MYSQL实现排名函数RANK,DENSE_RANK和ROW_NUMBER
1. 排名分类
1.1 区别RANK,DENSE_RANK和ROW_NUMBER
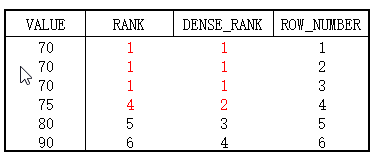
- RANK并列跳跃排名,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,跳跃到总共的排名。
- DENSE_RANK并列连续排序,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,依然按照连续数字排名。
- ROW_NUMBER连续排名,即使相同的值,依旧按照连续数字进行排名。
区别如图:
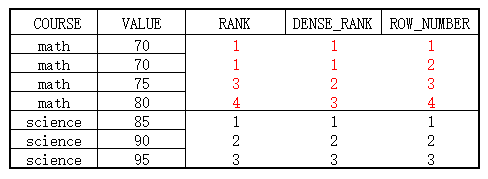
1.2 分组排名
将数据分组后排名,区别如图:
2. 准备数据
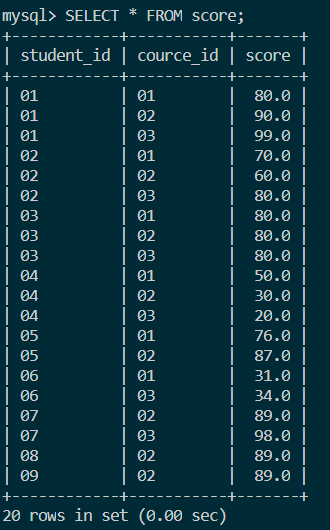
创建一张分数表,里面有字段:分数score,课程号course_id和学生号student_id。
执行如下SQL语句,进行导入数据。
create table score(
student_id varchar(10),
course_id varchar(10),
score decimal(18,1)
); insert into score values('01' , '01' , 80);
insert into score values('01' , '02' , 90);
insert into score values('01' , '03' , 99);
insert into score values('02' , '01' , 70);
insert into score values('02' , '02' , 60);
insert into score values('02' , '03' , 80);
insert into score values('03' , '01' , 80);
insert into score values('03' , '02' , 80);
insert into score values('03' , '03' , 80);
insert into score values('04' , '01' , 50);
insert into score values('04' , '02' , 30);
insert into score values('04' , '03' , 20);
insert into score values('05' , '01' , 76);
insert into score values('05' , '02' , 87);
insert into score values('06' , '01' , 31);
insert into score values('06' , '03' , 34);
insert into score values('07' , '02' , 89);
insert into score values('07' , '03' , 98);
insert into score values('08' , '02' , 89);
insert into score values('09' , '02' , 89);
查看数据:
