DBScan聚类,打破形状的限制,使用密度聚类
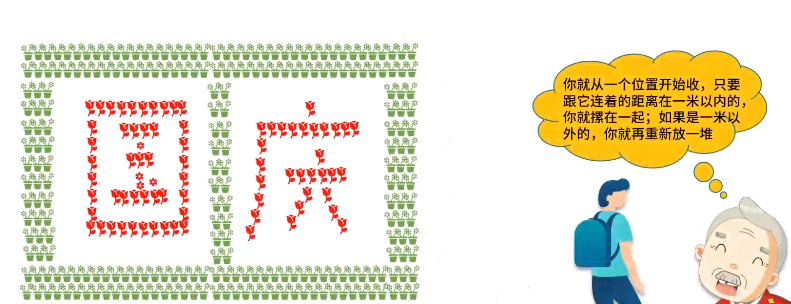
如何用花盆摆放成国庆字,并且包围这两个字。
在DBSCAN中衡量密度主要使用的指标:半径、最少样本量
算法原理
*直接密度可达
如果一个点在核心对象的半径区域内,那么这个点和核心对象称为直接密度可达,比如A和B,B和C等
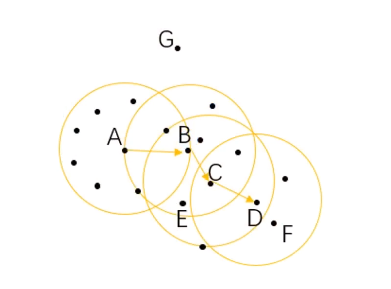
图1
*密度可达
如果有一系列点,都满足上一个点到这个点都是密度直达,那么这个系列中不相邻的点就称为密度可达,比如上图1中A和D。另外下图2也是有解释的
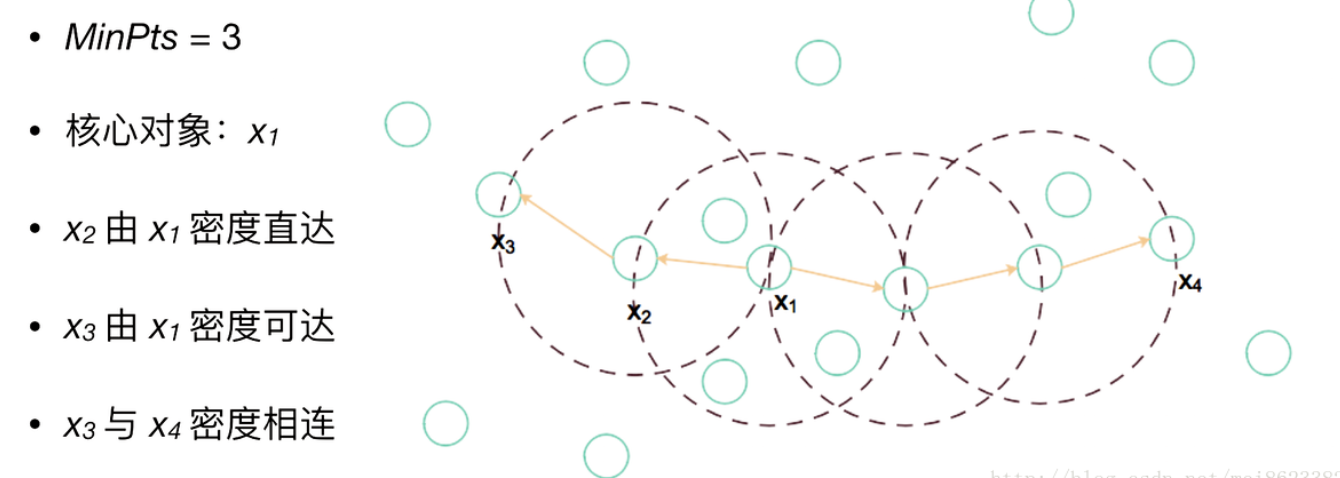
图2
*密度相连
如果通过一个核心对象出发,得到两个密度可达的点,那么这两个点称为密度相连,比如图1中E和F
经过初始化后,从整个样本集中去抽取样本点
如果这个样本点是核心对象,那么从这个点出发,找到所有密度可达的对象,构成一个簇
如果这个样本点不是核心对象,那么再重新找下一个点
算法优点
不需要划分个数(只需要计算)
可以处理噪点
可以处理任何形状的空间聚类问题
算法缺点
需要指定最小样本量和半径两个参数
数量大时开销也很大
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量比较差
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import dbscan #生成500个点,噪声为0.1
X,_=datasets.make_moons(500,noise=0.1,random_state=1) df=pd.DataFrame(X,columns=['x','y'])
df.plot.scatter('x','y',s=200,alpha=0.5,c="green",title='dataset by DBSCAN')
plt.show()

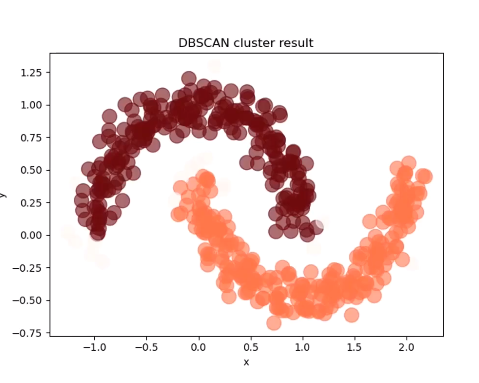
生成的绿色结果
#eps为邻域半径,min_samples为最少样本量
core_samples,cluster_ids=dbscan(X,eps=0.2,min_samples=20)
#cluster_ids中-1表示对应的点为噪声
df=pd.DtaFrame(np.c_[X,cluster_ids],columns=['x','y','cluster_id'])
df['cluster_id']=df['cluster_id'].astype('i2') #绘制结果图像
df.plot.scatter('x','y',s=200,
c=list(df['scatter_id']),cmap='Reds',colorbar=False,
alpha=0.6,title='DBSCAN cluster result')
plt.show()
DBScan聚类,打破形状的限制,使用密度聚类的更多相关文章
- 聚类——密度聚类DBSCAN
Clustering 聚类 密度聚类——DBSCAN 前面我们已经介绍了两种聚类算法:k-means和谱聚类.今天,我们来介绍一种基于密度的聚类算法——DBSCAN,它是最经典的密度聚类算法,是很多算 ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- DBSCAN密度聚类
