存储系统的基本数据结构之一: 跳表 (SkipList)
在接下来的系列文章中,我们将介绍一系列应用于存储以及IO子系统的数据结构。这些数据结构相互关联又有着巨大的区别,希望我们能够不辱使命的将他们分门别类的介绍清楚。本文为第一节,介绍一个简单而又有用的数据结构:跳表 (SkipList)
在对跳表进行讨论之前,我们首先描述一下跳表的核心思想。
跳表(Skip List)是有序线性链表的一种。通常对线性链表进行查找需要遍历,因而不能很好的使用二分查找这样快速的方法(想像一下在链表中定位中间元素的复杂度)。为了提高查找速率,我们可以将这些线性链表打散,组织成树结构,这样的树就叫做查找树。查找树中尤以平衡查找树的查找代价最小,因此平衡二叉查找树成为了在内存中进行查找的最佳的数据结构。红黑树作为平衡二叉查找树的一种实现,经常被我们用在这种场景之中。
然而,平衡树就一定需要平衡化。在对树进行一系列的插入删除之后,树不再平衡了,此时就需要调整平衡的算法。红黑树的复杂性就体现在这里,相信所有写过红黑树的童鞋都记忆犹新。
就在此时,晴天一个霹雳,跳表诞生了[1]。它支持快速检索且不需要复杂的平衡操作,由于它的简单性,使得它往往比红黑树还有更好的性能表现。
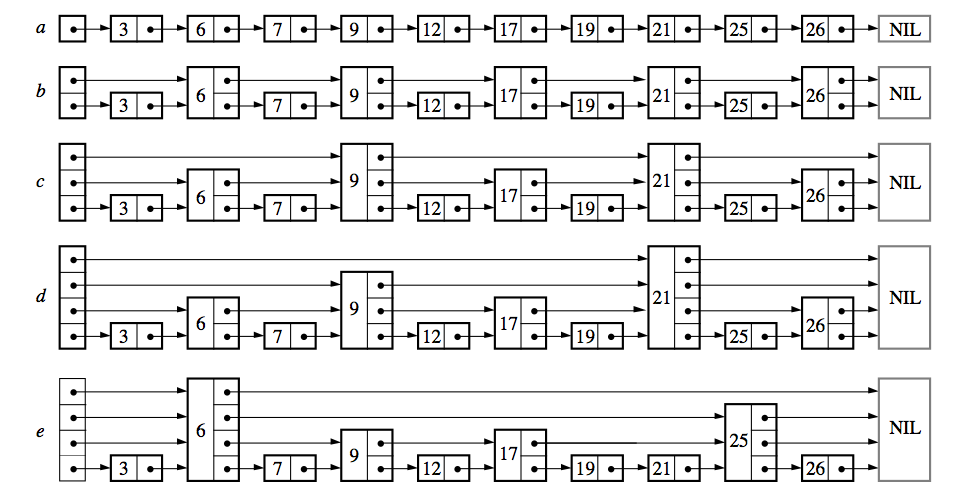
上图就是一个跳表的示意图,图中 (a) 是一个正常的有序列表,而 (b) 到 (e) 则是不同level的跳表。
定义:
对于一个节点,如果它有k个指针,那么就称之为一个 level k 节点。
一个跳表的最大 level 是当前在列表中最大的节点的 level。对于空列表, level为1.
推论:
如果每第 (2i) 个节点有一个指针指向向后数 (2i) 节点,而不是指向紧接着的那个节点,那么所有的节点基本上会满足这样一个分布:50%的节点位于level 1,25%的节点位于level 2,12.5%的节点位于level 3 等等。
如果某个节点的level是随机选择的,且随机所遵守的分布符合上个推论所描述,那么 level k 节点的第 i 个指针只需要指向下一个 level 大于等于 i 的节点就构造如上图所示的跳表,并不需要一定要严格指向第 ii-1 个节点。
算法:
1> 初始化
只创建第一个列表,该列表的leve值就是1。
2> 检索
a) 搜索从最大level的列表开始,找到比要检索的key小的最大的那个元素
b) 如果不能找到,减少一个level继续检索
c) 如果在level 1一层也不能找到,那就说明所要找的元素一定在当前停下的位置的下一个节点
Search(list, key)
{
x = list->header
for (i = list.level; i >= 1; i--)
{
while (x->forward[i]->key < key)
x = x->forward[i]
}
x = x->forward[1]
if (x->key == key) return x->vlaue
else return failure
}
3> 插入
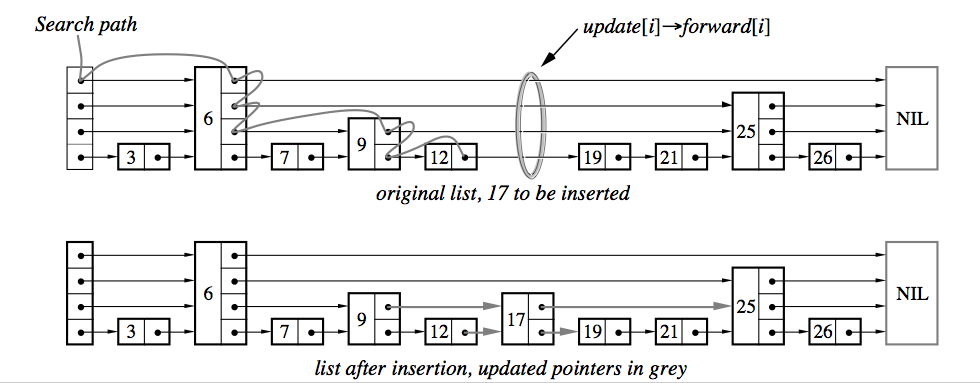
a) 检索要插入的key是否存在,如果存在那么更新value即可
b) 如果不存在,则需要插入。需要注意的是,在检索的过程中,我们应当用一个数组 update[1...MaxLevel] 来保存每一个 level 中搜索停止的节点,这些节点用于后来指向新加入的节点
c) 产生一个新节点,随机的给定该节点的level。如果随机出来的level比当前最大的level还要大,那么扩大 update 数组到新的 MaxLevel 个元素,并且将新增的 update 元素设置为 list 的 header
d) 从 1 开始到 MaxLevel,将新节点的 forward 数据设置为 update[i...MaxLevel] 的值;而将 update[i...MaxLevel] 的 forward[i] 设置为 x.
