详解 Set接口
(请关注 本人“集合”总集篇博文——《详解 Collection接口》)
在Collection接口的子接口中,最重要的,也是最常见的两个—— List接口 和 Set接口。
那么,为什么有了 List接口这么方便的接口,还要讲解Set接口呢?
在本人博文——《详解 List接口》中就讲过:
List接口中可以存储相同的元素,在特定情况下,我们要进行处理的数据不能存在相同项(举个十分常见的例子:我国人民的身份证号),那么,我们就不能再用List进行存储了,为了防止重复数据的录入。
所以,就有了本人这篇博文的主题——Set接口
那么,话不多说了,开始我们这篇博文的讲解吧:
Set接口:
定义:
一个不包含重复元素的 collection。即 最多包含一个 null 元素。
(对其所包含的元素有所限制,例如:不允许存储null)
方法:
- boolean add(E e)
如果 set 中尚未存在指定的元素,则添加此元素(可选操作)。- boolean addAll(Collection<? extends E> c)
如果 set 中没有指定 collection 中的所有元素,则将其添加到此 set 中(可选操作)。- void clear()
移除此 set 中的所有元素(可选操作)。- boolean contains(Object o)
如果 set 包含指定的元素,则返回 true。- boolean containsAll(Collection<?> c)
如果此 set 包含指定 collection 的所有元素,则返回 true。- boolean equals(Object o)
比较指定对象与此 set 的相等性。- int hashCode()
返回 set 的哈希码值。- boolean isEmpty()
如果 set 不包含元素,则返回 true。- Iterator iterator()
返回在此 set 中的元素上进行迭代的迭代器。- boolean remove(Object o)
如果 set 中存在指定的元素,则将其移除(可选操作)。- boolean removeAll(Collection<?> c)
移除 set 中那些包含在指定 collection 中的元素(可选操作)。- boolean retainAll(Collection<?> c)
仅保留 set 中那些包含在指定 collection 中的元素(可选操作)。- int size()
返回 set 中的元素数(其容量)。- Object[] toArray()
返回一个包含 set 中所有元素的数组。- < T > T[] toArray(T[] a)
返回一个包含此 set 中所有元素的数组;
返回数组的运行时类型是指定数组的类型
我们可以看到,Set接口 与 本人上一篇博文中讲解的 List接口的方法是大致相同的。
同样的,Set接口也有三个很常用的实现类——HashSet、LinkedHashSet 和 TreeSet。
那么,现在本人来对这三个类进行一下讲解吧:
HashSet:
特点:
- HashSet 底层数据结构是哈希表.
- HashSet 是 线程不安全的 (即: 效率高的)
- 集合元素可以是 null
- 元素(由底层数据结构决定):
无序(存储顺序不一致),
且唯一(存储的元素不重复)
在这里,可能会有同学有疑问了——哈希表是什么呢?