3. 不分组排名
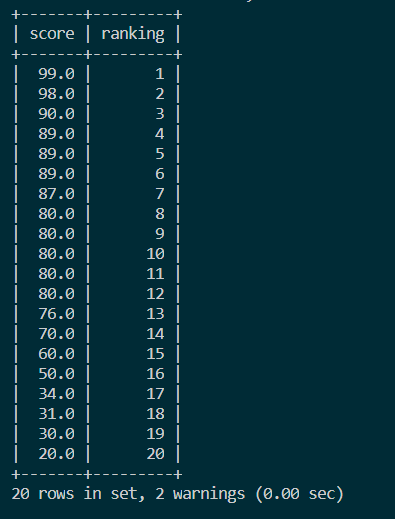
3.1 连续排名
- 使用
ROW_NUMBER实现:SELECT score,
ROW_NUMBER() OVER (ORDER BY score DESC) ranking
FROM score; - 使用
变量实现:SELECT s.score, (@cur_rank := @cur_rank + 1) ranking
FROM score s, (SELECT @cur_rank := 0) r
ORDER BY score DESC;
结果如图:
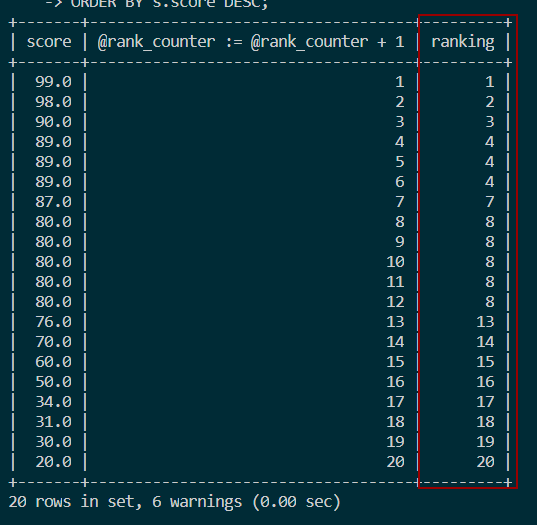
3.2 并列跳跃排名
- 使用
RANK实现:SELECT course_id, score,
RANK() OVER(ORDER BY score DESC)
FROM score; - 使用
变量和IF语句实现:SELECT s.score,
@rank_counter := @rank_counter + 1,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC; - 使用
变量和CASE语句实现:SELECT s.score,
@rank_counter := @rank_counter + 1,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @rank_counter
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
结果如图:
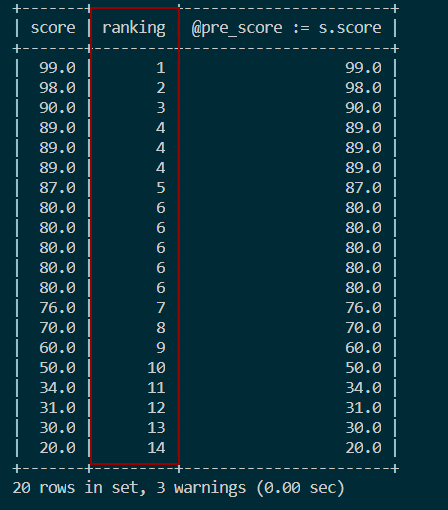
3.3 并列连续排名
- 使用
DENSE_RANK实现:SELECT course_id, score,
DENSE_RANK() OVER(ORDER BY score DESC) FROM score;
- 使用
变量和IF语句实现:SELECT s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:SELECT s.score,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @cur_rank + 1
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;结果如图:
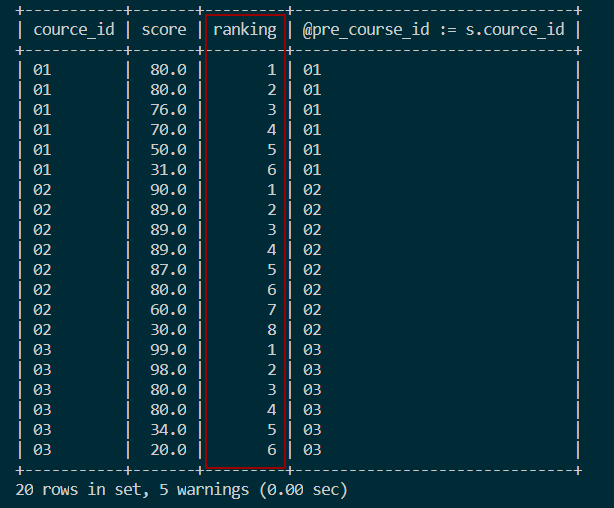
4. 分组排名
4.1 分组连续排名
- 使用
ROW_NUMBER实现:SELECT course_id, score,
ROW_NUMBER() OVER (PARTITION BY course_id ORDER BY score DESC) ranking FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id, @cur_rank := @cur_rank + 1, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;结果如图:
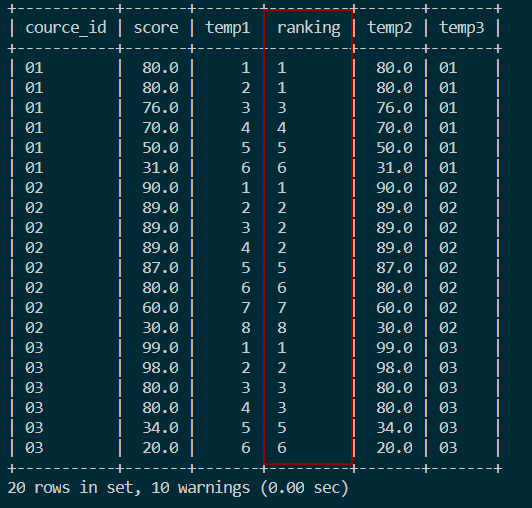
4.2 分组并列跳跃排名
- 使用
