一致性Hash算法原理及C#代码实现
一、一致性Hash算法原理
基本概念
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
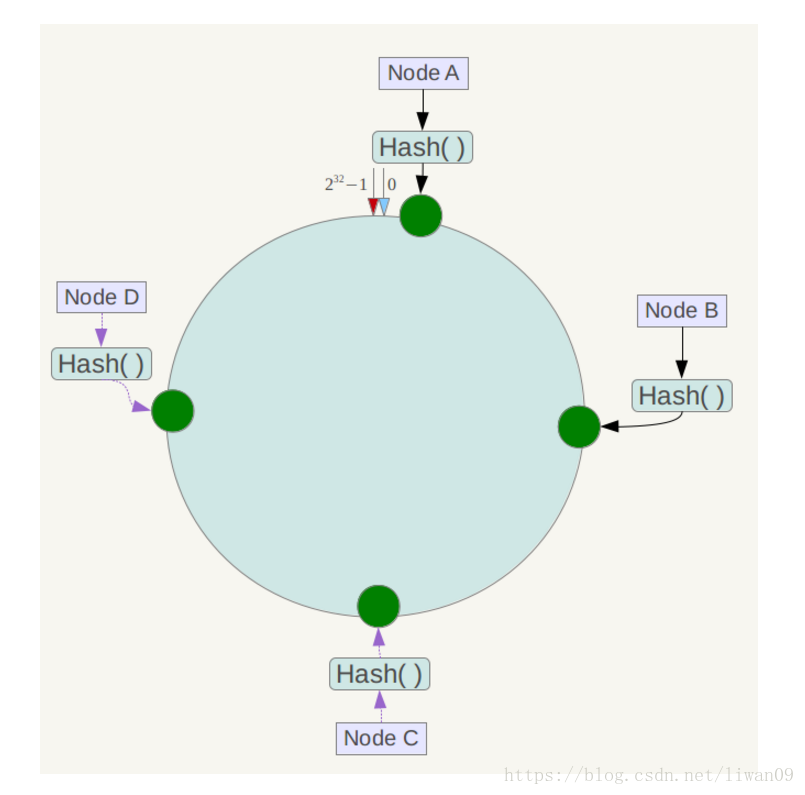
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
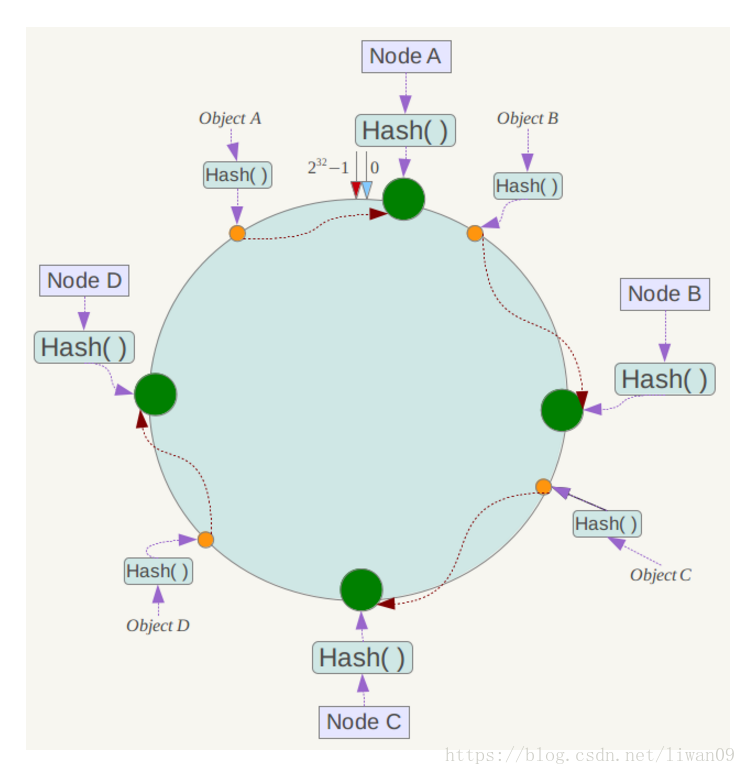
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
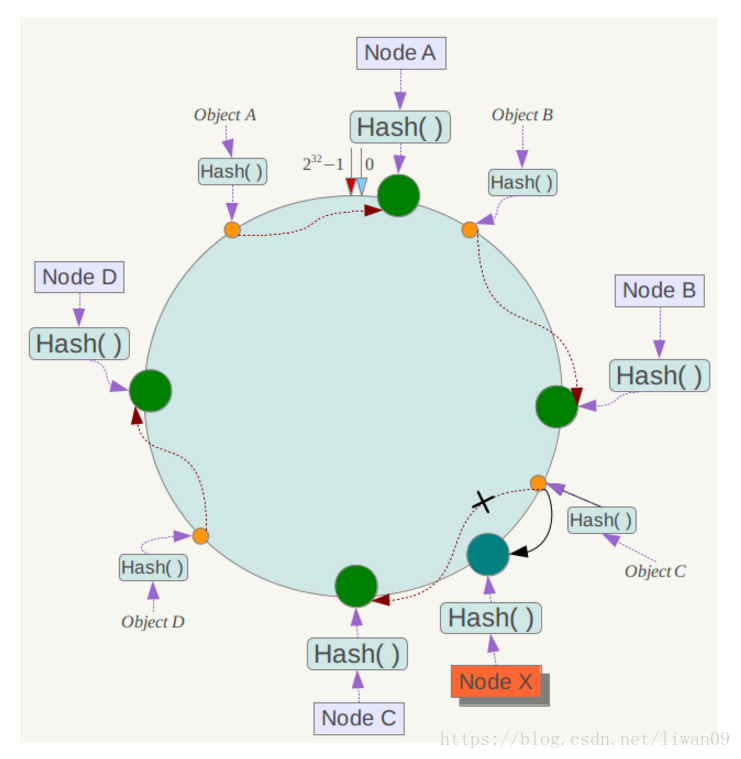
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下:
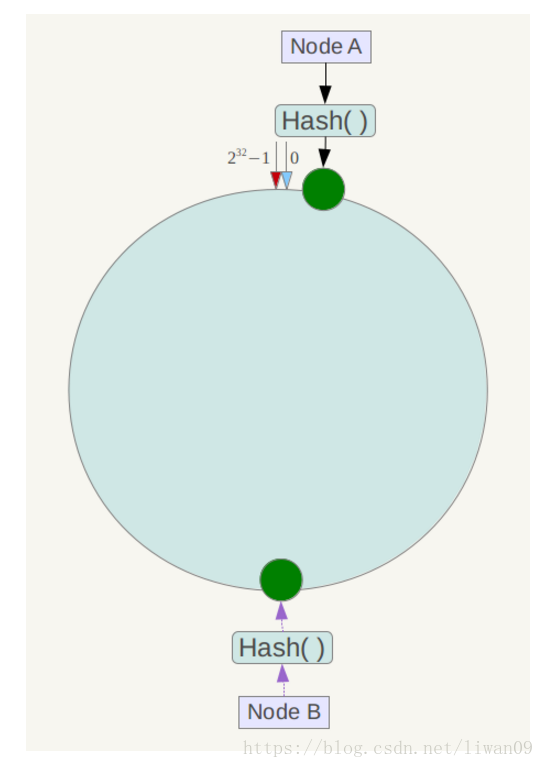
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
二、C#代码实现
public class KetamaNodeLocator
{ private SortedList<long, string> ketamaNodes = new SortedList<long, string>();
private HashAlgorithm hashAlg;
private int numReps = 160; public KetamaNodeLocator(List<string> nodes/*,int nodeCopies*/)
{
ketamaNodes = new SortedList<long, string>();
//numReps = nodeCopies;
//对所有节点,生成nCopies个虚拟结点
foreach (string node in nodes)
{
//每四个虚拟结点为一组
for (int i = 0; i < numReps /4; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0));
return rv;
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//如果找到这个节点,直接取节点,返回
if (!ketamaNodes.ContainsKey(key))
{ var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == 0)
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
}
public class HashAlgorithm
{
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 + nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 + nTime * 4] & 0xFF) << 8)
| ((long)digest[0 + nTime * 4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider(); byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
}
一致性Hash算法原理及C#代码实现的更多相关文章
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 一致性Hash算法原理,java实现,及用途
学习记录: 一致性Hash算法原理及java实现:https://blog.csdn.net/suifeng629/article/details/81567777 一致性Hash算法介绍,原理,及使 ...
