TCP 异常断开连接的过程
Tcp连接正常断开的情况,大家都了解,也就是一端发送Fin报文开启四次挥手,然后 sock 结构销毁,但是我之前很少去追踪 Tcp 在对端宕机,进程 Crash 之后的行为逻辑。前段时间正巧遇到了这样一个场景: 进程 A 通过 Tcp 连接关联了进程 B,同时进程B还有个备份进程进程C,A在感知到进程B断开连接后会切换到进程C,但是使用的时候没有深入了解这个切换过程需要多久,后来整理了下协议栈中的相关逻辑,了解了进程A大概需要多长时间感知到进程B断开连接。
异常主要分为四种情况:
一:进程B Crash,但进程B所在的宿主机仍然正常工作。
二:进程B所在的宿主机宕机,又迅速重启。
三:进程B所在的宿主机宕机,短时间内没有重启,从A出发的所有报文都被网络丢弃。
四:B已经断网/宕机/进程Crash,但此时A主机也没有需要向B发送的数据。
下面就是要从协议栈上看一下,在这几种情况下socket都需要多长时间才能收到断开连接的事件,以及中间到底发生了什么,这里的断开事件一般就是socket的可读事件,然后返回一个错误码,例如ETIMEOUT。
情况一:进程B Crash,进程B所在的宿主机仍然正常工作
这种情况我们通过 kill 命令直接杀进程就会出现,它的表现和进程调用Close类似,进程终止后,Socket会变成 Orphan Socket,会一个优雅的方式结束连接,即会向对端发送Fin报文,走正常关闭连接的那一套逻辑。
16:42:07.948662 IP localhost.8000 > localhost.59082: Flags [F.], seq 923610111, ack 12287042, win 86, options [nop,nop,TS val 205205320 ecr 205186343], length 0
Orphan Socket 有点像僵尸进程,也会占用系统资源,可以通过下面的配置项进行修改最大数量。
proc/sys/net/ipv4/tcp_max_orphans
情况二:进程B所在的宿主机宕机,又迅速重启
这种情况下,如果A进程恰好有发往B进程的Tcp报文,B重启前都会被丢弃,此时A可能回进入Rto状态,不断重发重传队列内的报文,在B主机被拉起后,重发的报文会被Linux协议栈接收,经过ip层处理,函数 tcp_v4_rcv 会在全局Socket哈希表中找处理该报文的Socket(监听目标端口的Socket,或者已建立连接的Socket),找到则交由该Socket处理,找不到则会向发送端回复Rst报文。


int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
struct sk_buff *skb_to_free;
int sdif = inet_sdif(skb);
int dif = inet_iif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret; if (skb->pkt_type != PACKET_HOST)
goto discard_it; /* Count it even if it's bad */
__TCP_INC_STATS(net, TCP_MIB_INSEGS); if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
goto discard_it; th = (const struct tcphdr *)skb->data; if (unlikely(th->doff < sizeof(struct tcphdr) / 4))
goto bad_packet;
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it; /* An explanation is required here, I think.
* Packet length and doff are validated by header prediction,
* provided case of th->doff==0 is eliminated.
* So, we defer the checks. */ if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo))
goto csum_error; th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
lookup:
// 从所有Socket(已连接和监听中)查找该 skb 所属的 Socket
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted);
// 未找到 skb 所属Socket, 发送 Rst 报文
if (!sk)
goto no_tcp_socket; process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait; if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
bool req_stolen = false;
struct sock *nsk; sk = req->rsk_listener;
if (unlikely(tcp_v4_inbound_md5_hash(sk, skb, dif, sdif))) {
sk_drops_add(sk, skb);
reqsk_put(req);
goto discard_it;
}
if (tcp_checksum_complete(skb)) {
reqsk_put(req);
goto csum_error;
}
if (unlikely(sk->sk_state != TCP_LISTEN)) {
inet_csk_reqsk_queue_drop_and_put(sk, req);
goto lookup;
}
/* We own a reference on the listener, increase it again
* as we might lose it too soon.
*/
sock_hold(sk);
refcounted = true;
nsk = NULL;
if (!tcp_filter(sk, skb)) {
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
nsk = tcp_check_req(sk, skb, req, false, &req_stolen);
}
if (!nsk) {
reqsk_put(req);
if (req_stolen) {
/* Another cpu got exclusive access to req
* and created a full blown socket.
* Try to feed this packet to this socket
* instead of discarding it.
