如何找到Hive提交的SQL相对应的Yarn程序的applicationId
最近的工作是利用Hive做数据仓库的ETL转换,大致方式是将ETL转换逻辑写在一个hsql文件中,脚本当中都是简单的SQL语句,不包含判断、循环等存储过程中才有的写法,仅仅支持一些简单的变量替换,比如当前账期等。然后通过一个通用的shell脚本来执行hsql文件。该脚本是主要是调用了hive -f <hsql文件>来执行hsql文件中的SQL语句的,当然hive命令会通过--hivevar选项定义变量将当前账期等数值传进去供SQL使用。
简单说下环境信息,目前使用的大数据平台版本是HDP 3.1.0.0-78,Hive版本是3.1.0,而Tez版本是0.9.1。Hive 3.X系列的新特性主要包括:
1. 执行引擎不再支持mr,取而代之的是tez或者spark(在HDP平台默认是tez);
2. 不再支持胖客户端Hive CLI,被beeline取代(目前通过hive命令执行sql实际还是调用的beeline去连接hiveserver2服务);
3. 默认建表支持ACID语义;
4. 支持LLAP,即Live Long and Process,相当于内存计算,极大地优化了性能(该特性实际从Hive 2.X开始支持);
言归正传,回到本文的主题,比如Hive在运行过程中报错了,我们需要在Yarn上找到对应的application的日志以便定位问题,前提是需要知道Yarn程序对应的applicationId,但是beeline的输出信息中是没有applicationId的,那么如何找到Hive提交的SQL相对应的Yarn程序的applicationId呢?主要有以下几个步骤:
1. 我们通过shell脚本提交hsql文件时实际是通过beeline向hiveserver2服务提交hsql文件中的SQL语句,我们的shell脚本会将beeline的屏幕输出信息同时重定向到日志文件中,这个就是我们的第一个步骤的日志。我们找到这个日志文件,在其中搜索关键字"Completed executing command",可以得到queryId,其中每个SQL语句对应1个queryId,因为我们的hsql脚本中有4个SQL语句,所以搜索出来的信息如下:
INFO : Completed executing command(queryId=hive_20200502095437_1e9bf52d-e590-4519-a6e1-9e2e4ae91158); Time taken: 0.755 seconds
INFO : Completed executing command(queryId=hive_20200502095816_888a7dba-4403-439d-a3a7-f6cdc280c18a); Time taken: 52.929 seconds
INFO : Completed executing command(queryId=hive_20200502100121_5752f019-a6e2-463c-b413-a80bbe518a5c); Time taken: 52.66 seconds
INFO : Completed executing command(queryId=hive_20200502100428_9d4b8955-b84c-40be-a605-9ce19b4b7773); Time taken: 26.463 seconds
2. 找到对应的hiveserver2服务在哪台机器上。由于beeline是通过zookeeper随机连接一个hiveserver2服务,所以从上一步的日志中可以看到连接的是哪台机器上的hiveserver2服务。然后登录到该台主机,通过netstat和ps命令找到对应的hiveserver2进程,从ps命令输出的进程信息对应的命令行中,我们可以找到下面的参数。
-Dhive.log.dir=/var/log/hive -Dhive.log.file=hiveserver2.log
上面的参数说明了hiveserver2服务对应的日志名称和路径。这样我们就可以找到hiveserver2服务对应的日志,这是我们第二个步骤的日志。从这个日志里通过搜索关键字"callerId=<queryId>",<queryId>用上一步得到的真实的queryId替换(比如搜索"callerId=hive_20200502095816_888a7dba-4403-439d-a3a7-f6cdc280c18a")。我们将上面的4个queryId逐一用前述的关键字搜索,得到信息如下:
2020-05-02T10:00:30,440 INFO [Thread-536694]: client.TezClient (:()) - Submitting dag to TezSession, sessionName=HIVE-315802e2-f6e4-499d-a707-4d3057180abd, applicationId=application_1588062934554_53656, dagName=create temporary table ngdwt.rpt_to_etc_...t (Stage-1), callerContext={ context=HIVE, callerType=HIVE_QUERY_ID, callerId=hive_20200502095816_888a7dba-4403-439d-a3a7-f6cdc280c18a }
2020-05-02T10:00:57,229 INFO [Thread-536729]: client.TezClient (:()) - Submitting dag to TezSession, sessionName=HIVE-315802e2-f6e4-499d-a707-4d3057180abd, applicationId=application_1588062934554_53656, dagName=create temporary table ngdwt.rpt_to_etc_...t (Stage-4), callerContext={ context=HIVE, callerType=HIVE_QUERY_ID, callerId=hive_20200502095816_888a7dba-4403-439d-a3a7-f6cdc280c18a }
2020-05-02T10:03:22,043 INFO [Thread-537002]: client.TezClient (:()) - Submitting dag to TezSession, sessionName=HIVE-315802e2-f6e4-499d-a707-4d3057180abd, applicationId=application_1588062934554_53656, dagName=create temporary tabl...ov_in,a.statis_date (Stage-1), callerContext={ context=HIVE, callerType=HIVE_QUERY_ID, callerId=hive_20200502100121_5752f019-a6e2-463c-b413-a80bbe518a5c }