1. 密度聚类概念 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密 ...
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 【转】DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
随机推荐
- Nacos极简教程
简介 Nacos是服务发现与注册,服务配置中心. Nacos 具有如下特性: 服务发现和服务健康监测:支持基于DNS和基于RPC的服务发现,支持对服务的实时的健康检查,阻止向不健康的主机或服务实例发送 ...
- tcp 中 FLAGS字段,几个标识:SYN, FIN, ACK, PSH, RST, URG.
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG. 其中,对于我们日常的分析有用的就是前面的五个字段.它们的含义是: 1.SYN表示建立 ...
- git每次操作都要输入账号密码 解决方案
1.执行命令: git config --global credential.helper store git pull 2.输入用户名密码,以后就不会再次要求用户名密码了
- onclick="func()"和 onclick = "return func()"区别
onclick="func()" 表示只会执行 func , 但是不会传回 func 中之回传值onclick = "return func()" 则是 执行 ...
- Static块和类加载顺序
原创:转载需注明原创地址 https://www.cnblogs.com/fanerwei222/p/11451040.html 版本:Java8 直接上代码: public class Stati ...
- swoole错误“Uncaught Error: Class 'swoole_server' not found”的解决办法
如果你在执行swoole对应文件时,报下面的错误, PHP Fatal error: Uncaught Error: Class 'swoole_server' not found in /mnt/w ...
- [LeetCode]20.有效的括号(Java)
原题地址: valid-parentheses 题目描述: 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效. 有效字符串需满足: 左括号必须用相同类 ...
- NeurIPS 2017 | QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
由于良好的可扩展性,随机梯度下降(SGD)的并行实现是最近研究的热点.实现并行化SGD的关键障碍就是节点间梯度更新时的高带宽开销.因此,研究者们提出了一些启发式的梯度压缩方法,使得节点间只传输压缩后的 ...
- Dubbo源码剖析二之注册中心
Dubbo基础二之架构及处理流程概述 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中架构中,无论是服务提供者还是服务消费者都离不开注册中心,可见注册中心之重要.Redis.Nacos. ...
- 探秘inter()方法
最近在阅读<深入理解Jav虚拟机>的运行时常量池章节,看到"java语言并不要求常量池一定只有编译器才能产生...运行期间也可以将新的常量放入常量池,这种特性被开发人员利用得比较 ...