*/
tcp_v4_restore_cb(skb);
sock_put(sk);
goto lookup;
}
goto discard_and_relse;
}
if (nsk == sk) {
reqsk_put(req);
tcp_v4_restore_cb(skb);
} else if (tcp_child_process(sk, nsk, skb)) {
tcp_v4_send_reset(nsk, skb);
goto discard_and_relse;
} else {
sock_put(sk);
return 0;
}
}
if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) {
__NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP);
goto discard_and_relse;
} if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
goto discard_and_relse; if (tcp_v4_inbound_md5_hash(sk, skb, dif, sdif))
goto discard_and_relse; nf_reset_ct(skb); if (tcp_filter(sk, skb))
goto discard_and_relse;
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th); skb->dev = NULL; if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
} sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk);
tcp_segs_in(tcp_sk(sk), skb);
ret = 0;
if (!sock_owned_by_user(sk)) {
skb_to_free = sk->sk_rx_skb_cache;
sk->sk_rx_skb_cache = NULL;
ret = tcp_v4_do_rcv(sk, skb);
} else {
if (tcp_add_backlog(sk, skb))
goto discard_and_relse;
skb_to_free = NULL;
}
bh_unlock_sock(sk);
if (skb_to_free)
__kfree_skb(skb_to_free); put_and_return:
if (refcounted)
sock_put(sk); return ret; no_tcp_socket:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard_it; tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) {
csum_error:
__TCP_INC_STATS(net, TCP_MIB_CSUMERRORS);
bad_packet:
__TCP_INC_STATS(net, TCP_MIB_INERRS);
} else {
tcp_v4_send_reset(NULL, skb);
} discard_it:
/* Discard frame. */
kfree_skb(skb);
return 0; discard_and_relse:
sk_drops_add(sk, skb);
if (refcounted)
sock_put(sk);
goto discard_it; do_time_wait:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
inet_twsk_put(inet_twsk(sk));
goto discard_it;
} tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) {
inet_twsk_put(inet_twsk(sk));
goto csum_error;
}
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
case TCP_TW_SYN: {
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),
&tcp_hashinfo, skb,
__tcp_hdrlen(th),
iph->saddr, th->source,
iph->daddr, th->dest,
inet_iif(skb),
sdif);
if (sk2) {
inet_twsk_deschedule_put(inet_twsk(sk));
sk = sk2;
tcp_v4_restore_cb(skb);
refcounted = false;
goto process;
}
}
/* to ACK */
fallthrough;
case TCP_TW_ACK:
tcp_v4_timewait_ack(sk, skb);
break;
case TCP_TW_RST:
tcp_v4_send_reset(sk, skb);
inet_twsk_deschedule_put(inet_twsk(sk));
goto discard_it;
case TCP_TW_SUCCESS:;
}
goto discard_it;
}
假设 B 主机启动后没有监听相关端口,则A的报文便会被 tcp_v4_rcv 函数判定为无效报文,回复 Rst 了事。
情况三:进程B所在的宿主机宕机,且短暂时间内没有重启
这种情况下,A与B的连接处于黑洞状态,A发送向B的所有报文都被丢弃,且没有任何回复,一定时长后便会触发RTO定时器,定时器处理函数会重发丢失的报文,重发的报文由于对端宕机也会被丢弃,就这样一直重传一直被丢弃,直到达到一定阈值,协议栈便会判定链路出现了故障,并通过Socket接口告诉应用程序链路故障,一般就是ETIMEOUT状态码。在Linux 协议栈上,这段逻辑从RTO超时Timer处理函数触发,在通知Socket接口发送数据失败处结束。下面就简单整理了下这段逻辑。
在内核态Tcp Socket 结构创建的时候,协议栈调用了 tcp_init_xmit_timers 函数来初始化一些定时器。
void tcp_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk); tp->out_of_order_queue = RB_ROOT;
sk->tcp_rtx_queue = RB_ROOT;
// 初始化 重传/keepalive/延时确认等 timer
tcp_init_xmit_timers(sk);
INIT_LIST_HEAD(&tp->tsq_node);
INIT_LIST_HEAD(&tp->tsorted_sent_queue); icsk->icsk_rto = TCP_TIMEOUT_INIT;
tp->mdev_us = jiffies_to_usecs(TCP_TIMEOUT_INIT);
minmax_reset(&tp->rtt_min, tcp_jiffies32, ~0U); /* So many TCP implementations out there (incorrectly) count the
* initial SYN frame in their delayed-ACK and congestion control
* algorithms that we must have the following bandaid to talk
* efficiently to them. -DaveM
*/
tp->snd_cwnd = TCP_INIT_CWND; /* There's a bubble in the pipe until at least the first ACK. */
tp->app_limited = ~0U; /* See draft-stevens-tcpca-spec-01 for discussion of the
* initialization of these values.