- 一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题: 解决分布式系统中的负载均衡问题 背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务 硬Hash映射:将 ...
- 一致性Hash算法(KetamaHash)的c#实现
Consistent Hashing最大限度地抑制了hash键的重新分布.另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上.因为使用一般的 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- 一致性Hash算法与代码实现
一致性Hash算法: 先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值 ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
随机推荐
- MVC源码学习之AuthorizeAttribute
常见的Controller定义方式: public class HomeController : Controller { public ActionResult Index() { return V ...
- Hive Tunning(三) 最佳实践
在上一讲的基础上,我们来做来一个实际的例子来展示如何在实操中进行高效的hive查询作业. (1)首先我们建立一个表 CREATE EXTERNAL TABLE pos_staging( txnid S ...
- 计算MySQL的内存峰值公式
-- 计算MySQL的内存峰值公式,计算所有的连接满了的情况下:select (@@key_buffer_size + @@query_cache_size + @@tmp_table_size ...
- HTML(四):行级标签和块级标签
一.行级标签 行级标签又称为内联标签,行级标签不会单独占据一行,设置宽高无效,行内内部可以容纳其他行内元素,但不可以容纳块元素,不然会出现无法预知的效果. 常见行级标签: span.strong.em ...
- PCL深度图像(1)
目前深度图像的获取方法有激光雷达深度成像法,计算机立体视觉成像,坐标测量机法,莫尔条纹法,结构光法等等,针对深度图像的研究重点主要集中在以下几个方面,深度图像的分割技术 ,深度图像的边缘检测技术 ,基 ...
- Kryonet client disconnects after send a packet to server (java)
http://stackoverflow.com/questions/25934876/kryonet-client-disconnects-after-send-a-packet-to-server ...
- HTML Notes
Label tag and input in form <form action=""> <label for="male">Male& ...
- selenium+java-查找页面中包含关键字的URL
package seleniumLearn1; import java.io.File; import java.io.FileOutputStream; import java.io.IOExcep ...
- VIM中 文件的打开与保存
用 :edit 命令打开一个文件 :edit + {filename} 就可以打开一个文件到缓冲区中, 并且可以加文件路经的: 在路经中, %表示当前文件的完整路经, 用:h 可以 ...
- C# 在托盘显示图标
//上面一行是主窗体InitializeComponent()方法中需要添加的引用 this.SizeChanged += new System.EventHandler(this.Form1_Siz ...