insert(list, key, value){
local update[...MaxLevel]
x = list->header
for i = list->level downto do
while x->forward[i]->key < key
x = x->forward[i]
update[i] = x
if x->key == key then x->value = value;
else
lvl = randomLevel()
if lvl > list->level then
for i = list->level + to lvl
update[i] = list->header
list->level = lvl
x = MakeNode(lvl, key, value)
for i = to level
x->forward[i] = update[i]->forward[i];
update[i]->forward[i] = x;
}
> 选择新节点的level
新节点的level完全由一个随机函数产生:
randomLevel()
lvl =
while random() < p and lvl < MaxLevel do
lvl = lvl +
return lvl
复杂度分析:
搜索复杂度的分析方法很简单,结论是非常确定的O(logn),那剩下的比较就是常数项了,如下图所示:
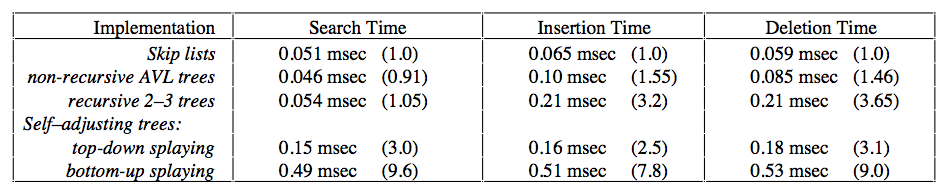
可以看出来,跳表还是有很大的常数项优势的。
-- Reference --
[1] William Pugh, 1990, Communications of the ACM 33.6, Skip Lists: A Probabilistic Alternative to Balanced Trees.
存储系统的基本数据结构之一: 跳表 (SkipList)的更多相关文章
- 跳表SkipList
原文:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html 跳表SkipList 1.聊一聊跳表作者的其人其事 2. 言归正 ...
- 跳表 SkipList
跳表是平衡树的一种替代的数据结构,和红黑树不同,跳表对树的平衡的实现是基于一种随机化的算法,这样就使得跳表的插入和删除的工作比较简单. 跳表是一种复杂的链表,在简单链表的节点信息之上又增加了额 ...
- 3.3.7 跳表 SkipList
一.前言 concurrentHashMap与ConcurrentSkipListMap性能测试 在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSki ...
- 跳表(SkipList)原理篇
1.什么是跳表? 维基百科:跳表是一种数据结构.它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度.快速的查询效果是通过维护一个多层次的链表实 ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- redis的zset数据结构:跳表
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 广州这边封闭式管理好久了,今天终于周末可以出去溜溜了 什么是zset z ...
- [转载] 跳表SkipList
原文: http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html leveldb中memtable的思想本质上是一个skiplist ...
- C语言跳表(skiplist)实现
一.简介 跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入.删除.查找的复杂度均为O(logN).LevelDB的核心数据结构是用跳表实现的,redis的sorted set数据结构也 ...
- 跳表(skiplist)Python实现
# coding=utf-8 # 跳表的Python实现 import random # 最高层数设置为4 MAX_LEVEL = 4 def randomLevel(): ""& ...
随机推荐
- 【ZZ】国外大型网站使用到编程语言 | 菜鸟教程
http://www.runoob.com/w3cnote/rogramming-languages-used-in-most-popular-websites.html 下图展示了大型网站使用到的后 ...
- Mac上如何把图片中的文字转换成word/pdf文字
如何把图片文字转换成word文字? - 知乎 https://www.zhihu.com/question/25488536 在 OneNote for Mac 中插入的圖片複製文字 - OneNot ...
- 使用Fiddler实现网络限速
Fiddler实现网络限速方法: 1.点击FiddlerScript 2.在脚本里相应的地方添加“2”处两行代码(不加注释),保存(Save Script) 第一行为请求延时3秒,第二行为响应延时1. ...
- Basic64 编码解码
import sun.misc.BASE64Decoder; public class Base64 { /** * 字符串转Base64编码 * @param s * @return */ publ ...
- delphi Firemonkey ListView 使用参考
delphi Firemonkey ListView 使用参考 Tokyo版本 http://docwiki.embarcadero.com/RADStudio/Tokyo/en/Customizin ...
- JAVA_02
class Test2_Extents{ public static void main(String[] args){ System.out.println("Hello World&qu ...
- Resources与StreamingAssets文件夹的区别
1.Resources文件夹 Resources文件夹是一个只读的文件夹,通过Resources.Load()来读取对象.因为这个文件夹下的所有资源都可以运行时来加载,所以Resources文件夹下 ...
- freemaker在表格中遍历数据
Controller层如下所示: @RequestMapping(value = "/test", method = RequestMethod.GET) public Strin ...
- Python_02-控制语句
目录: 1 控制结构... 1.1 分支语句... 1.1.1 if语句的嵌套... 1.2 for循环... 1.2.1 Python 循环中的 ...
- store下载文件保存位置
PC:C:\Users\accountName\AppData\Roaming\Unity\Asset Store MAC:"~/Library/Unity/Asset"