*/
tp->snd_ssthresh = TCP_INFINITE_SSTHRESH;
tp->snd_cwnd_clamp = ~0;
tp->mss_cache = TCP_MSS_DEFAULT; tp->reordering = sock_net(sk)->ipv4.sysctl_tcp_reordering;
tcp_assign_congestion_control(sk); tp->tsoffset = 0;
tp->rack.reo_wnd_steps = 1; sk->sk_write_space = sk_stream_write_space;
sock_set_flag(sk, SOCK_USE_WRITE_QUEUE); icsk->icsk_sync_mss = tcp_sync_mss; WRITE_ONCE(sk->sk_sndbuf, sock_net(sk)->ipv4.sysctl_tcp_wmem[1]);
WRITE_ONCE(sk->sk_rcvbuf, sock_net(sk)->ipv4.sysctl_tcp_rmem[1]); sk_sockets_allocated_inc(sk);
sk->sk_route_forced_caps = NETIF_F_GSO;
}
这些定时器包括重传定时器(tcp_write_timer ),延时确认定时器(tcp_delack_timer ),Tcp KeepAlive定时器(tcp_keepalive_timer ) 等。
770 void tcp_init_xmit_timers(struct sock *sk)
771 {
// 重传定时器在这里设置
772 inet_csk_init_xmit_timers(sk, &tcp_write_timer, &tcp_delack_timer,
773 &tcp_keepalive_timer);
774 hrtimer_init(&tcp_sk(sk)->pacing_timer, CLOCK_MONOTONIC,
775 HRTIMER_MODE_ABS_PINNED_SOFT);
776 tcp_sk(sk)->pacing_timer.function = tcp_pace_kick;
777
778 hrtimer_init(&tcp_sk(sk)->compressed_ack_timer, CLOCK_MONOTONIC,
779 HRTIMER_MODE_REL_PINNED_SOFT);
780 tcp_sk(sk)->compressed_ack_timer.function = tcp_compressed_ack_kick;
781 }
从调用栈追踪下去, tcp_init_xmit_timers --> tcp_write_timer --> tcp_write_timer_handler --> tcp_retransmit_timer,tcp_retransmit_timer 函数处理的就是重传再超时后的情况
1 void tcp_retransmit_timer(struct sock *sk)
2 {
3 struct tcp_sock *tp = tcp_sk(sk);
4 struct net *net = sock_net(sk);
5 struct inet_connection_sock *icsk = inet_csk(sk);
6
7 if (tp->fastopen_rsk) {
8 WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV &&
9 sk->sk_state != TCP_FIN_WAIT1);
10 tcp_fastopen_synack_timer(sk);
11 /* Before we receive ACK to our SYN-ACK don't retransmit
12 * anything else (e.g., data or FIN segments).
13 */
14 return;
15 }
16 if (!tp->packets_out || WARN_ON_ONCE(tcp_rtx_queue_empty(sk)))
17 return;
18
19 tp->tlp_high_seq = 0;
20
21 if (!tp->snd_wnd && !sock_flag(sk, SOCK_DEAD) &&
22 !((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV))) {
23 /* Receiver dastardly shrinks window. Our retransmits
24 * become zero probes, but we should not timeout this
25 * connection. If the socket is an orphan, time it out,
26 * we cannot allow such beasts to hang infinitely.
