Google's Machine Learning Crash Course #03# Reducing Loss
Goal of training a model is to find a set of weights and biases that have low loss, on average, across all examples. —— Descending into ML: Training and Loss
注释:教程中的 loss ≠ 平均方差,而是指单个 labeled example 的方差(也就是误差 loss ),这里的 reducing loss 是指减小整体的误差(就是 MSE 了)
An Iterative Approach
我们的最终目的就得到一个较好的 model(假设 feature 只有一个,那么这个 model 很可能是一条直线),这个 model 可以比较准确地帮助我们推断、预测。
那么什么是比较好的 model 呢?具有总体低 loss 的 model 就是好的 model ,问题在于,如何计算总体 loss 以及怎样减小总体 loss 以逼近我们想要的 model ,在上一节已经谈到,我们经常用平均方差来判断一个 model 的好坏,平均方差大的就是总体 loss 大的,说明 model 不好,平均方差越趋近于零,则 model 越完美。
可以想象这样一个过程:
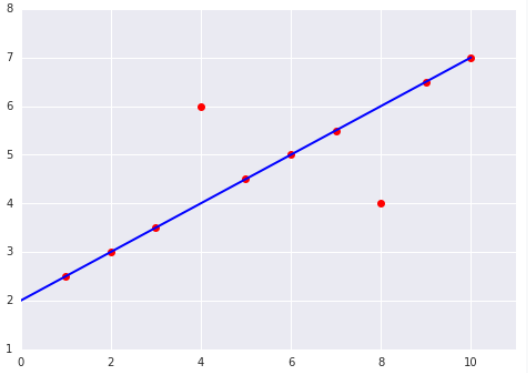
我们先随便画一条直线,然后计算它的 loss (假设已经一个这样的函数,例如 getLoss 什么的),上面 MSE算出来是 8 ,发现好大 ,这个时候我们微调直线的斜率 w 以及 y轴截距 b 得到一条新的直线,就像下面这样,MSE 是 4 ,发现更小了, 于是我们继续 ......
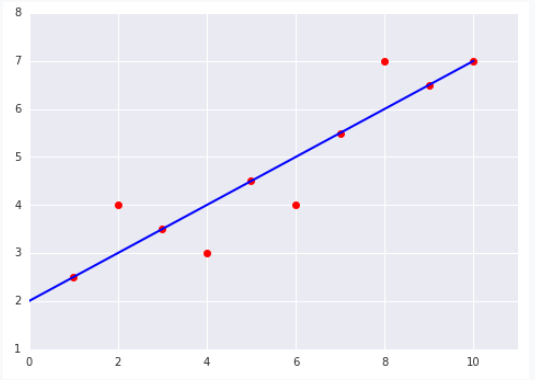
就这样循环往复: 微调斜率w 和截距b → 计算 loss → 微调斜率w 和截距b → 计算 loss → 微调斜率w 和截距b → ...
直到 loss 减小到几乎不再变化(术语叫做模型已经收敛),我们就成功了,整个过程可以用下面这张图描述:
