进行校验,并进行相应的改变,返回最终通过的actions。
doCommitRetryIteratively
存储为hdfs
方法名:doCommitRetryIteratively
入参:
- attemptVersion: 尝试提交的版本
- actions:要提交的actions
- isolationLevel:隔离级别(一共三种,这里只用到SnapshotIsolation或者Serializable),若数据会改变则使用Serializable,否则SnapshotIsolation
逻辑:
- 尝试第一次提交:doCommit,将actions写入delta log对应的目录中,先创建一个临时文件,再进行重命名,因为hdfs rename是原子操作,不需要加锁,若目标文件已存在,则提交失败,抛出异常
- 若提交失败,则进行固定次数的重试。在重试提交之前会进行逻辑上的冲突检查(checkForConflicts),若检查通过会返回nextAttemptVersion,再进行提交。
- 提交成功,则返回当前提交的版本号。
重要方法:
方法名:checkForConflicts
入参:
- checkVersion:上一次提交失败的版本号
- actions:要提交的actions
- attemptNumber:尝试次数
- commitIsolationLevel:SnapshotIsolation\Serializable
逻辑:
- 获取nextAttemptVersion。执行 deltaLog.update(),这里stalenessAcceptable默认是false,所以需要加锁同步执行 updateInternal,通过currentSnapshot中的checkpointVersion获取对应的chk类型文件及其之后的delta类型文件,从这些文件中筛选出最新完成的chk及其之后的delta文件,处理后返回LogSegment对象;接着创建新的snapshot,并替换掉当前的snapshot;将此时snapshot中的version加1作为nextAttemptVersion。
- 检查冲突,成功则返回nextAttemptVersion。从上一次提交失败的版本号开始循环直到上一步中获取的nextAttemptVersion,获取在nextAttemptVersion之前的版本对应的要提交的actions,将其分为metadataUpdates、removedFiles、txns、protocol、commitInfo这些action,分别进行并发冲突的判断。详细并发冲突类型见:https://docs.delta.io/latest/concurrency-control.html#conflict-exceptions
postCommit
执行提交后的动作。如果需要进行checkpoint,即提交的版本不等于0并且对chk间隔取余等于0,则进行chk,跟据提交的版本创建snapshot,之后调用 Checkpoints.writeCheckpoint 生成对应的CheckpointMetaData对象,接着写入hdfs,最后,如果开启了过期日志清理,则判断已过期的日志进行删除。
调用commit的操作
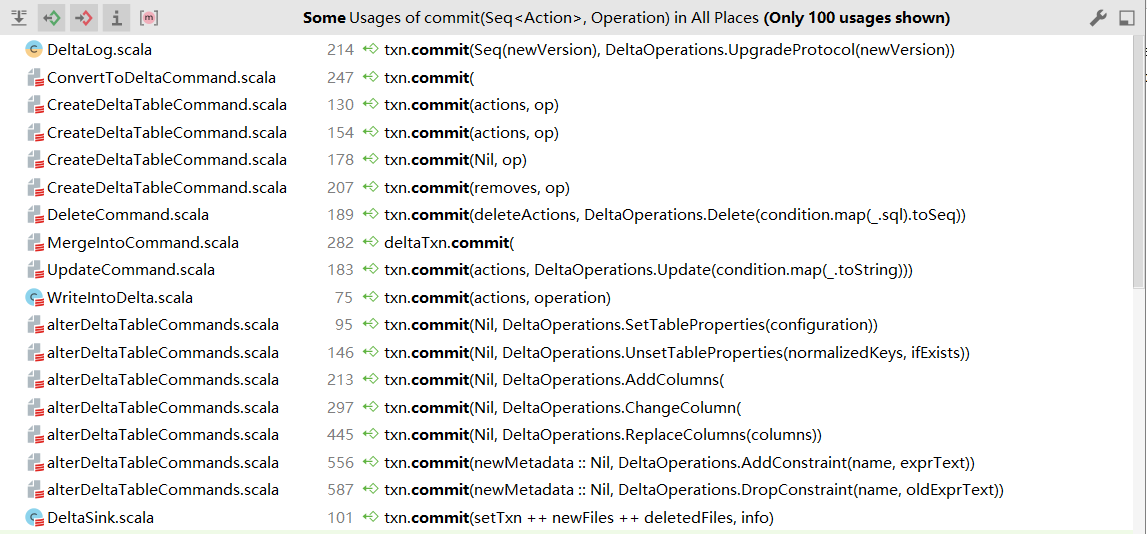
Table deletes, updates, and merges
deletes
方法名:以 delete(condition: String) 为例
一个问题:如何将delete logical plan转到DeleteCommand?