27 */
28 struct inet_sock *inet = inet_sk(sk);
29 if (sk->sk_family == AF_INET) {
30 net_dbg_ratelimited("Peer %pI4:%u/%u unexpectedly shrunk window %u:%u (repaired)\n",
31 &inet->inet_daddr,
32 ntohs(inet->inet_dport),
33 inet->inet_num,
34 tp->snd_una, tp->snd_nxt);
35 }
36 #if IS_ENABLED(CONFIG_IPV6)
37 else if (sk->sk_family == AF_INET6) {
38 net_dbg_ratelimited("Peer %pI6:%u/%u unexpectedly shrunk window %u:%u (repaired)\n",
39 &sk->sk_v6_daddr,
40 ntohs(inet->inet_dport),
41 inet->inet_num,
42 tp->snd_una, tp->snd_nxt);
43 }
44 #endif
45 if (tcp_jiffies32 - tp->rcv_tstamp > TCP_RTO_MAX) {
46 tcp_write_err(sk);
47 goto out;
48 }
49 tcp_enter_loss(sk);
50 tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1);
51 __sk_dst_reset(sk);
52 goto out_reset_timer;
53 }
54
55 __NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPTIMEOUTS);
56 // 处理重传次数的逻辑,重传次数达到阈值后通知Socket传输失败
57 if (tcp_write_timeout(sk))
58 goto out;
59
60 if (icsk->icsk_retransmits == 0) {
61 int mib_idx = 0;
62
63 if (icsk->icsk_ca_state == TCP_CA_Recovery) {
64 if (tcp_is_sack(tp))
65 mib_idx = LINUX_MIB_TCPSACKRECOVERYFAIL;
66 else
67 mib_idx = LINUX_MIB_TCPRENORECOVERYFAIL;
68 } else if (icsk->icsk_ca_state == TCP_CA_Loss) {
69 mib_idx = LINUX_MIB_TCPLOSSFAILURES;
70 } else if ((icsk->icsk_ca_state == TCP_CA_Disorder) ||
71 tp->sacked_out) {
72 if (tcp_is_sack(tp))
73 mib_idx = LINUX_MIB_TCPSACKFAILURES;
74 else
75 mib_idx = LINUX_MIB_TCPRENOFAILURES;
76 }
77 if (mib_idx)
78 __NET_INC_STATS(sock_net(sk), mib_idx);
79 }
80
81 tcp_enter_loss(sk);
82
83 if (tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1) > 0) {
84 // 重传失败,一般是由于拥塞窗口不允许,RTO时长不变,重启重传定时器
85 /* Retransmission failed because of local congestion,
86 * do not backoff.
87 */
88 if (!icsk->icsk_retransmits)
89 icsk->icsk_retransmits = 1;
90 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
91 min(icsk->icsk_rto, TCP_RESOURCE_PROBE_INTERVAL),
92 TCP_RTO_MAX);
93 goto out;
94 }
95
96 /* Increase the timeout each time we retransmit. Note that
97 * we do not increase the rtt estimate. rto is initialized
98 * from rtt, but increases here. Jacobson (SIGCOMM 88) suggests
99 * that doubling rto each time is the least we can get away with.
100 * In KA9Q, Karn uses this for the first few times, and then
101 * goes to quadratic. netBSD doubles, but only goes up to *64,
102 * and clamps at 1 to 64 sec afterwards. Note that 120 sec is
103 * defined in the protocol as the maximum possible RTT. I guess
104 * we'll have to use something other than TCP to talk to the
105 * University of Mars.
106 *
107 * PAWS allows us longer timeouts and large windows, so once
108 * implemented ftp to mars will work nicely. We will have to fix
109 * the 120 second clamps though!
110 */
111 icsk->icsk_backoff++;
112 icsk->icsk_retransmits++;
113
114 out_reset_timer:
115 /* If stream is thin, use linear timeouts. Since 'icsk_backoff' is
116 * used to reset timer, set to 0. Recalculate 'icsk_rto' as this
117 * might be increased if the stream oscillates between thin and thick,
118 * thus the old value might already be too high compared to the value
119 * set by 'tcp_set_rto' in tcp_input.c which resets the rto without