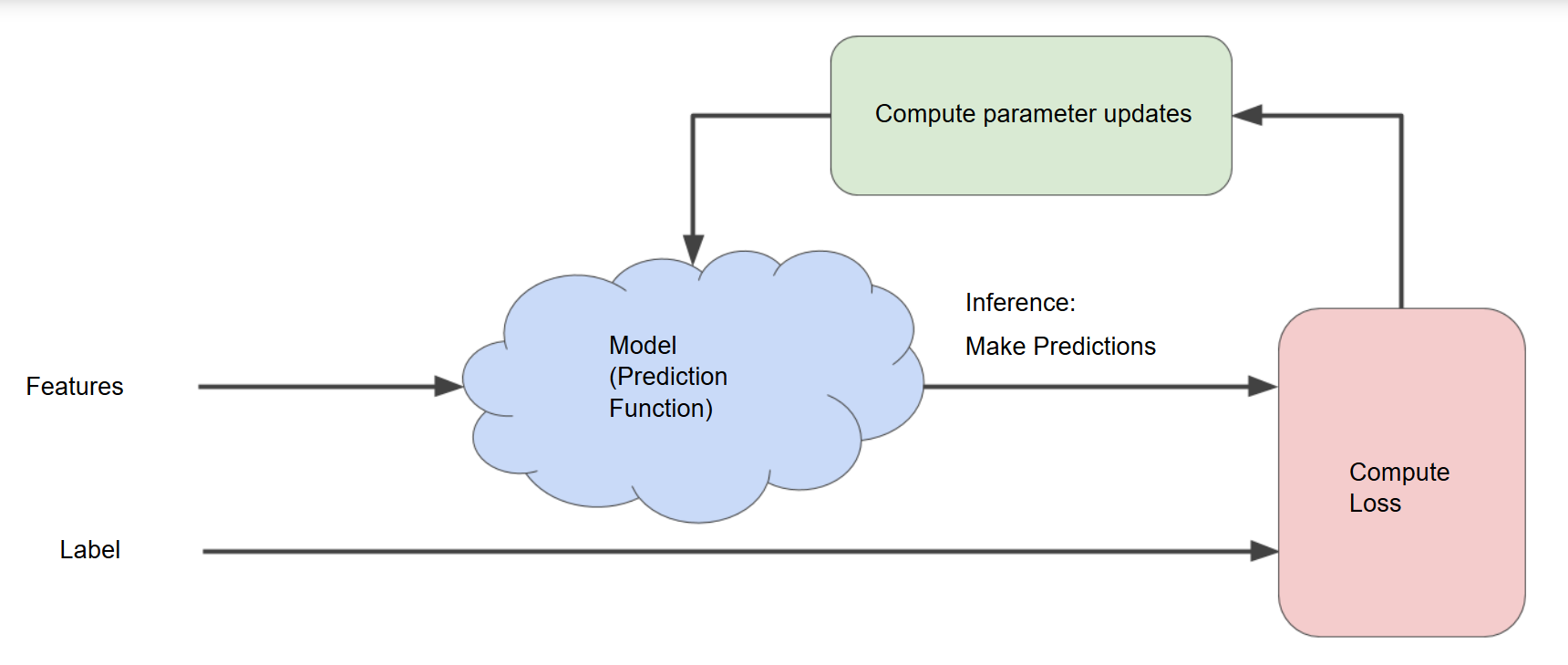
Gradient Descent
这一小节讲述具体如何“微调斜率w ”。
假设我们有足够的时间和计算资源对每一个w的可能取值计算 loss ,那么我们一定会得到一个这样的图像:
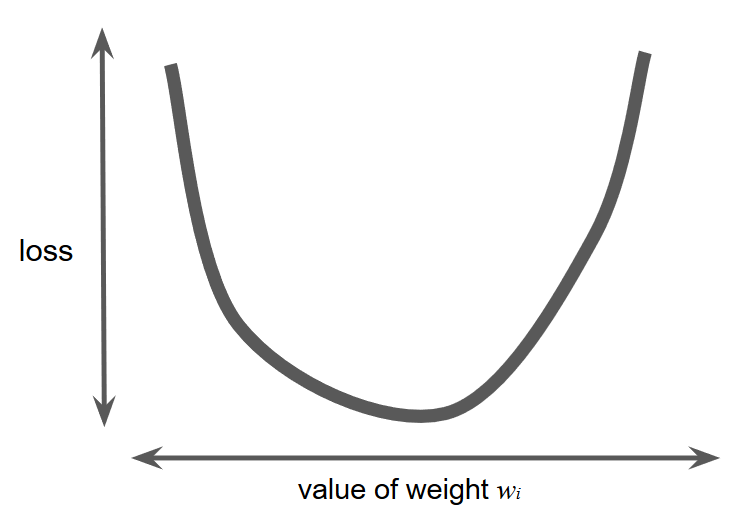
收敛问题只有一个最小值,就像图像上看到的,仅有一个地方的斜率为 0 .
如果我们真有那么多的时间和计算资源,像上面那样做就可以很直观、容易地得到最恰当的 w 了,不幸地是,现实中我们可没有那么多时间,“对每个可能的 w 在整个数据集上计算 loss ”这一做法效率太低了。有一种更好地方式来找最低点,它在机器学习中非常流行,叫“梯度下降法”。
这种方式的第一步是随机取一个点(随机定下一个 w),很多算法都直接取 0 ,取哪一点都是无关紧要的。
之后,梯度下降算法计算这一点的斜率(导数),如果有多个权重 w ,那么梯度就是这一点关于各个 w的偏导数构成的向量。
记住,梯度是一个向量,因此它具有方向和大小。因此,梯度下降算法朝着负梯度迈出一步(step),以便尽快的减少 loss . 它将梯度大小的一部分加到起点处得到下一个点,并不断重复上述步骤,越来越接近最小值。
Learning Rate
As noted, the gradient vector has both a direction and a magnitude. Gradient descent algorithms multiply the gradient by a scalar known as the learning rate (also sometimes called step size) to determine the next point. For example, if the gradient magnitude is 2.5 and the learning rate is 0.01, then the gradient descent algorithm will pick the next point 0.025 away from the previous point.