=>delta通过继承Rule来实现,如下图代码。
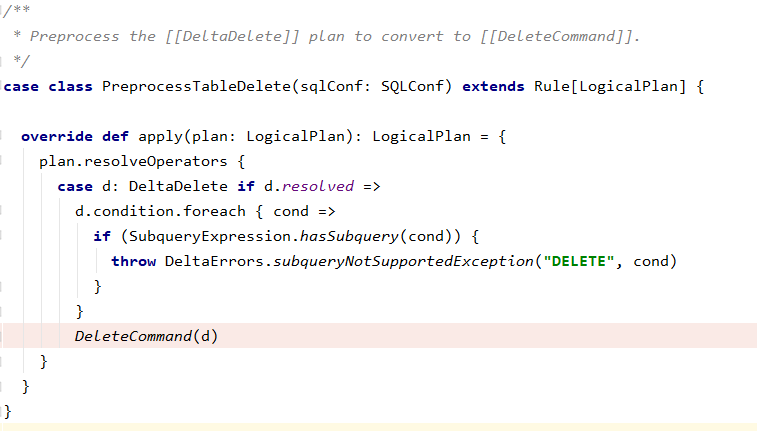
执行DeleteCommand run方法
final override def run(sparkSession: SparkSession): Seq[Row] = {
recordDeltaOperation(tahoeFileIndex.deltaLog, "delta.dml.delete") {
val deltaLog = tahoeFileIndex.deltaLog
deltaLog.assertRemovable()
deltaLog.withNewTransaction { txn =>
performDelete(sparkSession, deltaLog, txn)
}
// Re-cache all cached plans(including this relation itself, if it's cached) that refer to
// this data source relation.
sparkSession.sharedState.cacheManager.recacheByPlan(sparkSession, target)
}
Seq.empty[Row]
}
通过deltaLog.withNewTransaction保证删除的原子性,在事务中执行performDelete方法
方法名:deltaLog.withNewTransaction
- 执行startTransaction。更新当前的snapshot,获取到表最新信息,并返回OptimisticTransaction
- 将该OptimisticTransaction用ThreadLocal包装起来,保证可见性
- 将OptimisticTransaction作为入参,调用performDelete方法
方法名:performDelete
- 若删除时没有条件,则返回所有的AddFile;若有条件,则继续根据分区列将条件拆分为元数据的条件(根据分区过滤)和其他条件。
- 若其他条件是空的,则意味着不需要扫描任何数据文件,直接根据分区筛选出要删除的文件集合;否则,先找出待删除的分区文件,接着保留原始的target(LogicalPlan),替换得到newTarget,只包含待删除的AddFile,然后根据newTarget获取到DataFrame,再通过条件过滤得到需要重写的文件。
- 若无需要重写的文件,则不需要进行删除,返回空;否则,替换创建新的newTarget,获取到DF,过滤得到不需要删除的DF(updatedDF),重新写入文件(txn.writeFiles(updatedDF)),返回所有的RemoveFile和AddFile
- 如果deleteActions不是空,则进行事务commit
updates
方法名:以update(condition: Column, set: Map[String, Column])为例
执行UpdateCommand run方法
final override def run(sparkSession: SparkSession): Seq[Row] = {
recordDeltaOperation(tahoeFileIndex.deltaLog, "delta.dml.update") {
val deltaLog = tahoeFileIndex.deltaLog
deltaLog.assertRemovable()
deltaLog.withNewTransaction { txn =>
performUpdate(sparkSession, deltaLog, txn)
}
// Re-cache all cached plans(including this relation itself, if it's cached) that refer to
// this data source relation.