那么,本人在这里稍作解释:
哈希表(HashMap):
- 是一个元素为链表的数组(JDK1.7之前)
数组 + 链表 + 红黑树 的结构 (JDK1.8 之后)- 综合了数组和链表的优点
(至于“哈希”, 也就是“散列”的数据结构
在本篇博文中,本人不对这个算法进行讲解,仅讲解用了这个算法后
如需详解,请关注本人之后的博文——《HashMap 源码解析》)
但是,本人要强调的一点是:
我们用HashSet去存储新数据时,是按照如下步骤的:
- 调用该对象的hashCode() 方法来得到该对象的 hashCode 值
- 根据 hashCode 值决定该对象在 HashSet 中的存储位置
- 若存在 hashCode 值相等 且 在该 HashSet中已经存在的 元素时,
- 调用 这两个对象的 equals() 方法:
若equals()的返回值 相等,则判定这两个元素相等,不再录入新数据;
若equals()的返回值 不想等,则在 旧元素位置所在数组的位置 下 链接新元素(当链接的元素足够时,还要用到红黑树的数据结构)
现在,本人来通过一个例子来证明下上面的说法:
首先是只存储了 姓名 和 年龄 的People类:
package aboutSet;
public class People {
private String name;
private int age;
public People() {
}
public People(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "People{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
return true;
}
@Override
public int hashCode() {
return 0;
}
}
本人刻意让hashCode()和equals() 返回一个定值,
按照上面的说法,我们在测试类中所建立的HashSet容器,只能录入第一个人的信息。
那么,现在本人来给出一个测试类,来验证下上面的说法是否正确:
package aboutSet;
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
People s1 = new People("张无忌", 19);
People s2 = new People("王祖贤", 23);
People s3 = new People("张学友", 20);
People s4 = new People("周润发", 20);
HashSet<People> Peoples = new HashSet<>();
Peoples.add(s1);
Peoples.add(s2);
Peoples.add(s3);
Peoples.add(s4);
for (People people : Peoples) {
System.out.println(people);
}
}
}
那么,现在本人来展示下运行结果:
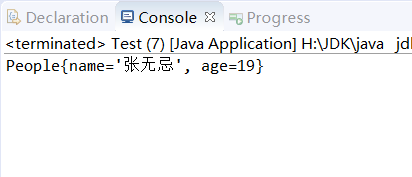
可以清晰地看到,本人的说法毫无问题!
现在,本人将hashCode()和equals() 方法恰当地重写:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
People student = (People) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
并将测试类中给HashSet录入数据的代码改为如下:
People s1 = new People("张无忌", 19);
People s2 = new People("王祖贤", 23);
People s3 = new People("张无忌", 23);
People s4 = new People("张学友", 20);
People s5 = new People("张无忌", 20);
HashSet<People> Peoples = new HashSet<>();
Peoples.add(s1);
Peoples.add(s2);
Peoples.add(s3);
Peoples.add(s4);
Peoples.add(s5);
现在,我们再来看一下运行结果:

我们可以看到,由于我们重写了hashCode()和equals()方法,导致两者的返回值,
除了第一个和第五个意外,都不一样。
所以最终的输出结果只有四条,且都不一样,这就说明了:
HashSet存储数据的判断标准,由hashCode()和equals()这两个方法决定
那么,现在,本人再来给出一个例子:
package aboutSet;
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
Integer s1 = new Integer(19);
Integer s2 = new Integer(23);
Integer s3 = new Integer(3);
Integer s4 = new Integer(0);
Integer s5 = new Integer(19);
HashSet<Integer> Integers = new HashSet<>();
Integers.add(s1);
Integers.add(s2);
Integers.add(s3);
Integers.add(s4);
Integers.add(s5);
for (Integer Integer : Integers) {
System.out.println(Integer);
}
}
}
可以看到,本人并没有重写hashCode()和equals()方法,而且我们的Integer 类型的五个对象,全都是通过new得到的,但是,让我们来看看输出结果:
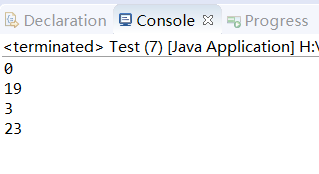
可以看到,地址值不同的 Integer类型的五个对象,有一个却因为值相同,没有被录入
这又是为什么呢?难道本人上面的说法错了吗?
答曰:非也!这是因为:有些工具类(包括Integer类型在内),都重写了hashCode()和equals()方法,不需要我们去重写。
那么,在看完上面的结论和例子之后,本人再来提出一条结论:
我们重写hashCode()方法,是为了减少“哈希碰撞次数”(相关知识点将在本人《HashMap 源码解析》博文中进行讲解),在这里我们可以认为是 调用equals()方法的次数
那么,有关HashSet的基本知识点就讲解完毕了,下面本人来对本篇博文的第二个知识点——LinkedHashSet做一下简介:
LinkedHashSet:
特点:
- LinkedHashSet底层数据结构是 链表 和 哈希表.
