Spark集群基础概念 与 spark架构原理
一、Spark集群基础概念


将DAG划分为多个stage阶段,遵循以下原则:
1、将尽可能多的窄依赖关系的RDD划为同一个stage阶段。
2、当遇到shuffle操作,就意味着上一个stage阶段结束,下一个stage阶段开始
关于RDD中的分区,在默认情况下(也就是未指明分区数的情况)
1、如果从HDFS中读取数据创建RDD,在默认情况下
二、spark架构原理
1、Spark架构原理
Driver 进程
编写的Spark程序就在Driver上, 由Driver进程执行。
Driver可以是Spark集群的节点之一, 或者是提交Spark程序的机器
Master 进程
主要负责资源的调度和分配, 以及集群的监控等职责
Worker 进程
主要职责有两个:
用自己所在节点的内存存储RDD的partition
启动其他进程和线程, 对RDD的partition进行并行计算处理
Executor 进程
Executor接收到task之后, 会启动多个线程来执行task
task 线程
task会对RDD的partition数据执行指定的算子操作, 形成新RDD的 partition
小结:
Executor和task, 其实就是负责执行, 对RDD的partition进行并行的计算, 也就是执行我们对RDD定义的, 比如flatMap、 map、 reduce等算子操作。
2、spark架构

3、spark架构整体流程

4、Spark架构原理剖析
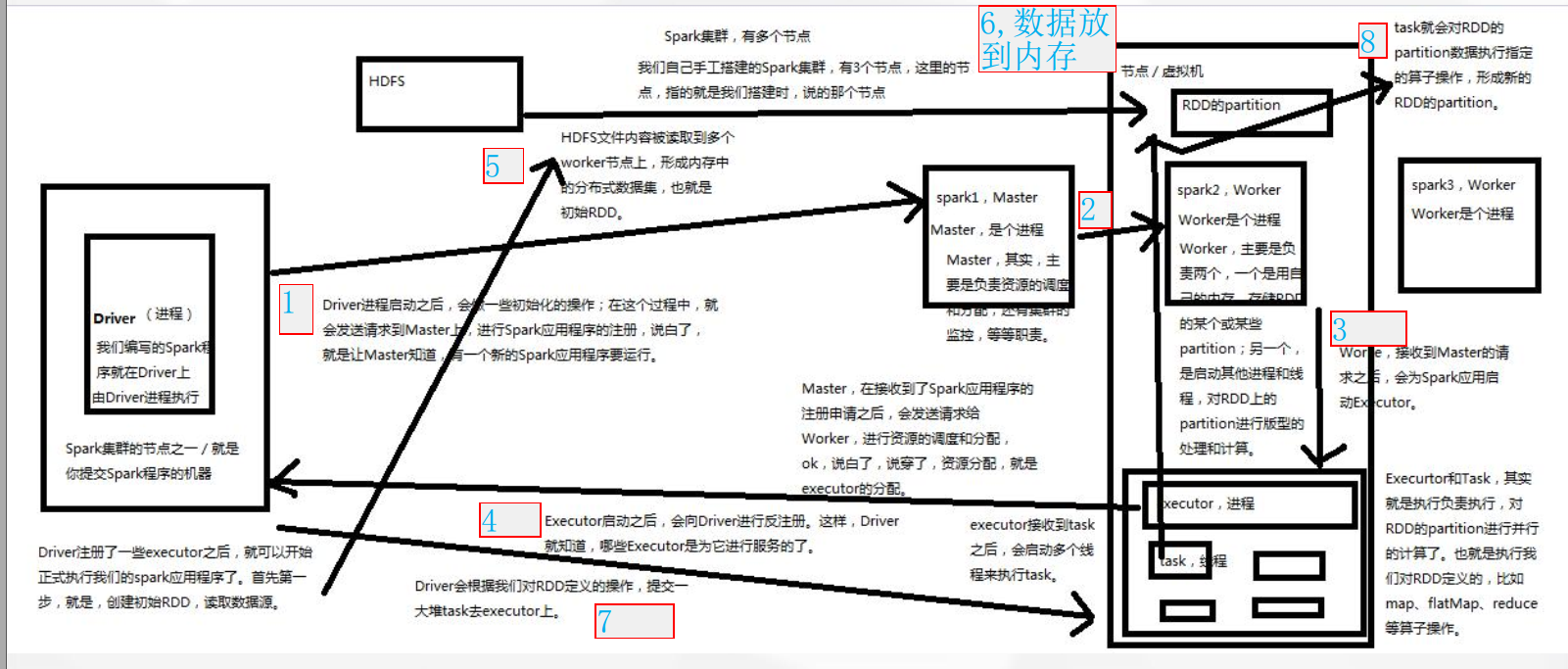
( driver—master——worker——executor—driver 前四步形成闭环 第五步执行程序,读取数据)
第一步:Driver进程启动之后,会做一些初始化的操作;在这个过程中,就会发送请求到master上,进行spark应用程序的注册,说白了,就是让master知道,有一个新的spark应用程序要运行
第二步:master,在接收到了spark应用程序的注册申请之后,或发送请求给worker,进行资源的调度和分配,OK,说白了资源分配就是executor的分配
第三步:worker接收到master的请求之后,会为spark应用启动executor
第四步:executor启动之后,会向Driver进行反注册,这样,Driver就知道哪些executor是为它进行服务的了
第五步:Driver注册了一些executor之后,就可以开始正式执行我们的spark应用程序了,首先第一个步就是创建初始RDD,读取数据源
第六步:RDD的分区数据放到内存中
第七步:Driver会根据我们对RDD定义的操作,提交一大堆task去executor上
第八步:task会对RDD的partition数据执行指定的算子操作,形成新的RDD的partition
5、spark架构原理深度剖析(Standalong模式)
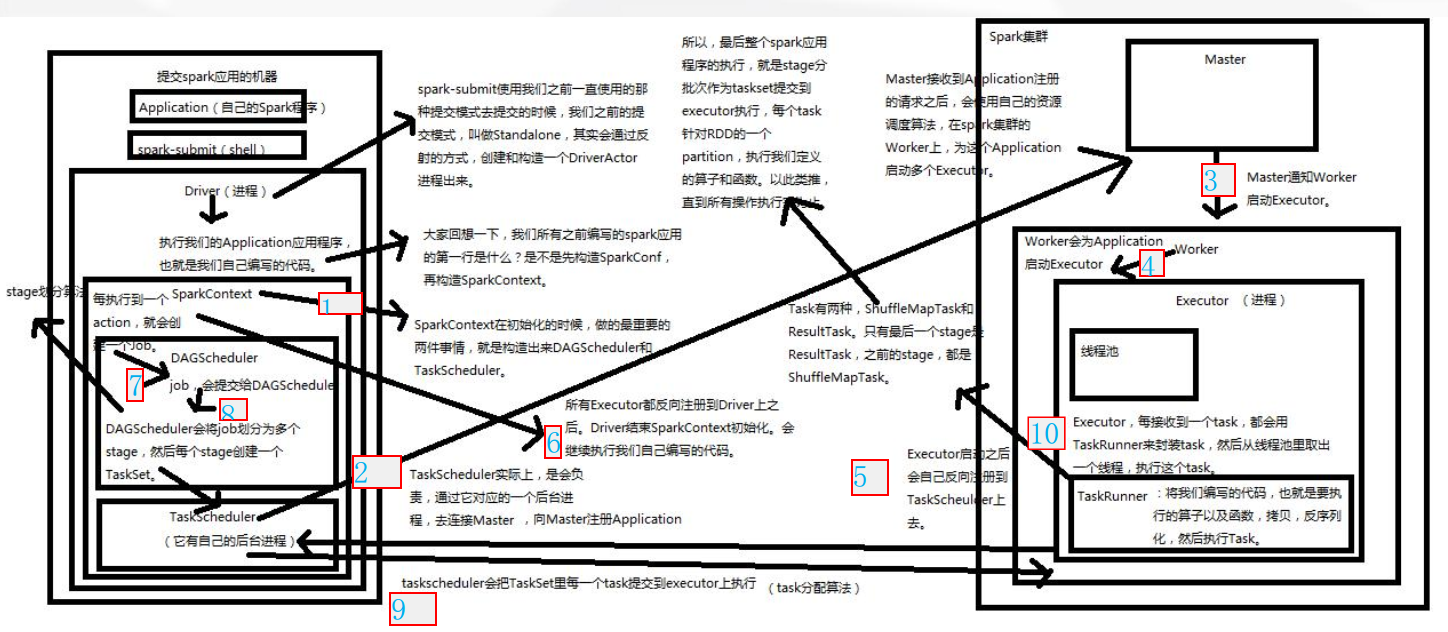
1、
通过spark-submit指令将打好的Spark jar包提交到Spark集群中运行。
先从Driver进程开始运行,Driver中包含了我们所编写的代码。
首先执行代码中的前两句,
val conf=new SparkConf().setAppName("AppOperate")
.setMaster("local")