RANK实现:SELECT course_id, score,
RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
@rank_counter := @rank_counter + 1,
@rank_counter := 1) temp1,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter),
@cur_rank := 1) ranking,
@pre_score := s.score temp2,
@pre_course_id := s.course_id temp3
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL, @pre_score := NULL, @rank_counter := 1)r
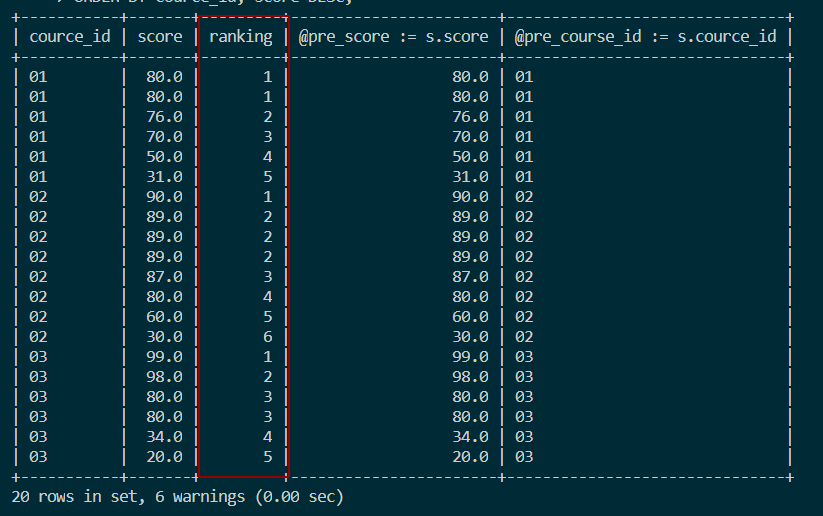
ORDER BY s.course_id, s.score DESC;结果如图:
4.3 分组并列连续排名
- 使用
DENSE_RANK实现:SELECT course_id, score,
DENSE_RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1),
@cur_rank := 1) ranking,
@pre_score := s.score,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;可以将上述的IF条件提取出来:
SELECT s.course_id, s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) temp1,
@pre_score := s.score temp2,
IF(@pre_course_id = s.course_id, @cur_rank, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;结果如图:
MYSQL实现排名函数RANK,DENSE_RANK和ROW_NUMBER的更多相关文章
- sql server 排名函数:DENSE_RANK
一.需求 之前sql server 的排名函数用得最多的应该是RoW_NUMBER()了,我通常用ROW_NUMBER() + CTE 来实现分页:今天逛园,看到另一个内置排名函数还不错,自己顺便想了 ...
- Oracle排名函数(Rank)实例详解
这篇文章主要介绍了Oracle排名函数(Rank)实例详解,需要的朋友可以参考下 --已知:两种排名方式(分区和不分区):使用和不使用partition --两种计算方式(连续,不连续),对应 ...
- Oracle 的开窗函数 rank,dense_rank,row_number
1.开窗函数和分组函数的区别 分组函数是指按照某列或者某些列分组后进行某种计算,比如计数,求和等聚合函数进行计算. 开窗函数是指基于某列或某些列让数据有序,数据行数和原始数据数相同,依然能曾现个体数据 ...
- 【MySQL】排名函数
https://www.cnblogs.com/shizhijie/p/9366247.html 排名函数 主要有rank和dense_rank两种 区别: rank在排名的时候,排名的键一样的时候是 ...
