elasticsearch global 、 filters 和 cardinality 聚合
1. 背景
此处将单记录一下 global 、 filters和cardinality的聚合操作。
2、解释
1、global
global聚合是全局聚合,是对所有的文档进行聚合,而不受查询条件的限制。
global 聚合器只能作为顶级聚合器,因为将一个 global 聚合器嵌入另一个桶聚合器是没有意义的。
比如: 我们有50个文档,通过查询条件筛选之后存在10个文档,此时我想统计总共有多少个文档。是50个,因为global统计不受查询条件的限制。
2、filters
定义一个多桶聚合,其中每个桶都与一个过滤器相关联。每个桶都会收集与其关联的过滤器匹配的所有文档。
比如: 我们总共有50个文档,通过查询条件筛选之后存在10个文档,此时我想统计 这10个文档中,出现info词语的文档有多少个,出现warn词语的文档有多少个。
3、cardinality
类似于 SQL中的 COUNT(DISTINCT(字段)),不过这个是近似统计,是基于 HyperLogLog++ 来实现的。
3、需求
我们有一组日志,每条日志都存在id和message2个字段。此时根据message字段过滤出存在info warn的日志,然后进行统计:
- 系统中总共有多少条日志(
global + cardinality) - info和warn级别的日志各有多少条(
filters)
4、前置条件
4.1 创建mapping
PUT /index_api_log
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"message":{
"type": "text"
},
"id": {
"type": "long"
}
}
}
}
4.2 准备数据
PUT /index_api_log/_bulk
{"index":{"_id":1}}
{"message": "this is info message-01","id":1}
{"index":{"_id":2}}
{"message": "this is info message-02","id":2}
{"index":{"_id":3}}
{"message": "this is warn message-01","id":3}
{"index":{"_id":4}}
{"message": "this is error message","id":4}
{"index":{"_id":5}}
{"message": "this is info and warn message","id":5}
5、实现3的需求
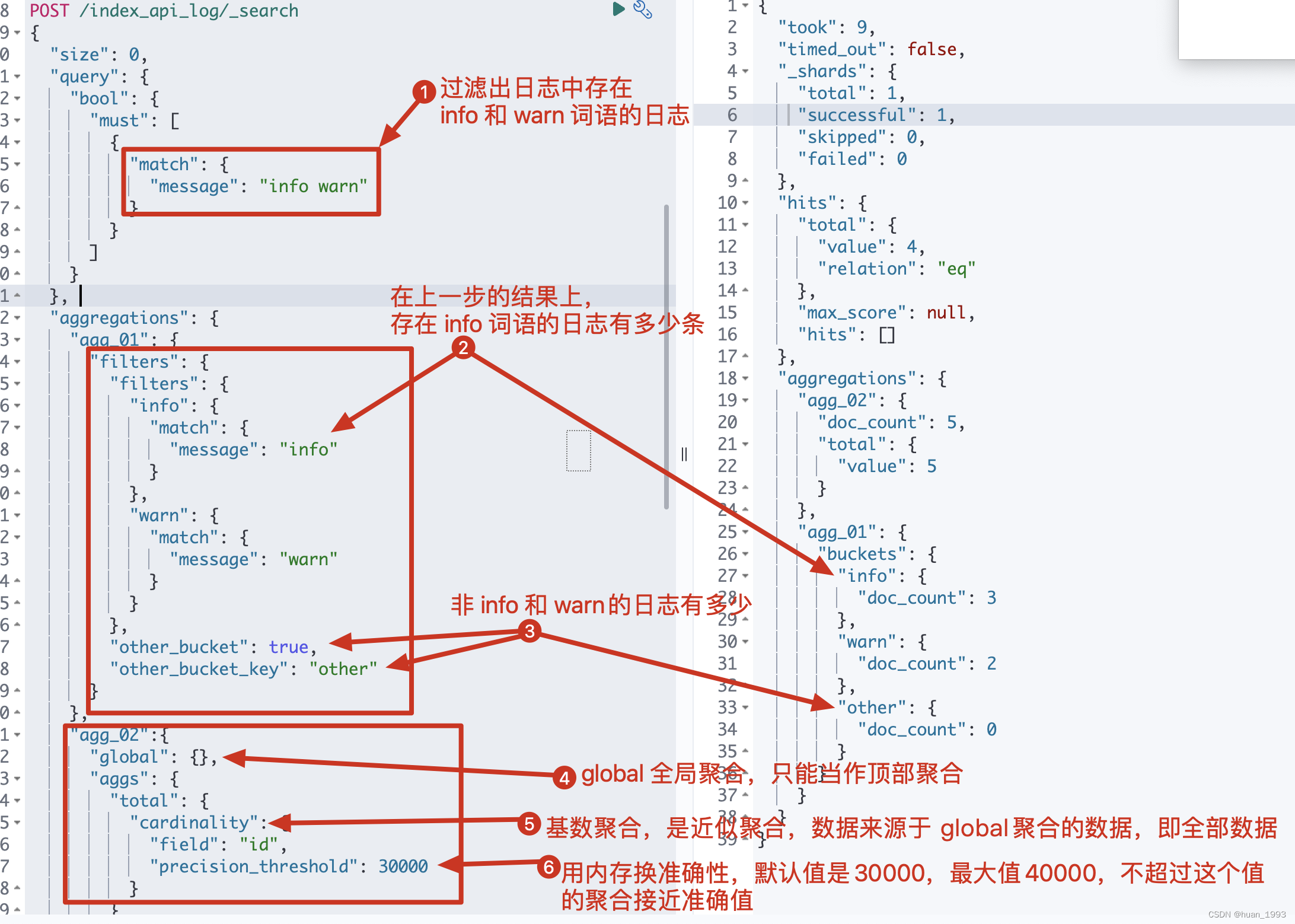
5.1 dsl
POST /index_api_log/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"match": {
"message": "info warn"
}
}
]
}
},
"aggregations": {
"agg_01": {
"filters": {
"filters": {
"info": {
"match": {
"message": "info"
}
},
"warn": {
"match": {
"message": "warn"
}
}
},
"other_bucket": true,
"other_bucket_key": "other"
}
},
"agg_02":{
"global": {},
"aggs": {
"total": {
"cardinality": {
"field": "id",
"precision_threshold": 30000
}
}
}
}
}
}