val sc=new SparkContext(conf)
创建SparkConf和SparkContext对象,
在创建SparkContext对象的过程中,会去做两件很重要的事,就是
创建DAGScheduler和TaskScheduler这两个对象。
然后,TaskScheduler会通过一个后台进程负责与Master进行注册通信,
告诉Master有一个新的Application应用程序要运行,需要Master管理
分配调度集群的资源。
2、Master接收到TaskScheduler的注册请求之后,会通过资源调度算法对
集群资源进行调度,并且与Worker进行通信,请求Worker启动相应的Executor
3、Worker接收到Master的请求之后,会在本节点中启动Executor。
因为集群中有多个Worker节点,那么也意味着会启动多个Executor。
一个Application对应着Worker中的一个Executor。
4、Executor启动完成之后,会向Driver中的TaskScheduler进行反注册,
反注册的目的就是让Driver知道新提交的Application应用将由哪些Executor
负责执行。
5、Executor向Driver中的TaskScheduler反注册完成之后,就意味
着SparkContext的初始化过程已经完成,接下来去执行SparkContext
下面的代码。
6、
在SparkContext下面的代码中,创建了初始RDD,并对初始RDD进行了
Transformation类型的算子操作,但是系统只是记录下了这些操作行为,
这些操作行并没有真正的被执行,直到遇到Action类型的算子,触发
提交job之后,Action类型的算子之前所有的Transformation类型的
算子才会被执行。
job会被提交给DAGScheduler,DAGScheduler根据stage划分算法将
job划分为多个stage(阶段),并将其封装成TaskSet(任务集合),
然后将TaskSet提交给TaskScheduler。
7、TaskScheduler根据task分配算法,将TaskSet中的每一个小task分配
给Executor去执行。
8、Executor接受到task任务之后,通过taskrunner来封装一个task,
并从线程池中取出相应的一个线程来执行task。
task线程针对RDD partition分区中的数据进行指定的算子操作,
这些算子操作包括Transformation和Action类型的操作。
补充说明:
1)taskrunner(任务运行器),会对我们编写代码进行复制、反序列化
操作,进行执行task任务。
2)task分为两大类:ShuffleMapTask和ResultTask。最后一个stage
阶段中的task称为ResultTask,
在这之前所有的Task称为ShuffleMapTask。
整个过程用到3个算法(资源调度算法、stage划分算法、task分配算法)
stage划分算法:会从执行action的最后一个RDD开始往前推,首先会为最后一个RDD创建一个stage,然后继续往前推,如果遇到一个宽依赖,就会为这个宽依赖创建一个stage。以此类推
Spark集群基础概念 与 spark架构原理的更多相关文章
- Database基础(七):部署集群基础环境、MySQL-MMM架构部署、MySQL-MMM架构使用