- LinkedHashSet 是 线程不安全的 (即: 效率高的)
- 集合元素可以是 null
- 元素(由底层数据结构决定):
有序(链表结构保证),
且唯一(哈希表结构保证)
至于这个类,本人觉得没什么好多说的,除了有序外,其他特征几乎和HashSet一模一样。
现在,本人还是给出一个例子,来验证下上面的说法:
本人现在对上面的代码中的测试类修改如下:
package aboutSet;
import java.util.LinkedHashSet;
public class Test {
public static void main(String[] args) {
Integer s1 = new Integer(19);
Integer s2 = new Integer(23);
Integer s3 = new Integer(3);
Integer s4 = new Integer(0);
Integer s5 = new Integer(19);
LinkedHashSet<Integer> Integers = new LinkedHashSet();
Integers.add(s1);
Integers.add(s2);
Integers.add(s3);
Integers.add(s4);
Integers.add(s5);
for (Integer Integer : Integers) {
System.out.println(Integer);
}
}
}
那么,现在我们来看一下运行结果:
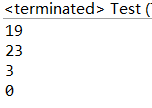
可以看到,上面的讲解没有问题。
那么,就开始这篇博文的最后一个知识点——TreeSet吧:
TreeSet:
特点:
- 元素唯一(二叉树存储结构 及 compareTo()方法 保证)
- 并且可以对元素进行排序 :
- 自然排序
- 使用比较器排序
那么,现在,本人就来对这两种排序方法进行一下讲解:
首先是自然排序:
自然排序:
条件:
- 表示这个元素的类 必须实现Comparable接口 (否则无法进行自然排序)
- 重写Comparable接口 中的compareTo()方法,根据此方法返回的正、负、0来决定元素的排列顺序:
若返回0:则不再录入新的元素;
若返回-1:则将新的元素放在正在比较的元素的左边;
若返回1:则将新的元素放在正在比较的元素的右边- TreeSet对象采用空参构造
举个例子:
现给出如下几个数:
20、18、23、22、17、24、19、18、24
那么, 排列顺序就由下图所示:

而当我们读取的时候,会按照本人在《数据结构与算法》专栏中的《二叉树的遍历 详解及实现》所讲的中根序(又称“中序”)一样。
最终的输出结果会是:17、18、19、20、22、23、24
那么,本人还是先对前一篇博文的测试类做下改动,来验证一下上面的预测:
package aboutSet;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
Integer s1 = new Integer(20);
Integer s2 = new Integer(18);
Integer s3 = new Integer(23);
Integer s4 = new Integer(22);
Integer s5 = new Integer(17);
Integer s6 = new Integer(24);
Integer s7 = new Integer(19);
Integer s8 = new Integer(18);
Integer s9 = new Integer(24);
TreeSet<Integer> Integers = new TreeSet();
Integers.add(s1);
Integers.add(s2);
Integers.add(s3);
Integers.add(s4);
Integers.add(s5);
Integers.add(s6);
Integers.add(s7);
Integers.add(s8);
Integers.add(s9);
for (Integer Integer : Integers) {
System.out.println(Integer);
}
}
}
那么,让我们来看一下运行结果吧:

可以看到,本人的预测十分准确!
那么,可能就有同学有疑问了:
为什么没有达到那两个条件就可以自然排序呢?
答曰:没错!Integer这个类内部实现了Comparable接口,并且重写了compareTo()方法。
本人现在来展示一下Integer的相关源码:


由此可见,本人的讲解没有错误!
那么,现在本人来展示下自己该如何使用自然排序:
首先本人给出一个TreeSet所存的元素的类:
package aboutSet;
import java.util.Objects;
public class People implements Comparable<People>{
private String name;
private int age;
public People() {
}
public People(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(People people) {
//假设根据学生的年龄大小来排序
int num = this.age - people.age;
//但是年龄一样并不严谨,我们还要根据姓名来比较
int num2 = num==0 ? this.name.compareTo(people.name) : num;
return num2;
}
}
现在,本人给出一个测试类:
package aboutSet;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<People> treeSet = new TreeSet<>();
treeSet.add(new People("张星彩", 23));
treeSet.add(new People("关银屏", 23));
treeSet.add(new People("王富贵", 23));
treeSet.add(new People("姬无力", 20));
treeSet.add(new People("奥瑞利安索尔", 30));
treeSet.add(new People("jo太郎", 23));
for (People People : treeSet) {
System.out.println(People);
}
}
}
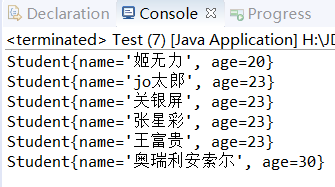
可以看到,一切如本人在代码中的解释所料!
