开始 Keras 序列模型(Sequential model)
开始 Keras 序列模型(Sequential model)
序列模型是一个线性的层次堆栈。
你可以通过传递一系列 layer 实例给构造器来创建一个序列模型。
The Sequential model is a linear stack of layers.
You can create a Sequential model by passing a list of layer instances to the constructor:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])也可以简单的添加 layer 通过 .add() 函数。
You can also simply add layers via the .add() method:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))Specifying the input shape
The model needs to know what input shape it should expect. For this reason, the first layer in a Sequential model (and only the first, because following layers can do automatic shape inference) needs to receive information about its input shape. There are several possible ways to do this:
- Pass an
input_shapeargument to the first layer. This is a shape tuple (a tuple of integers orNoneentries, whereNoneindicates that any positive integer may be expected). Ininput_shape, the batch dimension is not included. - Some 2D layers, such as
Dense, support the specification of their input shape via the argumentinput_dim, and some 3D temporal layers support the argumentsinput_dimandinput_length. - If you ever need to specify a fixed batch size for your inputs (this is useful for stateful recurrent networks), you can pass a
batch_sizeargument to a layer. If you pass bothbatch_size=32andinput_shape=(6, 8)to a layer, it will then expect every batch of inputs to have the batch shape(32, 6, 8).
As such, the following snippets are strictly equivalent:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))model = Sequential()
model.add(Dense(32, input_dim=784))Compilation
Before training a model, you need to configure the learning process, which is done via the compile method. It receives three arguments:
- An optimizer. This could be the string identifier of an existing optimizer (such as
rmsproporadagrad), or an instance of theOptimizerclass. See: optimizers. - A loss function. This is the objective that the model will try to minimize. It can be the string identifier of an existing loss function (such as
categorical_crossentropyormse), or it can be an objective function. See: losses. - A list of metrics. For any classification problem you will want to set this to
metrics=['accuracy']. A metric could be the string identifier of an existing metric or a custom metric function.
# For a multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# For a binary classification problem
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# For a mean squared error regression problem
model.compile(optimizer='rmsprop',
loss='mse')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])Training
Keras models are trained on Numpy arrays of input data and labels. For training a model, you will typically use the fit function. Read its documentation here.
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)# For a single-input model with 10 classes (categorical classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=10, batch_size=32)Examples
Here are a few examples to get you started!
In the examples folder, you will also find example models for real datasets:
- CIFAR10 small images classification: Convolutional Neural Network (CNN) with realtime data augmentation
- IMDB movie review sentiment classification: LSTM over sequences of words
- Reuters newswires topic classification: Multilayer Perceptron (MLP)
- MNIST handwritten digits classification: MLP & CNN
- Character-level text generation with LSTM
…and more.
Multilayer Perceptron (MLP) for multi-class softmax classification:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# Generate dummy data
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) is a fully-connected layer with 64 hidden units.
# in the first layer, you must specify the expected input data shape:
# here, 20-dimensional vectors.
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)MLP for binary classification:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)VGG-like convnet:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)Sequence classification with LSTM:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)Sequence classification with 1D convolutions:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)Stacked LSTM for sequence classification
In this model, we stack 3 LSTM layers on top of each other,
making the model capable of learning higher-level temporal representations.
The first two LSTMs return their full output sequences, but the last one only returns
the last step in its output sequence, thus dropping the temporal dimension
(i.e. converting the input sequence into a single vector).
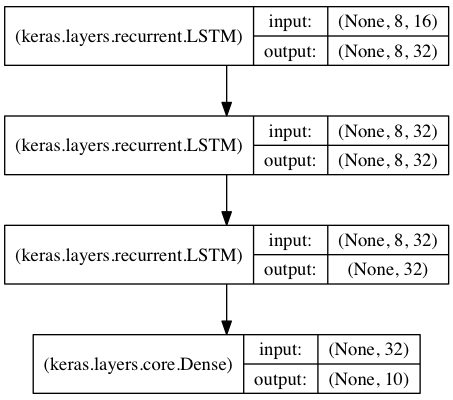
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# expected input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
model.add(LSTM(32)) # return a single vector of dimension 32
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Generate dummy validation data
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))Same stacked LSTM model, rendered “stateful”
A stateful recurrent model is one for which the internal states (memories) obtained after processing a batch
of samples are reused as initial states for the samples of the next batch. This allows to process longer sequences
while keeping computational complexity manageable.