120 * backoff. Limit to TCP_THIN_LINEAR_RETRIES before initiating
121 * exponential backoff behaviour to avoid continue hammering
122 * linear-timeout retransmissions into a black hole
123 */
124 // 重传成功后开启RTO退避
125 if (sk->sk_state == TCP_ESTABLISHED &&
126 (tp->thin_lto || net->ipv4.sysctl_tcp_thin_linear_timeouts) &&
127 tcp_stream_is_thin(tp) &&
128 //另一种退避策略
129 icsk->icsk_retransmits <= TCP_THIN_LINEAR_RETRIES) {
130 icsk->icsk_backoff = 0;
131 icsk->icsk_rto = min(__tcp_set_rto(tp), TCP_RTO_MAX);
132 } else {
133 /* Use normal (exponential) backoff */
134 // 指数式退避,每次重传RTO翻倍,直到达到 TCP_RTO_MAX
135 icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
136 }
137
138 // 重启重传定时器
139 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
140 tcp_clamp_rto_to_user_timeout(sk), TCP_RTO_MAX);
141 if (retransmits_timed_out(sk, net->ipv4.sysctl_tcp_retries1 + 1, 0))
142 __sk_dst_reset(sk);
143
144 out:;
145 }
tcp_retransmit_timer 函数会在 tcp_write_timeout 函数内判断重传事件(注意: 这里用的是重传时间,而不是次数,虽然时间也是有次数建模计算得来的)是否超过阈值,没有达到阈值就通过函数 tcp_retransmit_skb 尝试重传重传队列的队首报文,并重置重传定时器,而RTO的值也会采用一定策略进行调整,一般是每次重传后RTO都翻倍,直到达到一个最大值。重传/丢包循环有两个结束条件,一个是重传成功,另一个是达到重传次数阈值,达到阈值的逻辑就在 tcp_write_timeout 函数内实现。
1 /* A write timeout has occurred. Process the after effects. */
2 static int tcp_write_timeout(struct sock *sk)
3 {
4 struct inet_connection_sock *icsk = inet_csk(sk);
5 struct tcp_sock *tp = tcp_sk(sk);
6 struct net *net = sock_net(sk);
7 bool expired = false, do_reset;
8 int retry_until;
9
10 if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
11 // 握手阶段超时
12 if (icsk->icsk_retransmits) {
13 dst_negative_advice(sk);
14 } else {
15 sk_rethink_txhash(sk);
16 tp->timeout_rehash++;
17 __NET_INC_STATS(sock_net(sk),
18 LINUX_MIB_TCPTIMEOUTREHASH);
19 }
20 // 重传次数使用 sysctl_tcp_syn_retries
21 retry_until = icsk->icsk_syn_retries ? : net->ipv4.sysctl_tcp_syn_retries;
22 expired = icsk->icsk_retransmits >= retry_until;
23 } else {
24 // 重传次数达到阈值1,发送链路探测
25 if (retransmits_timed_out(sk, net->ipv4.sysctl_tcp_retries1, 0)) {
26 /* Black hole detection */
27 tcp_mtu_probing(icsk, sk);
28
29 dst_negative_advice(sk);
30 } else {
31 sk_rethink_txhash(sk);
32 tp->timeout_rehash++;
33 __NET_INC_STATS(sock_net(sk),
34 LINUX_MIB_TCPTIMEOUTREHASH);
35 }
36
37 // 重传次数达到阈值2
38 retry_until = net->ipv4.sysctl_tcp_retries2;
39 if (sock_flag(sk, SOCK_DEAD)) {
40 const bool alive = icsk->icsk_rto < TCP_RTO_MAX;
41
42 retry_until = tcp_orphan_retries(sk, alive);
43 do_reset = alive ||
44 !retransmits_timed_out(sk, retry_until, 0);
45
46 if (tcp_out_of_resources(sk, do_reset))
47 return 1;
48 }
49 }
50 // 判断重传是否超时
51 if (!expired)
52 expired = retransmits_timed_out(sk, retry_until,
53 icsk->icsk_user_timeout);
54 tcp_fastopen_active_detect_blackhole(sk, expired);
55
56 if (BPF_SOCK_OPS_TEST_FLAG(tp, BPF_SOCK_OPS_RTO_CB_FLAG))
57 tcp_call_bpf_3arg(sk, BPF_SOCK_OPS_RTO_CB,
58 icsk->icsk_retransmits,
59 icsk->icsk_rto, (int)expired);
60
61 // 达到重传上限,触发socket接口可读时间 ETIMEOUT
62 if (expired) {
63 /* Has it gone just too far? */
64 tcp_write_err(sk);
65 return 1;
66 }
67
68 return 0;
69 }
retransmits_timed_out 判断重传时间是否达到上限。
1 static bool retransmits_timed_out(struct sock *sk,
2 unsigned int boundary,
3 unsigned int timeout)
4 {
5 unsigned int start_ts;
6