2020-05-02T10:07:39,627 INFO [Thread-537495]: client.TezClient (:()) - Submitting dag to TezSession, sessionName=HIVE-315802e2-f6e4-499d-a707-4d3057180abd, applicationId=application_1588062934554_53656, dagName=insert into ngdwt.rpt_to_etc_rece_d(re...t (Stage-1), callerContext={ context=HIVE, callerType=HIVE_QUERY_ID, callerId=hive_20200502100428_9d4b8955-b84c-40be-a605-9ce19b4b7773 }
可以看到第1个queryId用关键字"callerId=<queryId>"去搜索没有搜到信息,因为对应的第一个sql语句是ddl语句,不会向yarn提交程序(但是仅用"<queryId>"去搜索还是能搜到信息),后面第二个queryId搜索出来有2行,其他queryId只有1行。
可以看到这些queryId(hive命令输出信息)或者callerId(hiveserver2.log日志信息)对应的hive session和yarn application是同一个:
sessionName=HIVE-315802e2-f6e4-499d-a707-4d3057180abd
applicationId=application_1588062934554_53656
也就是说,同一个hsql文件中的不同SQL语句对应的是同一个hive session以及同一个yarn application.
来看下yarn web管理页面中该application的截图。
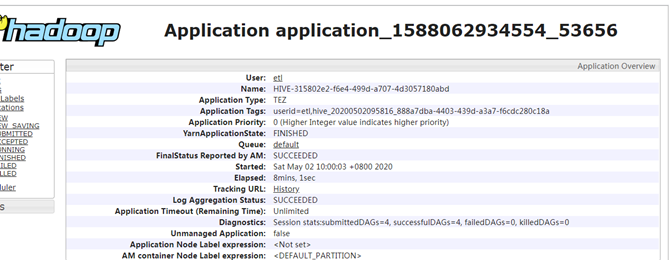
可以看到上面页面中的Name跟hiveserver2.log中的sessionName一致,Application Tags跟hiveserver2.log中的callerId(或者hive命令屏幕输出信息中的queryId)一致。
而yarn ui2中的程序信息如下:

3. 找到了applicationId就比较好办了,可以通过下面的命令将yarn日志从hdfs下载到本地(待yarn程序执行完毕)
yarn logs -applicationId application_1588062934554_53656 > application_1588062934554_53656.log
然后可以对application_1588062934554_53656.log做进一步的分析。
比如用关键字"Container: container_"搜索并去重排序后得到9个container的信息:
Container: container_e46_1588062934554_53656_01_000001 on hadoop19_45454_1588385301489
Container: container_e46_1588062934554_53656_01_000002 on hadoop31_45454_1588385300882
Container: container_e46_1588062934554_53656_01_000003 on hadoop40_45454_1588385301059
Container: container_e46_1588062934554_53656_01_000004 on hadoop27_45454_1588385300739
Container: container_e46_1588062934554_53656_01_000006 on hadoop36_45454_1588385301268
Container: container_e46_1588062934554_53656_01_000007 on hadoop57_45454_1588385301076
Container: container_e46_1588062934554_53656_01_000008 on hadoop22_45454_1588385301501
Container: container_e46_1588062934554_53656_01_000009 on hadoop31_45454_1588385300882
Container: container_e46_1588062934554_53656_01_000010 on hadoop21_45454_1588385301473
上面是该application对用的所有container.
或者用关键字"Assigning container to task:"搜索得到任务分配信息,其中container_e46_1588062934554_53656_01_000001因为是applicationmaster没有任务分配信息,其他8个container都有任务分配信息,其中container_e46_1588062934554_53656_01_000008和container_e46_1588062934554_53656_01_000009有2条记录,但attempt不同,表示这2个container里的任务之前有失败的,分别进行了2次尝试。为了简洁起见,这里仅列出搜索出来的第一条记录:
2020-05-01 22:00:40,603 [INFO] [DelayedContainerManager] |rm.YarnTaskSchedulerService|: Assigning container to task: containerId=container_e46_1588062934554_53656_01_000002, task=attempt_1588062934554_53656_1_00_000000_0, containerHost=hadoop31:45454, containerPriority= 11, containerResources=<memory:12288, vCores:1>, localityMatchType=RackLocal, matchedLocation=/default-rack, honorLocalityFlags=false, reusedContainer=false, delayedContainers=3
因为现在的Hive的执行引擎不再是mr,而是改成了tez,目前我对tez并不太熟悉,只是理解它为mr的升级版,在原来的map/reduce操作上增加了DAG,不同job之间的数据传递不必写到HDFS,而是类似数据流的方式,减少了中间环节,提升了效率。对于一个Tez程序,类似于MR程序的MRAppMaster和YarnChild进程,它会产生DAGAppMaster和TezChild进程,前者是master负责管理整个程序以及申请资源,后者是slave,负责执行具体的计算任务。
如何找到Hive提交的SQL相对应的Yarn程序的applicationId的更多相关文章
- 不care工具,在大数据平台中Hive能自动处理SQL
摘要:有没有更简单的办法,可以直接将SQL运行在大数据平台? 本文分享自华为云社区<Hive执行原理>,作者: JavaEdge . MapReduce简化了大数据编程的难度,使得大数据计 ...