一.部署集群基础环境 目标: 本案例要求为MySQL集群准备基础环境,完成以下任务操作: 数据库授权 部署MySQL双主多从结构 配置本机hosts解析记录 方案: 使用4台RHEL 6虚拟机,如下图 ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- 四、spark集群架构
spark集群架构官方文档:http://spark.apache.org/docs/latest/cluster-overview.html 集群架构 我们先看这张图 这张图把spark架构拆分成了 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
随机推荐
- centos7挂载Windows共享文件夹(学习笔记)
centos7挂载windows共享文件夹 练习环境:centos7是安装在台式机的虚拟机,Windows共享文件夹是公司服务器的共享文件夹(已设置好的共享) 步骤 1. 设置挂载点:mkdir /m ...
- 好用的MarkDown编辑器
MarkDown是编写文档非常有用的一个好工具
- 算法笔记(c++)--桶排序题目
算法笔记(c++)--桶排序 记得题目是排序,输入n个1-1000的数字然后去重然后排序. 桶排序没毛病 #include<iostream> using namespace std; i ...
- eclipse 简单操作
1.设置字体: windows --> preferences --> general --> Colors and Fonts --> Basic --> 双击 Tex ...
- 如何计算FOB价格
FOB价格是国际贸易术语常有的一种算法,针对不同的对象,FOB价格也有不一样的算法.对于做外贸生意的朋友,需要了解FOB价格以及各项费用名称,以及如何计算FOB价格. FOB价格是国际FOB价格语常有 ...
- “Hello World!”团队第七周召开的第一次会议
今天是我们团队“Hello World!”团队第七周召开的第一次会议.博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.Todo List 六.会议照片 七.燃尽图 一.会议时间 ...
- 王者荣耀交流协会Beta发布文案美工展示博客
logo: 我们的logo是蓝底白字,非常简洁大气的设计感,上面印有我们的软件名称,更好的直观的彰显了我们的主题.我们的软件就是要迎合使用者,给使用者更加方便快捷的工作体验,更好的衡量自己的时间分配. ...
- 20172330 2017-2018-1 《Java程序设计》第十一周学习总结
20172330 2017-2018-1 <程序设计与数据结构>第十一周学习总结 教材学习内容总结 本周的学习内容为集合 Android简介 Android操作系统是一种多用户的Linux ...
- a5
今日内容: 今天主要还是素材的查找,图标的制作以及调整. 明日计划: 主要还是完成图标,尽可能的美化 困难: 一个是直男式的审美吧,另一个是PS的技术还不够深
- vbs习题
练习题: 1.输入3个数,输出其中最大的那个值. Option Explicit Dim intA,intB,intC intA=CInt(InputBox("请输入a:")) i ...