7 if (!inet_csk(sk)->icsk_retransmits)
8 return false;
9
10 start_ts = tcp_sk(sk)->retrans_stamp;
11 // 传了timeout则用传进来的timeout,否则用重传次数 boundary 计算出重传超时的时间
12 if (likely(timeout == 0)) {
13 unsigned int rto_base = TCP_RTO_MIN;
14
15 if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV))
16 rto_base = tcp_timeout_init(sk);
17 timeout = tcp_model_timeout(sk, boundary, rto_base);
18 }
19
20 return (s32)(tcp_time_stamp(tcp_sk(sk)) - start_ts - timeout) >= 0;
21 }
tcp_model_timeout 根据设置的重传次数阈值估算重传时间阈值,该函数和 TCP_RETRIES2 参数计算的到的时间应该就是本文一开始要找的时长。
1 static unsigned int tcp_model_timeout(struct sock *sk,
2 unsigned int boundary,
3 unsigned int rto_base)
4 {
5 unsigned int linear_backoff_thresh, timeout;
6
7 // 达到 TCP_RTO_MAX 需要的指数退避次数
8 linear_backoff_thresh = ilog2(TCP_RTO_MAX / rto_base);
9 if (boundary <= linear_backoff_thresh)
10 // 小于指数退避次数阈值时,timeout时间和指数退避时间相同,即乘2的n次方
11 timeout = ((2 << boundary) - 1) * rto_base;
12 else
13 // 大于指数退避次数阈值时,timeout时间为指数退避后的最大时间 + TCP_RTO_MAX 乘多余的次数
14 timeout = ((2 << linear_backoff_thresh) - 1) * rto_base +
15 (boundary - linear_backoff_thresh) * TCP_RTO_MAX;
16 return jiffies_to_msecs(timeout);
17 }
重传次数的两个阈值,对应的是linux两个配置项
TCP_RETRIES1: 触发链路探测的重传次数阈值
TCP_RETRIES2: 判定重传失败的重传次数阈值

下面是一个实验数据,客户端/服务端都是用的本机 localhost(怀念研究生时期的实验环境,当年真的可以做很多有意思的事情),没有加额外的时延,最终15次的重传时间间隔就是下面的这张图。

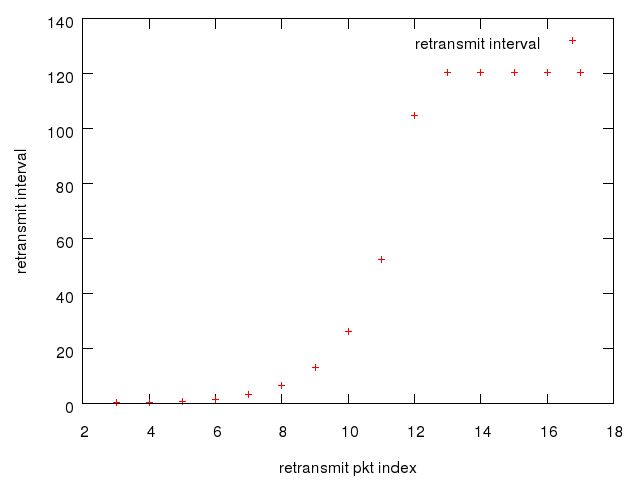
重传时间间隔从400 ms 开始指数式增长,达到最大值120s(默认最大RTO)时候不变,一直重传,直到重传次数达到 TCP_RETRIES2 ,然后客户端 socket 返回 ETIMEOUT错误,这个过程累积在15分钟左右。
情况四 双方都处于静默状态 - Tcp KeepAlive
如果恰巧A 进程没有任何要发往B的数据, A 进程就没有任何途径感知到进程B已经断开了连接了,这种状态也就是我们熟悉的Tcp半打开状态,也就是冷战状态,双方都不知道对方状态,也无探测报文去触发对方Rst或者Ack。这种情况下,就要有一方主动一点,抛出个橄榄枝,看看对方是要回个Rst拒绝你,还是要回个Ack接受你,还是啥也不回继续冷战,但至少通过这次探测,我们就可以知道对方的状态。这就是Tcp的KeepAlive 机制,Tcp KeepAlive 是协议栈里用来检测半打开状态的机制,在上面介绍的 tcp_init_xmit_timers 函数内,Tcp 启动了一个 keepAlive 定时器(默认时长是2个小时),2个小时后链路处于空闲状态,便会触发这个定时器,定时器的主要工作就是向对方发送探测报文。
1 static void tcp_keepalive_timer (struct timer_list *t)
2 {
3 struct sock *sk = from_timer(sk, t, sk_timer);
4 struct inet_connection_sock *icsk = inet_csk(sk);
5 struct tcp_sock *tp = tcp_sk(sk);
6 u32 elapsed;
7
8 /* Only process if socket is not in use. */
9 bh_lock_sock(sk);
10 if (sock_owned_by_user(sk)) {
11 /* Try again later. */
12 inet_csk_reset_keepalive_timer (sk, HZ/20);
13 goto out;
14 }
15
16 if (sk->sk_state == TCP_LISTEN) {
17 pr_err("Hmm... keepalive on a LISTEN ???\n");
18 goto out;
19 }
20
21 tcp_mstamp_refresh(tp);
22 if (sk->sk_state == TCP_FIN_WAIT2 && sock_flag(sk, SOCK_DEAD)) {
23 if (tp->linger2 >= 0) {
24 const int tmo = tcp_fin_time(sk) - TCP_TIMEWAIT_LEN;
25
26 if (tmo > 0) {
27 tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
28 goto out;
29 }
30 }
31 tcp_send_active_reset(sk, GFP_ATOMIC);
32 goto death;
33 }
34
35 if (!sock_flag(sk, SOCK_KEEPOPEN) ||
36 ((1 << sk->sk_state) & (TCPF_CLOSE | TCPF_SYN_SENT)))
37 goto out;
38
39 elapsed = keepalive_time_when(tp);
40
41 /* It is alive without keepalive 8) */
42 // 有发送中的数据,则不需要额外的探测报文
43 if (tp->packets_out || !tcp_write_queue_empty(sk))
44 goto resched;
45
46 elapsed = keepalive_time_elapsed(tp);
47
48 if (elapsed >= keepalive_time_when(tp)) {
49 /* If the TCP_USER_TIMEOUT option is enabled, use that
50 * to determine when to timeout instead.