那么,接下来,本人来展示下 使用比较器排序:
使用比较器排序:
条件:
- 采用有参构造,且在创建TreeSet对象时,需要通过参数传入一个Comparetor 比较器
现在,本人来展示下如何 使用比较器排序:
第一种手段——构造一个比较器类:
首先是存储元素信息的类:
package aboutSet;
import java.util.Objects;
public class People {
private String name;
private int age;
public People() {
}
public People(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
那么,现在本人来给出一个"按照元素姓名长度进行比较"比较器:
package aboutSet;
import java.util.Comparator;
public class TestComparator implements Comparator<People>{
public TestComparator() {
}
@Override
public int compare(People people1, People people2) {
//按照年龄大小排序
int num = people1.getAge() - people2.getAge();
int num2=num==0?people1.getName().compareTo(people2.getName()):num;
return num2;
}
}
现在,本人来给出一个测试类:
package aboutSet;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<People> treeSet = new TreeSet<>(new TestComparator());
treeSet.add(new People("张星彩", 23));
treeSet.add(new People("关凤", 23));
treeSet.add(new People("王权富贵", 23));
treeSet.add(new People("姬无力", 20));
treeSet.add(new People("奥瑞利安索尔", 30));
treeSet.add(new People("空条jo太郎", 23));
for (People People : treeSet) {
System.out.println(People);
}
}
}
那么,让我们来看一下运行结果:

第二种手段——通过 匿名内部类 传递:
People类不做改变,本人仅改变测试类:
package aboutSet;
import java.util.Comparator;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<People> treeSet = new TreeSet<>(new Comparator<People>() {
@Override
public int compare(People people1, People people2) {
//按照年龄大小排序
int num = people1.getAge() - people2.getAge();
int num2=num==0?people1.getName().compareTo(people2.getName()):num;
return num2;
}
});
treeSet.add(new People("张星彩", 23));
treeSet.add(new People("关凤", 23));
treeSet.add(new People("王权富贵", 23));
treeSet.add(new People("姬无力", 20));
treeSet.add(new People("奥瑞利安索尔", 30));
treeSet.add(new People("空条jo太郎", 23));
for (People People : treeSet) {
System.out.println(People);
}
}
}
让我们来看一下运行结果:

可以看到,结果依旧正确。
在这里,本人来对这两种 比较器排序 的应用场景来做一下说明:
一般地:
若是 只用一次该比较器,则使用匿名内部类传递
若是 反复多次使用该比较器,则通过一个比较器类传递
(Collection链接:https:////www.cnblogs.com/codderYouzg/p/12416566.html)
(集合总集篇链接:https://www.cnblogs.com/codderYouzg/p/12416560.html)
详解 Set接口的更多相关文章
- 详解EBS接口开发之库存事务处理采购接收--补充
除了可以用 详解EBS接口开发之库存事务处理采购接收的方法还可以用一下方法,不同之处在于带有批次和序列控制的时候实现方式不同 The script will load records into ...
- 详解EBS接口开发之采购申请导入
更多内容可以参考我的博客 详解EBS接口开发之采购订单导入 http://blog.csdn.net/cai_xingyun/article/details/17114697 /*+++++++ ...
- 详解EBS接口开发之库存事务处理批次更新
库存事务处理批次有时候出现导入错误需要更新可使用次程序更新,批次导入可参考博客 详解EBS接口开发之库存事务处理-物料批次导入 http://blog.csdn.net/cai_xingyun/art ...