- rank,dense_rank和row_number函数区别
我对技术一般抱有够用就好的态度,一般在网上或者书上找了贴合的解决方案,放到实际中发现好用就行了,不再深究,等出了问题再说. 因此,我对Oracle中中形成有效序列的方法集中在rownum,row_nu ...
- SQL窗口函数RANK(),Dense_Rank(),row_number(),NTILE()
数据源 CREATE TABLE student( no int, ca ), name ), subject ), scorce int ); /* 数据 */ , ); , ); , ); , ) ...
- SQL2005四个排名函数(row_number、rank、dense_rank和ntile)的比较
排名函数是SQL Server2005新加的功能.在SQL Server2005中有如下四个排名函数: .row_number .rank .dense_rank .ntile 下面分别介绍一下这四个 ...
- ORACLE,DECODE函数和排名函数DENSE_RANK函数的使用
这几天写一个报表的页面,从很恶心的数据结构中做一个聚合函数的查询,结构大概是这个样子的: 所以有:对数据group by t.id,t.name.t.course 这样三层排序,然后用函数去取值. d ...
- SQLServer学习笔记<>.基础知识,一些基本命令,单表查询(null top用法,with ties附加属性,over开窗函数),排名函数
Sqlserver基础知识 (1)创建数据库 创建数据库有两种方式,手动创建和编写sql脚本创建,在这里我采用脚本的方式创建一个名称为TSQLFundamentals2008的数据库.脚本如下: ...
- 好用的排名函数~ROW_NUMBER(),RANK(),DENSE_RANK() 三兄弟
排名函数三兄弟,一看名字就知道,都是为了排名而生!但是各自有各自的特色!以下一个例子说明问题!(以下栗子没有使用Partition By 的关键字,整个结果集进行排序) RANK 每个值一个排名,同样 ...
随机推荐
- Docker 安全加固
一.docker安全加固 1.利用LXCFS增强docker容器隔离性和资源可见性 (proc容器与宿主机之间是共享的 没有进行隔离) 此rpm包在真机桌面q目录中 需先传到虚拟机/root/下 在 ...
- 关于easyocr、paddleocr、cnocr之比较
关于easyocr.paddleocr.cnocr之比较 EasyOCR 是一个使用 Java 语言实现的 OCR 识别引擎(基于Tesseract).借助几个简单的API,即能使用Java语言完成图 ...
- DOS命令操作
打开CMD的方式 1.开始+系统+命令提示符 2.Win键+R 输入CMD打开控制台(推荐使用) 3.在任意的文件夹下面,按住shift+鼠标右键点击,在此处打开命令行窗口 4.资源管理器的地址栏前面 ...
- taskkill报taskkill不是内部或者外部命令,也不是可运行程序
转载一下处理这个'taskkill报taskkill不是内部或者外部命令,也不是可运行程序' 的问题:https://blog.csdn.net/wangying_2016/article/detai ...
- ios打开第三方地图app
https://www.jianshu.com/p/691dd39cb28c [ios调起 地图app]分三步: 1.配置相对于地图app的LSApplicationQueriesSchemes白名单 ...
- CNN模型踩坑记录
刚刚在跑textCNN的模型,加载了字典后,在同样的输入下模型的输出一直在变化,先发现损失函数一直在变化,不停debug之后发现是模型的输出一直在变化,在模型输入一直不变下模型输出不同,最后发现是模型 ...
- git学习资料汇总
学习持续开发和持续继承CI/CD https://zhuanlan.zhihu.com/p/609519307 git工作流主题 https://github.com/oldratlee/trans ...
- verilog 和system verilog 文件操作
1. 文件操作 Verilog具有系统任务和功能,可以打开文件.将值输出到文件.从文件中读取值并加 载到其他变量和关闭文件. 1.1 Verilog文件操作 1.1.1 打开和关闭文件 module ...
- C# 当页面有很多选择条件时的处理方式
如下图,用户可能输入很多条件 在后端的处理方式: 使用键值对 private Dictionary<string, string> CreatSearchPara() { Dictiona ...
- idea的小tip
1. 校验正则表达式 String类型的matches方法中键入option+return选择 check regexp可以测试正则的正确性