51 */
52 // 关闭连接时间点, 1:空闲时间超过用户设置时间 2: 没有使用时间选项,探测数超过保活探测的最大次数
53 if ((icsk->icsk_user_timeout != 0 &&
54 elapsed >= msecs_to_jiffies(icsk->icsk_user_timeout) &&
55 icsk->icsk_probes_out > 0) ||
56 (icsk->icsk_user_timeout == 0 &&
57 icsk->icsk_probes_out >= keepalive_probes(tp))) { // 最大的系统配置探测次数
58 tcp_send_active_reset(sk, GFP_ATOMIC);
59 tcp_write_err(sk);
60 goto out;
61 }
62 // 发送探测报文
63 if (tcp_write_wakeup(sk, LINUX_MIB_TCPKEEPALIVE) <= 0) {
64 icsk->icsk_probes_out++;
65 // 系统配置 sysctl_tcp_keepalive_intvl,或者是Socket接口设置的探测时间间隔
66 elapsed = keepalive_intvl_when(tp);
67 } else {
68 /* If keepalive was lost due to local congestion,
69 * try harder.
70 */
71 elapsed = TCP_RESOURCE_PROBE_INTERVAL;
72 }
73 } else {
74 /* It is tp->rcv_tstamp + keepalive_time_when(tp) */
75 elapsed = keepalive_time_when(tp) - elapsed;
76 }
77
78 sk_mem_reclaim(sk);
79
80 resched:
81 inet_csk_reset_keepalive_timer (sk, elapsed);
82 goto out;
83
84 death:
85 tcp_done(sk);
86
87 out:
88 bh_unlock_sock(sk);
89 sock_put(sk);
90 }
Tcp KeepAlive 有三个主要的配置参数:
tcp_keepalive_time: Tcp KeepAlive定时器触发时间, 默认7200s
tcp_keepalive_intvl: 保活探测报文的重传时间,默认为75s。
tcp_keepalive_probes: 保活探测报文的发送次数,默认为9次。
工具链:如何在不杀进程的情况下,关闭掉某个Tcp连接
Q: 特定场景下,我们在明知到对方进程挂了,但是相关的Tcp连接没有关闭,如果我们要手动关闭这个连接该怎么处理?
A: 处理这个问题主要由两个思路:
1):根据Tcp协议原理,我们只需要向这个连接发送一个Rst报文,为此我们需要构造一个 Rst 报文,并丢给本机 socket,目前 tcpkill 等工具可以使用,但是这种方法需要知道 sock 当前的 seq 才能发送符合要求的 Rst 报文,否则会被协议栈丢弃。
参考: https://unix.stackexchange.com/questions/71940/killing-tcp-connection-in-linux
2):通过gdb attach进程,然后直接调用 close 系统调用,关闭对应的描述符 fd
参考: https://superuser.com/questions/127863/manually-closing-a-port-from-commandline/668155#668155
总结
网络传输过程中,如果对端只是进程 Crash 或者宕机后又迅速重启,客户端是能够较快感知到对端状态变化的,但是如果对端宕机后完全变成了丢包黑洞的话,依靠 TCP 协议栈本身发现网络连接断开可能耗时比较久,linux 默认情况下这个过程有可能需要15分钟左右,因此对这个时间不太满意的情况下,可以尝试通过修改 TCP_RETRIES2 参数来进行调优,当然时间太短也有一些隐患,比如它就是网卡了,简单几次重传就放弃连接似乎也不太合理,实现应用层的心跳机制根据业务需求配置似乎更合理些。
TCP 异常断开连接的过程的更多相关文章
- socket选项自带的TCP异常断开检测
TCP异常断开是指在突然断电,直接拔网线等等情况下,如果通信双方没有进行数据发送通信等处理的时候,无法获知连接已经断开的情况. 在通常的情况下,为了使得socket通信不受操作系统的限制,需要自己在应 ...