sparkSession.sharedState.cacheManager.recacheByPlan(sparkSession, target)
}
Seq.empty[Row]
}
方法名:performUpdate
- 获取candidateFiles。根据元数据条件和数据条件过滤得到candidateFiles。
- 如果candidateFiles为空,则返回Nil;否则如果数据条件为空,则需要更新指定分区文件中的所有行,先获取所有文件路径,根据条件重写文件中的所有row,得到rewrittenFiles(AddFile),将candidateFiles中元素更新为RemoveFile,返回deleteActions和rewrittenFiles合并的结果actions;如果数据条件不为空,根据指定条件找出所有受影响的文件filesToRewrite,如果filesToRewrite为空,则返回Nil,否则删除filesToRewrite中包含的文件,根据条件重写文件中的所有row,得到rewrittenFiles(AddFile),返回deleteActions和rewrittenFiles合并的结果actions
- 如果actions不为空,则进行事务提交
merges
示例如下:
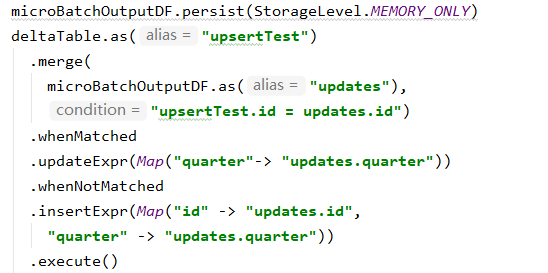
调用的方法为:DeltaMergeBuilder.execute()
最终执行方法:MergeIntoCommand.run()
逻辑:
- 如果可以合并schema,则更新元数据信息,否则不更新。详见:https://docs.delta.io/latest/delta-update.html#automatic-schema-evolution
- 如果只进行插入并且此时允许优化,则进入 writeInsertsOnlyWhenNoMatchedClauses,避免重写旧文件,只插入新文件。获取目标输出的对应列的表达式集合,获取源表的DF,根据merge的条件只获取目标表中需要的文件并转化成目标表的DF,将源表DF和目标表DF通过leftanti进行join筛选出需要写入的DF,最后写入新的文件中,返回action集合deltaActions
- 否则,走正常merge逻辑。1) 先找到需要重写的文件filesToRewrite:通过将源表DF和目标表DF进行inner join得到joinToFindTouchedFiles,从中筛选出需要的列(行id、文件名id)的DF,根据行id进行分组求和,统计求和结果大于1的个数记为multipleMatchCount;如果匹配条件的size大于1且是无条件的删除,则即使multipleMatchCount的值大于0也可以正常计算,否则抛出异常。通过文件路径找到对应的AddFile并返回。2)写入所有的变化。1)获取目标输出列,并由此生成新的LogicalPlan,并为输出列创建别名,从而得到新的目标plan。2)如果只有匹配上的条件且允许调优,则join的类型为rightouter,否则为fullouter;将源表DF与目标DF进行join。3)通过join后的plan获取到rows,对其进行mapPartitions操作,执行JoinedRowProcessor中的processPartition,获取输出的DF,写入delta表,返回action集合newWrittenFiles。4)将filesToRewrite转化为RemoveFile,并与newWrittenFiles组合后返回deltaActions
- 提交事务。
重要方法:processPartition
准备
right outer join:参与 Join 的右表数据都会显示出来,而左表只有关联上的才会显示,否则为null。
full outer join:左右表都会显示,但是如果没有关联时会显示,否则左右表会有一个显示为null。
def processPartition(rowIterator: Iterator[Row]): Iterator[Row] = {
val targetRowHasNoMatchPred = generatePredicate(targetRowHasNoMatch)
val sourceRowHasNoMatchPred = generatePredicate(sourceRowHasNoMatch)
val matchedPreds = matchedConditions.map(generatePredicate)
val matchedProjs = matchedOutputs.map(generateProjection)
val notMatchedPreds = notMatchedConditions.map(generatePredicate)
val notMatchedProjs = notMatchedOutputs.map(generateProjection)
val noopCopyProj = generateProjection(noopCopyOutput)
val deleteRowProj = generateProjection(deleteRowOutput)
val outputProj = UnsafeProjection.create(outputRowEncoder.schema)
def shouldDeleteRow(row: InternalRow): Boolean =
row.getBoolean(outputRowEncoder.schema.fields.size)
def processRow(inputRow: InternalRow): InternalRow = {
if (targetRowHasNoMatchPred.eval(inputRow)) {
// Target row did not match any source row, so just copy it to the output
noopCopyProj.apply(inputRow)
} else {
// identify which set of clauses to execute: matched or not-matched ones
val (predicates, projections, noopAction) = if (sourceRowHasNoMatchPred.eval(inputRow)) {
// Source row did not match with any target row, so insert the new source row
(notMatchedPreds, notMatchedProjs, deleteRowProj)
} else {
// Source row matched with target row, so update the target row
(matchedPreds, matchedProjs, noopCopyProj)
}
// find (predicate, projection) pair whose predicate satisfies inputRow
val pair = (predicates zip projections).find {
case (predicate, _) => predicate.eval(inputRow)
}
pair match {
case Some((_, projections)) => projections.apply(inputRow)
case None => noopAction.apply(inputRow)
}
}
}
val toRow = joinedRowEncoder.createSerializer()
val fromRow = outputRowEncoder.createDeserializer()
rowIterator
.map(toRow)
.map(processRow)
.filter(!shouldDeleteRow(_))
.map { notDeletedInternalRow =>
fromRow(outputProj(notDeletedInternalRow))
}
}
逻辑:(左表为source,右表为target)
- 遍历join后的分区rows,进入processRow方法。1)如果目标row没有匹配上任何源表的row,即只有右表,左表为null,则直接把输入进行输出;2)当左表有值,右表为null,则是未能匹配上,插入左表中对应的数据;3)当左右表都有时,则说明匹配上了,更新右表的row
join后如下表:
|
source |
target |
op |
|
null |
have value |
直接把输入进行输出 |
|
have value |
null |
notMatched+插入左表中对应的数据 |
|
have value |
have value |
matched+更新右表的row |
delta源码阅读的更多相关文章
- 【原】FMDB源码阅读(一)
[原]FMDB源码阅读(一) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 说实话,之前的SDWebImage和AFNetworking这两个组件我还是使用过的,但是对于 ...