- hive -- 协同过滤sql语句
hive -- 协同过滤sql语句 数据: *.3g.qq.com|腾讯应用宝|应用商店 *.91rb.com|91手机助手|应用商店 *.app.qq.com|腾讯应用宝|应用商店 *.haina. ...
- 事务控制语句,begin,rollback,savepoint,隐式提交的SQL语句
事务控制语句 在MySQL命令行的默认设置下,事务都是自动提交的,即执行SQL语句后就会马上执行COMMIT操作.因此开始一个事务,必须使用BEGIN.START TRANSACTION,或者执行SE ...
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
- Mysql 提交Big sql的过程
此处的big sql指的是单条sql的size 超过innodb_log_file_size,通过构造这样的测试,来分析mysql的提交过程. 做这个分析的起因是我不是很明白,既然mysql需要将被执 ...
- SQL相关子查询是什么?和嵌套子查询有什么区别?
目录 两者的各种叫法 相关子查询MySQL解释 相关子查询Wikipedia解释 相关子查询执行步骤拆解 相关子查询和嵌套查询的区别 参考资料 两者的各种叫法 相关子查询叫做:Correlated S ...
- LINQ To SQL在N层应用程序中的CUD操作、批量删除、批量更新
原文:LINQ To SQL在N层应用程序中的CUD操作.批量删除.批量更新 0. 说明 Linq to Sql,以下简称L2S. 以下文中所指的两层和三层结构,分别如下图所示: 准确的说,这里 ...
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
随机推荐
- matplotlib PyQt5 nivigationBar 中pan和zoom功能的探索
为matplotlib生成的图添加编辑条,我们导入NavigationToolbar2QT from matplotlib.backends.backend_qt5agg import Navigat ...
- 条件变量 condition_variable wait_until
wait_until(阻塞当前线程,直到条件变量被唤醒,或直到抵达指定时间点) #include <iostream> #include <atomic> #include & ...
- 想进大厂嘛?这里有一份通关秘籍:iOS大厂面试宝典
1.NSArray与NSSet的区别? NSArray内存中存储地址连续,而NSSet不连续 NSSet效率高,内部使用hash查找:NSArray查找需要遍历 NSSet通过anyObject访问元 ...
- AJ学IOS(03)UI之纯代码实现UI——图片查看器
AJ分享,必须精品 先看效果 主要实现类似看新闻的一个界面,不用拖拽,纯代码手工写. 首先分析app可以很容易知道他这里有两个UILabel一个UIImageView还有两个UIButton 定义UI ...
- Css3 新增的属性以及使用
Css3基础操作 . Css3? css3事css的最新版本 width. heith.background.border**都是属于css2.1CSS3会保留之前 CSS2.1的内容,只是添加了一些 ...
- [一起读源码]走进C#并发队列ConcurrentQueue的内部世界 — .NET Core篇
在上一篇<走进C#并发队列ConcurrentQueue的内部世界>中解析了Framework下的ConcurrentQueue实现原理,经过抛砖引玉,得到了一众大佬的指点,找到了.NET ...
- CTE(With As)
WITH tabdate(dt) AS ( FROM dual UNION ALL FROM tabdate WHERE dt ) SELECT * FROM TabDate ; 一.With Tab ...
- stand up meeting 12/3/2015
part 组员 今日工作 工作耗时/h 明日计划 工作耗时/h UI 冯晓云 初始化弹窗的弹出位置并捕捉弹窗区域内的鼠标控制事件,初步解决弹窗的拖拽功能: 6 UWP对控件的支持各种看不懂,属性 ...
- C语言 贪吃蛇
贪吃蛇(单人版): 本人先来介绍一个函数 -- bioskey函数: int bioskey (int cmd) 参数 (cmd) 基本功能 0 返回下一个从键盘键入的值(若不键入任何值,则将等下一个 ...
- PHP xml 外部实体注入漏洞学习
XML与xxe注入基础知识 1.XMl定义 XML由3个部分构成,它们分别是:文档类型定义(Document Type Definition,DTD),即XML的布局语言:可扩展的样式语言(Exten ...