5.2 java 代码
@Test
@DisplayName("global and filters and cardinality 聚合")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index("index_api_log")
// 查询 message 中存在 info 和 warn 的日志
.query(query -> query.bool(bool -> bool.must(must -> must.match(match -> match.field("message").query("info warn")))))
// 查询的结果不返回
.size(0)
// 第一个聚合
.aggregations("agg_01", agg ->
agg.filters(filters ->
filters.filters(f ->
f.array(
Arrays.asList(
// 在上一步query的结果中,将 message中包含info的进行聚合
Query.of(q -> q.match(m -> m.field("message").query("info"))),
// 在上一步query的结果中,将 message中包含warn的进行聚合
Query.of(q -> q.match(m -> m.field("message").query("warn")))
)
)
)
// 如果上一步的查询中,存在非 info 和 warn的则是否聚合到 other 桶中
.otherBucket(true)
// 给 other 桶取一个名字
.otherBucketKey("other")
)
)
// 第二个聚合
.aggregations("agg_02", agg ->
agg
// 此处的 global 聚合只能放在顶部
.global(global -> global)
// 子聚合,数据来源于所有的文档,不受上一步query结果的限制
.aggregations("total", subAgg ->
// 类似于SQL中的 count(distinct(字段)),是一个近似统计
subAgg.cardinality(cardinality ->
// 统计的字段
cardinality.field("id")
// 精度,默认值是30000,最大值也是40000,不超过这个值的聚合近似准确值
.precisionThreshold(30000)
)
)
)
);
System.out.println("request: " + request);
SearchResponse<String> response = client.search(request, String.class);
System.out.println("response: " + response);
}
5.3 运行结果
6、实现代码
7、参考文档
elasticsearch global 、 filters 和 cardinality 聚合的更多相关文章
- Elasticsearch 第六篇:聚合统计查询
h2.post_title { background-color: rgba(43, 102, 149, 1); color: rgba(255, 255, 255, 1); font-size: 1 ...
- 把 Elasticsearch 当数据库使:聚合后排序
使用 https://github.com/taowen/es-monitor 可以用 SQL 进行 elasticsearch 的查询.有的时候分桶聚合之后会产生很多的桶,我们只对其中部分的桶关心. ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...