- linux 服务器与客户端异常断开连接问题
服务器与客户端连接,客户端异常断掉之后服务器端口仍然被占用, 到最后是不是服务器端达到最大连接数就没法连接了?领导让我测试这种情况,我用自己的电脑当TCP Client,虚拟机当服务器,连接之后能正常 ...
- PHP - 用户异常断开连接,脚本强制继续执行,异常退出回调
试想如下情况.如果你的用户正在执行一个需要非常长的执行时间的操作.他点了执行了之后,浏览器就开始蛋疼地转.如果执行5分钟,你猜他会干啥,显然会觉得什么狗屎垃圾站,这么久都不响应,然后就给关了.当然这个 ...
- 计算机网络:TCP协议建立连接的过程为什么是三次握手而不是两次?【对于网上的两种说法我的思考】
网上关于这个问题吵得很凶,但是仔细看过之后我更偏向认为两种说的是一样的. 首先我们来看看 TCP 协议的三次握手过程 如上图所示: 解释一下里面的英文: 里面起到作用的一些标志位就是TCP报文首部里的 ...
- tcp异常断开的重连解决方法
1.select超时重连 http://bbs.chinaunix.net/thread-4162149-1-1.html 2.http://bbs.csdn.net/topics/350074818 ...
- tcp断开连接,4次握手,为什么wireshark 只能抓到3个包?
用wireshark 抓包,看看tcp 断开连接的过程. 以前书上说tcp断开连接,4次握手,可我为什么wireshark 只能抓到3个包? 百度一下,别人也有类似的疑问. [求助]书上和网上的资料 ...
- TCP连接异常断开检测(转)
TCP是一种面向连接的协议,连接的建立和断开需要通过收发相应的分节来实现.某些时候,由于网络的故障或是一方主机的突然崩溃而另一方无法检测到,以致始终保持着不存在的连接.下面介绍一种方法来检测这种异常断 ...
- (转)TCP连接异常断开检测
TCP是一种面向连接的协议,连接的建立和断开需要通过收发相应的分节来实现.某些时候,由于网络的故障或是一方主机的突然崩溃而另一方无法检测到,以致始终保持着不存在的连接.下面介绍一种方法来检测这种异常断 ...
- TCP建立连接和断开连接过程
假设Client端发起中断连接请求,也就是发送FIN报文.Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着 ...
- TCP建立连接和断开连接图解
参考博客: http://blog.csdn.net/whuslei/article/details/6667471 http://www.2cto.com/net/201310/251896.htm ...
随机推荐
- drush .. drupal console
"You can run both." They compliment each other, yet the final decision is yours. Especiall ...
- mysql 修改字符集相关操作
修改某个表字段的字符集 ALTER TABLE apply_info MODIFY member_name varchar(128) CHARACTER SET utf8mb4; 查看某个库的字符集类 ...
- HDLbits——Shift18
// Build a 64-bit arithmetic shift register, // with synchronous load. The shifter can shift both le ...
- 大二下学期开学java测试
我们在2月13日下午进行了java测试(是一个新闻类型的题),通过这一个测试我进行了以下总结: 我对于javaweb的框架构建和加密密码,还有一些不同人物功能的实现,使得我在这次得考试中成绩不太理想. ...
- Python 字典类型
1.由于字典中的 key 是非常关键的数据,而且程序需要通过 key 来访问 value,因此字典中的 key 不允许重复.程序既可使用花括号语法来创建字典,也可使用 dict() 函数来创建字典.实 ...
- C#使用SharpZipLib解压多文件的zip压缩文件数据流,保存到本地
代码: public async Task<ReturnModel<List<string>>> UploadModel() { var task = new Ta ...
- Web Dynpro for ABAP(16):WDA Analysis Tools
3.21 Quality Assurance and Supportability WDA程序效能验证工具. Tests工具: eCATT and Web Dynpro ABAP Debugging工 ...
- VeeValidate 注册实例
注册 1 安装: npm install vee-validate --save 2.mian.js 填写 import Vue from 'vue' import VeeValidate, {Val ...
- MindManager离线安装包官网下载
软件官网:https://www.mindjet.com/ 注意:不建议在思杰马克丁及其相关合作网站下载该软件,更不建议在其旗下站点购买该软件授权. 目前来说,官网正常下载的话它会要求你填写一些信息, ...
- 044_Schedule Job 间隔时间自动执行
需求:系统上的标准功能是能够设置间隔一天的执行,或者是写完代码着急测试我们写个5分钟后执行的: 但是遇到要求没间隔一小时或者十分钟执行,该怎么处理呢? global class **_Retrieve ...