FlumeNG 笔记
环境:CentOS6.6 64位 + FlumeNG 1.6
请参考推荐文档:
Flume-ng的原理和使用 - JunezChen Blog - SegmentFault https://segmentfault.com/a/1190000002532284
已经很全面了,没必要自己写一份文档,更多内容可以参考Flume安装包里doc目录下的自带文档
一、安装
注意:需要预先安装JDK,因为flume是基于Java的;
Flume是没有高可用HA的,但是可以使用拦截器、渠道选择器等高级组件实现负载均衡等功能;
Flume经常和Kafka配合使用。
1、下载并解压FlumeNG
[root@root ~]# wget http://124.205.69.169/files/A1540000011ED5DB/mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
[root@root ~]# tar -zxvf apache-flume-1.6.-bin.tar.gz -C /opt/
[root@root ~]# cd /opt/
[root@root opt]# mv apache-flume-1.6.-bin apache-flume
2、修改环境变量、启动
[root@root opt]# cd apache-flume/
[root@root apache-flume]# cp conf/flume-env.sh.template conf/flume-env.sh
[root@crxy99 apache-flume]# vim conf/flume-env.sh #修改JAVA_HOME
23行: export JAVA_HOME=/opt/jdk1..0_45
[root@crxy99 apache-flume]# vim conf/example.conf #创建agent模板配置文件
[root@crxy99 apache-flume]# bin/flume-ng agent --conf conf/ --conf-file conf/example.conf --name a1 -Dflume.monitoring.type=http -Dflume.monitoring.port= -Dflume.root.logger=INFO,console & #启动脚本
补充:
1)、模板example.conf:
#配置一个agent 名字为a1
#声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 配置r1 使用netcat的source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # 配置k1 使用loggersink
a1.sinks.k1.type = logger # 配置c1 使用内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = #连线,将三个组件关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2)、启动脚本的含义:
agent 使用agent数据处理方式
-Dflume.root.logger=INFO,console -D后面的为参数,这里使用打印到控制台的方式,并动态修改log4j的为info级别
3)、关闭服务:
[root@root apache-flume]# jps
Jps
Application
[root@root apache-flume]# kill - #flume目前没有关闭服务的脚本,只能kill
4)、补充:Telnet
在测试、学习阶段可以使用telnet工具进行模拟,linux下安装方式(Windows下自带了Telnet服务,启用即可,可以百度相关文档)
# yum -y install telnet
二、实例
实例1:一个需求:实时监听一个文件(如/test/logs/access.log)的数据增加
分析:1、由于agent方式能提供持续传输数据的服务,因此采用agent数据处理方式;
2、agent组件:source --> channel --> sink
3、动态监控文件的数据的增加情况可以使用命令tail -F 命令(注意不是tail -f,后者不会retry),因此可以使用exec sink
4、假设内存情况是充裕的,不予考虑,采用memory channel
5、假设数据发送到本地:file roll sink
如下图所示(开发过程中画图可以很好的理解项目数据采集流程,推荐使用):
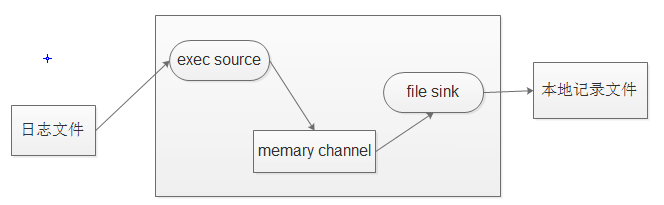
因此:编写agent配置文件:
#配置一个agent 名字为a1
#、声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #、配置r1 使用exec的source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /test/logs/access.log # 配置c1 使用file的channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /test/flume_checkpoint #检查点数据存放目录
a1.channels.c1.dataDirs = /test/flume_datadir #数据存储目录
a1.channels.c1.transactionCapacity = # 配置k1 使用file rolling sink
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /test/flumefile #文件存放目录
a1.sinks.k1.sink.rollInterval = #每天产生一个新文件(单位:s) #、连线,将三个组件关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
$ nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/execsource_filerollsink.conf &
注:flume进程启动动没有关闭的命令,只能kill掉。:
实战2:若上面的文件在某一时刻出现高并发的情况,flume很容易挂掉,如何处理?