很多程序员都花费大量的时间调整学习速率,学习速率太小,那么整个学习过程会非常漫长,但是,如果学习速率太大,你甚至可能永远得不到最终的结果(点总是在最低点的两端来回弹跳)。
每一个回归问题都有一个比较恰当的学习速率,它取决于函数的平缓程度。如果你知道 loss-权重 函数的梯度很小,就可以放心地用大的学习速率尝试。(因为下一点的距离是学习速率 * 梯度,梯度小的话,学习速率大一点也无妨,并不容易因为前进太多而错过最低点)
PS. The Goldilocks learning rate 代表着最佳学习速率,实践中,找到完美的学习速率并非必要的,我们只需要找到一个“足够大又不过大”的学习速率就好了。
Stochastic Gradient Descent 随机梯度下降
full-batch iteration 每次迭代都用整个数据集
Stochastic gradient descent (SGD) 每次迭代随机仅仅选择 1 个 example
Mini-batch stochastic gradient descent (mini-batch SGD) 每次迭代随机选择 10 ~ 1000 个 example
Google's Machine Learning Crash Course #03# Reducing Loss的更多相关文章
- Google's Machine Learning Crash Course #01# Introducing ML & Framing & Fundamental terminology
INDEX Introducing ML Framing Fundamental machine learning terminology Introducing ML What you learn ...
- Google's Machine Learning Crash Course #02# Descending into ML
INDEX How do we know if we have a good line Linear Regression Training and Loss How do we know if we ...
- Google's Machine Learning Crash Course #04# First Steps with TensorFlow
1.使用 TensorFlow 的建议 Which API(s) should you use? You should use the highest level of abstraction tha ...
- 学习笔记之Machine Learning Crash Course | Google Developers
Machine Learning Crash Course | Google Developers https://developers.google.com/machine-learning/c ...
- Machine Learning 学习笔记 03 最小二乘法、极大似然法、交叉熵
损失函数. 最小二乘法. 极大似然估计. 复习一下对数. 交叉熵. 信息量. 系统熵的定义. KL散度
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- 基于Windows 机器学习(Machine Learning)的图像分类(Image classification)实现
今天看到一篇文章 Google’s Image Classification Model is now Free to Learn 说是狗狗的机器学习速成课程(Machine Learning C ...
- machine learning----->谷歌Cloud Machine Learning平台
1.谷歌Cloud Machine Learning平台简介: 机器学习的三要素是数据源.计算资源和模型.谷歌在这三个方面都有强大的支撑:谷歌不仅有种类丰富且数量庞大的数据资源,而且有强大的计算机群提 ...
随机推荐
- CCCC L2-008. 最长对称子串
https://www.patest.cn/contests/gplt/L2-008 题解:想法是扫一遍string,将每一个s[i]作为对称轴,写一个判定函数:不断向两边延伸直到不是回文串为止. ...
- Gym - 101628F Find the Inn dijkstra,读边时计算新权值
题意: 给n个点m条边及每条边所花费的时间,经过给定的p个点时会停留k秒,要求在t秒内从1号点走到n号点,若可以走到输出最短时间,若不行输出-1.. 题解:读取边时,将每个点停留的时间加到以其为终点的 ...
- SEO工作中如何增加用户体验?10个细节要注意!
我们一直在做的网站SEO工作,如果你认为它的目的仅仅是为了提高网站的排名那就错了,还有一个同样很重要的方面就是增加用户的体验,使网站更加符合网民的浏览习惯,需要做到这个方面的成功我们有10个小细节是需 ...
- linux elasticsearch-5.1.1的安装
(一)下载elasticsearch linux安装包 https://www.elastic.co/downloads/past-releases,然后解压,然后要有对应的java8,即必须先安装j ...
- 算法抽象及用Python实现具体算法
一.算法抽象 它们一般是在具体算法的基础上总结.提炼.分析出来的,再反过来用于指导解决其它问题.它们适用于某一类问题的解决,用辩 证法的观点看,抽象的算法和具体的算法就是抽象与具体.普遍性与特殊性.共 ...
- oracle(十)临时表
1.临时表的特点 (1)多用户操作的独立性:对于使用同一张临时表的不同用户,oracle都会分配一个独立的 Temp Segment,这样就避免了多个用户在对同一张临时表操作时 发生交叉,从而保证了多 ...
- 类似CFS程式发布注意事项
1.CFS 此AP 程式的验证方式为Forms 验证.需要在IIS 中做如下设置(Forms 身份验证,配套的Web.config 中要有对应节点代码,后台代码中要有获取方式) 2.Forms 身份验 ...
- 【剑指offer】旋转数组的最小数字
一.题目: 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转. 输入一个非减排序的数组的一个旋转,输出旋转数组的最小元素. 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个 ...
- 万恶之源 - Python运算符与编码
格式化输出 现在有个需要我们录入我们身边好友的信息,格式如下: ------------ info of Alex Li ---------- Name : Alex Li Age : 22 job ...
- [py][mx]django分页第三方模块django-pure-pagination
前台的这些数据都是从后台取来的 分页模块django-pure-pagination - 一款基于django pagination封装的更好用的分页模块 https://github.com/jam ...