- ElasticSearch的高级复杂查询:非聚合查询和聚合查询
一.非聚合复杂查询(这儿展示了非聚合复杂查询的常用流程) 查询条件QueryBuilder的构建方法 1.1 精确查询(必须完全匹配上,相当于SQL语句中的“=”) ① 单个匹配 termQuery ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
- ElasticSearch 的 聚合(Aggregations)
Elasticsearch有一个功能叫做 聚合(aggregations) ,它允许你在数据上生成复杂的分析统计.它很像SQL中的 GROUP BY 但是功能更强大. Aggregations种类分为 ...
- ElasticSearch - 信息聚合系列之聚合过滤
摘要 聚合范围限定还有一个自然的扩展就是过滤.因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上. 版本 elasticsearch版本: elasticsearch-2. ...
- elasticsearch聚合操作——本质就是针对搜索后的结果使用桶bucket(允许嵌套)进行group by,统计下分组结果,包括min/max/avg
分析 Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计.它很像SQL中的GROUP BY但是功能更强大. 举个例子,让我们找到所有职员中最大 ...
- ElasticSearch 2 (33) - 信息聚合系列之聚合过滤
ElasticSearch 2 (33) - 信息聚合系列之聚合过滤 摘要 聚合范围限定还有一个自然的扩展就是过滤.因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上. 版 ...
- ElasticSearch 2 (30) - 信息聚合系列之条形图
ElasticSearch 2 (30) - 信息聚合系列之条形图 摘要 版本 elasticsearch版本: elasticsearch-2.x 内容 聚合还有一个令人激动的特性就是能够十分容易地 ...
随机推荐
- 前端三件套 HTML+CSS+JS基础知识内容笔记
HTML基础 目录 HTML基础 HTML5标签 doctype 标签 html标签 head标签 meta标签 title标签 body标签 文本和超链接标签 标题标签 段落标签 换行标签 水平标签 ...
- C++实现双向RRT算法
C++实现双向RRT算法 背景介绍 RRT(Rapidly-exploring Random Trees)是Steven M. LaValle和James J. Kuffner Jr.提出的一种通过所 ...
- Python(一)转义字符及操作符
转义字符 描述 \(在行尾时) 续航符 \\ 反斜杠符号 \' 单引号 \'' 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 转行 \v 纵向制表符 \t 横向 ...
- 自己动手写ls命令——Java版
自己动手写ls命令--Java版 介绍 在前面的文章Linux命令系列之ls--原来最简单的ls这么复杂当中,我们仔细的介绍了关于ls命令的使用和输出结果,在本篇文章当中我们用Java代码自己实现ls ...
- JavaFx 使用字体图标记录
原文:JavaFx 使用字体图标记录 - Stars-One的杂货小窝 之前其实也是研究过关于字体图标的使用,还整了个库Tornadofx学习笔记(4)--IconTextFx开源库,整合5000+个 ...
- 小白转行入门STM32----手机蓝牙控制STM32单片机点亮LED
@ 目录 引言导读 一.通信基础知识 1.1 通信到底传输的是什么? 1.2 比特率和波特率 习题 1.1 双工和单工 习题 1.2 串行和并行 1.3 异同通信和同步通信 习题 二.连接STM32单 ...
- Collection接口中的方法的使用
add(Object e):将元素e添加到集合coll中size():获取添加的元素的个数addAll(Collection coll1):将coll1集合中的元素添加到当前的集合中clear():清 ...
- Springboot 一行代码实现文件上传 20个平台!少写代码到极致
大家好,我是小富~ 技术交流,公众号:程序员小富 又是做好人好事的一天,有个小可爱私下问我有没有好用的springboot文件上传工具,这不巧了嘛,正好我私藏了一个好东西,顺便给小伙伴们也分享一下,d ...
- 8.DRF请求响应和api_view
一.请求对象(Request objects) DRF引入了一个扩展Django常规HttpRequest对象的Request对象,并提供了更灵活的请求解析能力 Request对象的核心功能是re ...
- 九、Django3的ASGI
九.Django3的ASGI 9.1.Web应用程序和web服务器 Web应用程序(Web)是一种能完成web业务逻辑,能让用户基于web浏览器访问的应用程序,它可以是一个实现http请求和响应功能的 ...