- 供应商API补充(详解EBS接口开发之供应商导入)(转)
原文地址 供应商导入的API补充(详解EBS接口开发之供应商导入) --供应商 --创建 AP_VENDOR_PUB_PKG.Create_Vendor ( p_api_version IN NUM ...
- 集合类 Contains 方法 深入详解 与接口的实例
.Net 相等性:集合类 Contains 方法 深入详解 http://www.cnblogs.com/ldp615/archive/2009/09/05/1560791.html 1.接口的概念及 ...
- 详解 List接口
本篇博文所讲解的这两个类,都是泛型类(关于泛型,本人在之前的博文中提到过),我们在学习C语言时,对于数据的存储,用的差不多都是数组和链表. 但是,在Java中,链表就相对地失去了它的存在价值,因为Ja ...
- 详解EBS接口开发之应收款处理
参考实例参考:杜春阳 R12应收模块收款API研究 (一)应收款常用标准表简介 1.1 常用标准表 如下表中列出了与应收款处理相关的表和说明: 表名 说明 其他信息 AR_BATCHES_ALL ...
- 详解EBS接口开发之库存事务处理采购接收和退货
(一)接收&退货常用标准表简介 1.1 常用标准表 如下表中列出了与采购接收&退货导入相关的表和说明: 表名 说明 其他信息 RCV_TRANSACTIONS 采购接收事务表 事务 ...
- 详解EBS接口开发之供应商导入
(一)供应商常用标准表简介 1.1 常用标准表 如下表中列出了与供应商相关的表和说明: 表名 说明 其他信息 ap_suppliers 供应商头表 供应商的头信息如:供应商名.供应商编码.税号等 ...
随机推荐
- Springboot + Freemarker(一)
Maven pom文件配置 <parent> <groupId>org.springframework.boot</groupId> <artifactId& ...
- SpringCloud服务的注册发现--------Eureka实现高可用
1,Eureka作为注册中心,掌管者服务治理的功能,十分重要,如果注册中心的服务一旦宕机,所有的服务就会挂了,为此,实现注册中心的集群(高可用)就显得十分必要了 2,Eureka 搭建集群 实现原理就 ...
- Java复合优先于继承
复合优于继承 继承打破了封装性(子类依赖父类中特定功能的实现细节) 合理的使用继承的情况: 在包内使用 父类专门为继承为设计,并且有很好的文档说明,存在is-a关系 只有当子类真正是父类的子类型时,才 ...
- dp例题02. 滑雪问题 (poj1088)
poj1088滑雪问题 题目链接:http://poj.org/status Michael喜欢滑雪百这并不奇怪, 因为滑雪的确很刺激.可是为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得 ...
- Python学习-第五节:面向对象
概念: 核心是“过程”二字,“过程”指的是解决问题的步骤,即先干什么再干什么......,基于面向过程设计程序就好比在设计一条流水线,是一种机械式的思维方式.若程序一开始是要着手解决一个大的问题,面向 ...
- stylus--安装及使用方法
stylus介绍 Stylus 是一个CSS的预处理框架,2010年产生,来自Node.js社区,主要用来给Node项目进行CSS预处理支持,所以 Stylus 是一种新型语言,可以创建健壮的.动态的 ...
- Hadoop(四):HDFS读数据的基本流程
HDFS读数据的流程 shell发送下载请求 NameNode检测文件系统,查找a的元数据(block和block所在的位置信息) 返回元数据给shell,返回的元数据会排序,排序规则: 拓扑距离近排 ...
- 100 Path Sum
Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all ...
- Linux bash篇(四 命令)
1.一次执行多个命令 ; eg: ls -al ; touch data.txt 2.根据情况执行命令 && || cmd1 && c ...
- CSS躬行记(5)——渐变
渐变是由两种或多种颜色之间的渐进过渡组成,它是一种特殊的图像类型,分为线性渐变和径向渐变,这两类渐变还会细分为单次和重复两种.渐变图像与传统图像相比,它的优势包括占用更少的字节,避免额外的服务器请求, ...