- Caffe源码阅读(1) 全连接层
Caffe源码阅读(1) 全连接层 发表于 2014-09-15 | 今天看全连接层的实现.主要看的是https://github.com/BVLC/caffe/blob/master/src ...
- JDK1.8源码阅读笔记(2) AtomicInteger AtomicLong AtomicBoolean原子类
JDK1.8源码阅读笔记(2) AtomicInteger AtomicLong AtomicBoolean原子类 Unsafe Java中无法直接操作一块内存区域,不能像C++中那样可以自己申请内存 ...
- 【原】FMDB源码阅读(三)
[原]FMDB源码阅读(三) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 FMDB比较优秀的地方就在于对多线程的处理.所以这一篇主要是研究FMDB的多线程处理的实现.而 ...
- 【原】FMDB源码阅读(二)
[原]FMDB源码阅读(二) 本文转载请注明出处 -- polobymulberry-博客园 1. 前言 上一篇只是简单地过了一下FMDB一个简单例子的基本流程,并没有涉及到FMDB的所有方方面面,比 ...
- 【原】AFNetworking源码阅读(六)
[原]AFNetworking源码阅读(六) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 这一篇的想讲的,一个就是分析一下AFSecurityPolicy文件,看看AF ...
- 【原】AFNetworking源码阅读(五)
[原]AFNetworking源码阅读(五) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇中提及到了Multipart Request的构建方法- [AFHTTP ...
- 【原】AFNetworking源码阅读(四)
[原]AFNetworking源码阅读(四) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇还遗留了很多问题,包括AFURLSessionManagerTaskDe ...
- 【原】AFNetworking源码阅读(三)
[原]AFNetworking源码阅读(三) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇的话,主要是讲了如何通过构建一个request来生成一个data tas ...
随机推荐
- 【spring源码系列】之【Bean的循环依赖】
希望之光永远向着目标清晰的人敞开. 1. 循环依赖概述 循环依赖通俗讲就是循环引用,指两个或两个以上对象的bean相互引用对方,A依赖于B,B依赖于A,最终形成一个闭环. Spring循环依赖的场景有 ...
- LC-322. 零钱兑换
322. 零钱兑换 给你一个整数数组 coins ,表示不同面额的硬币:以及一个整数 amount ,表示总金额. 计算并返回可以凑成总金额所需的 最少的硬币个数 .如果没有任何一种硬币组合能组成总金 ...
- 规模化敏捷LeSS(二):LeSS*队实践指南
Scrum 能够帮助一个5-9人的小*队以迭代增量的方式开发产品,在每一迭代结束时,交付潜在的可交付的产品增量.正是由于其灵活性,Scrum 方法现已成为*队软件交付方法的首选,近期发布的15届敏捷状 ...
- 爬取房价信息并制作成柱状图XPath,pyecharts
以长沙楼盘为例,看一下它的房价情况如何url = https://cs.newhouse.fang.com/house/s/b91/ 一.页面 二.分析页面源代码 我们要获得的数据就是名字和价格,先来 ...
- Linux开机以root账户自动登录
最近我们的自动化测试平台需要支持中标麒麟系统,对于我们来说要让这个系统支持分布式自动化测试,最重要的一点就是虚拟机启动后自动以root账户登录系统,并且执行我们的环境配置脚本,那么如何能让它开启自动登 ...
- CF474D Flowers 题解
题目:CF474D Flowers 传送门 DP?递推? 首先可以很快看出这是一道 DP 的题目,但与其说是 DP,还不如说是递推. 大家还记得刚学递推时教练肯定讲过的一道经典例题吗?就是爬楼梯,一个 ...
- nfs配置项在/etc/exports中的说明
rw 可读写的权限 ro 只读的权限no_root_squash 登入NFS主机,使用该共享目录时相当于该目录的拥有者,如果是root的话,那么对于这个共享的目录来说,他就具有root的权 ...
- C++ //多态案例三 ---电脑组装
1 //多态案例三 ---电脑组装 2 3 #include <iostream> 4 #include <string> 5 using namespace std; 6 7 ...
- python自动化之(自动生成测试报告)
前言: 用python执行测试脚本, 测试报告是记录我们测试过程的问题, 方便我们对整个测试过程的把控. 这里引用的是别人写好的模板, 我们拿过来用就OK, 能力强者可自行编写模板 测试报告图模板: ...
- 修改Linux系统的默认语言编码集
RedHat 今天晚上发现服务器上vi的界面提示变成了乱码,只能将XShell的编码改为GBK才能正常显示,导致consolas字体无法使用,GBK编码下的字体丑陋无比,无法忍受,一轮google之后 ...