You can read more about stateful RNNs in the FAQ.
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# Expected input batch shape: (batch_size, timesteps, data_dim)
# Note that we have to provide the full batch_input_shape since the network is stateful.
# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# Generate dummy validation data
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))开始 Keras 序列模型(Sequential model)的更多相关文章
- Keras序列模型学习
转自:https://keras.io/zh/getting-started/sequential-model-guide/ 1.顺序模型是多个网络层的线性堆叠. 你可以通过将网络层实例的列表传递给 ...
- 【Keras学习】Sequential模型
序贯(Sequential)模型 序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”. 可以通过向Sequential模型传递一个layer的list来构造该模型: from keras.mode ...
- Keras 时序模型
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Thinking_boy1992/article/details/53207177 本文翻译自 时序模 ...
- keras 保存模型
转自:https://blog.csdn.net/u010159842/article/details/54407745,感谢分享! 我们不推荐使用pickle或cPickle来保存Keras模型 你 ...
- keras 入门模型训练
# -*- coding: utf-8 -*- from keras.models import Sequential from keras.layers import Dense from kera ...
- Keras保存模型并载入模型继续训练
我们以MNIST手写数字识别为例 import numpy as np from keras.datasets import mnist from keras.utils import np_util ...
- keras模块学习之model层【重点学习】
本笔记由博客园-圆柱模板 博主整理笔记发布,转载需注明,谢谢合作! model层是keras模块最重要的一个层,所以单独做下笔记,这块比较难理解,本博主自己还在学习这块,还在迷糊中. model的方法 ...
- keras 保存模型和加载模型
import numpy as npnp.random.seed(1337) # for reproducibility from keras.models import Sequentialfrom ...
- Deep Learning.ai学习笔记_第五门课_序列模型
目录 第一周 循环序列模型 第二周 自然语言处理与词嵌入 第三周 序列模型和注意力机制 第一周 循环序列模型 在进行语音识别时,给定一个输入音频片段X,并要求输出对应的文字记录Y,这个例子中输入和输出 ...
随机推荐
- python爬虫所遇问题列举
1.通过python socket库来构造请求报文,向服务器发送图片请求时 (1)图片在浏览器请求头中的remote address信息跟通过python socket输出远程连接地址和端口号不一致 ...
- jvm GC算法和种类
1.GC 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟 ...
- ASP.NET Core中的Http缓存
ASP.NET Core中的Http缓存 Http响应缓存可减少客户端或代理对web服务器发出的请求数.响应缓存还减少了web服务器生成响应所需的工作量.响应缓存由Http请求中的header控制. ...
- webpack进阶(三)
1)CommonsChunkPlugin已经从webpack4移除,所以在用webpack进行公共模块的拆分时,会报错 Cannot read property 'CommonsChunkPlugin ...
- nes 红白机模拟器 第8篇 USB 手柄支持
买了一个支持 USB OTG, 蓝牙 连接的 安卓手柄. 接到 ubunto 上 dmesg 可以看到识别出来的信息,内核已经支持了. usb - using uhci_hcd usb - usb - ...
- Oracle 11g rac中关于crsctl stop cluster/crs/has的区别
转载至http://www.oracleplus.net/arch/1203.html,整理后得. 1 通过命令查看cluster/has/crs管理的内容 [root@11rac1 ~]# crsc ...
- 如何优雅的使用AbpSettings
在Abp中配置虽然使用方便,但是每个配置要先定义key,要去provider中定义,再最后使用key从ISetting中获取还是挺麻烦的一件事, 最主要是获取修改的时候,比如,修改用户配置,是从获取一 ...
- HTML5&CCS3(3)基本HTML结构
3.1 开始编写网页 每个HTML文档都应该包含以下基本成分: DOCTYPE: html元素(包含lang属性.该属性不是必需的,但推荐加上): head元素: 说明字符编码的meta元素: tit ...
- python基础(初识)
Python简介 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解 ...
- 人见人爱A-B 题解
参加过上个月月赛的同学一定还记得其中的一个最简单的题目,就是{A}+{B},那个题目求的是两个集合的并集,今天我们这个A-B求的是两个集合的差,就是做集合的减法运算.(当然,大家都知道集合的定义,就是 ...