说明:在高并发情况下,若不更改默认配置,flume容易出现内存溢出的错误。这是因为它默认的堆初始内存只有20M,可以编辑环境变量
# vim conf/flume-env.sh,去掉下面一行注释的设置,并根据需要调整初始内存和最大分配内存。
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
注:20M源于/bin/flume-ng里的默认设置:JAVA_OPTS="-Xmx20m"
参考:Flume 1.6.0 User Guide — Apache Flume http://flume.apache.org/FlumeUserGuide.html
注:解压后的flume目录下有docs目录,下面的说明文档与该官网的一致,非常人性化!
FlumeNG 笔记的更多相关文章
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- 即将上线的flume服务器面临的一系列填坑笔记
即将上线的flume服务器面临的一系列填坑笔记 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.flume缺少依赖包导致启动失败! 报错信息如下: 2018-10-17 ...
- Spark Streaming笔记
Spark Streaming学习笔记 liunx系统的习惯创建hadoop用户在hadoop根目录(/home/hadoop)上创建如下目录app 存放所有软件的安装目录 app/tmp 存放临时文 ...
- Kafka笔记整理(一)
Kafka简介 消息队列(Message Queue) 消息 Message 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列 Queue 一种特殊的线性表(数 ...
- spark streaming 笔记
spark streaming项目 学习笔记 为什么要flume+kafka? 生成数据有高峰与低峰,如果直接高峰数据过来flume+spark/storm,实时处理容易处理不过来,扛不住压力.而选用 ...
- git-简单流程(学习笔记)
这是阅读廖雪峰的官方网站的笔记,用于自己以后回看 1.进入项目文件夹 初始化一个Git仓库,使用git init命令. 添加文件到Git仓库,分两步: 第一步,使用命令git add <file ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- SQL Server技术内幕笔记合集
SQL Server技术内幕笔记合集 发这一篇文章主要是方便大家找到我的笔记入口,方便大家o(∩_∩)o Microsoft SQL Server 6.5 技术内幕 笔记http://www.cnbl ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
随机推荐
- js的replace函数入参为function时的疑问
近期在写js导出excel文件时运用到replace方法,此处详细的记录下它各个参数所代表的的意义. 定义和用法 replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式 ...
- 5种处理js跨域问题方法汇总(转载)
1.JSONP跨域GET请求 ajax请求,dataType为jsonp.这种形式需要请求在服务端调整为返回callback([json-object])的形式.如果服务端返回的是普通json对象.那 ...
- UDAD 用户故事驱动的敏捷开发 – 演讲实录
敏捷发展到今天已经在软件行业得到了广泛认可,但大多数敏捷方法都是为了解决某一特定问题而总结出来的特定方法或实践,一直缺乏一个可以将整个开发过程串接起来的成体系的方法.用户故事驱动的敏捷开发(User ...
- js动态添加事件-事件委托
作者:白狼 出处:http://www.manks.top/javascript-dynamic-event.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- 遇到的Exception/error及解决办法记录汇总
一.java.net.SocketException 1.java.net.SocketException:Connection reset 首先,如果一端的Socket被关闭(或主动关闭,或因为异常 ...
- RabbitMQ 高可用集群搭建及电商平台使用经验总结
面向EDA(事件驱动架构)的方式来设计你的消息 AMQP routing key的设计 RabbitMQ cluster搭建 Mirror queue policy设置 两个不错的RabbitMQ p ...
- linux 下安装web开发环境
以下使用 linux centos系统 一.JDK的安装 1.下载jdk-8u111-linux-x64.tar.gz 2.解压该文件,将解压后的文件复制到 /usr/local/jdk1.7 目录下 ...
- [LeetCode] Search a 2D Matrix II 搜索一个二维矩阵之二
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
- [LeetCode] Compare Version Numbers 版本比较
Compare two version numbers version1 and version1.If version1 > version2 return 1, if version1 &l ...