mapreduce 实现矩阵乘法
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MatrixMultiply {
/** mapper和reducer需要的三个必要变量,由conf.get()方法得到 **/
public static int rowM = 0;
public static int columnM = 0;
public static int columnN = 0; public static class MatrixMapper extends Mapper<Object, Text, Text, Text> {
private Text map_key = new Text();
private Text map_value = new Text(); /**
* 执行map()函数前先由conf.get()得到main函数中提供的必要变量, 这也是MapReduce中共享变量的一种方式
*/
public void setup(Context context) throws IOException {
Configuration conf = context.getConfiguration();
columnN = Integer.parseInt(conf.get("columnN"));
rowM = Integer.parseInt(conf.get("rowM"));
} public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
/** 得到输入文件名,从而区分输入矩阵M和N **/
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName(); if (fileName.contains("M")) {
String[] tuple = value.toString().split(",");
int i = Integer.parseInt(tuple[0]);
String[] tuples = tuple[1].split("\t");
int j = Integer.parseInt(tuples[0]);
int Mij = Integer.parseInt(tuples[1]); for (int k = 1; k < columnN + 1; k++) {
map_key.set(i + "," + k);
map_value.set("M" + "," + j + "," + Mij);
context.write(map_key, map_value);
}
} else if (fileName.contains("N")) {
String[] tuple = value.toString().split(",");
int j = Integer.parseInt(tuple[0]);
String[] tuples = tuple[1].split("\t");
int k = Integer.parseInt(tuples[0]);
int Njk = Integer.parseInt(tuples[1]); for (int i = 1; i < rowM + 1; i++) {
map_key.set(i + "," + k);
map_value.set("N" + "," + j + "," + Njk);
context.write(map_key, map_value);
}
}
}
} public static class MatrixReducer extends Reducer<Text, Text, Text, Text> {
private int sum = 0; public void setup(Context context) throws IOException {
Configuration conf = context.getConfiguration();
columnM = Integer.parseInt(conf.get("columnM"));
} public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int[] M = new int[columnM + 1];
int[] N = new int[columnM + 1]; for (Text val : values) {
String[] tuple = val.toString().split(",");
if (tuple[0].equals("M")) {
M[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]);
} else
N[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]);
} /** 根据j值,对M[j]和N[j]进行相乘累加得到乘积矩阵的数据 **/
for (int j = 1; j < columnM + 1; j++) {
sum += M[j] * N[j];
}
context.write(key, new Text(Integer.toString(sum)));
sum = 0;
}
} /**
* main函数
* <p>
* Usage:
*
* <p>
* <code>MatrixMultiply inputPathM inputPathN outputPath</code>
*
* <p>
* 从输入文件名称中得到矩阵M的行数和列数,以及矩阵N的列数,作为重要参数传递给mapper和reducer
*
* @param args 输入文件目录地址M和N以及输出目录地址
*
* @throws Exception
*/ public static void main(String[] args) throws Exception { if (args.length != 3) {
System.err
.println("Usage: MatrixMultiply <inputPathM> <inputPathN> <outputPath>");
System.exit(2);
} else {
String[] infoTupleM = args[0].split("_");
rowM = Integer.parseInt(infoTupleM[1]);
columnM = Integer.parseInt(infoTupleM[2]);
String[] infoTupleN = args[1].split("_");
columnN = Integer.parseInt(infoTupleN[2]);
} Configuration conf = new Configuration();
/** 设置三个全局共享变量 **/
conf.setInt("rowM", rowM);
conf.setInt("columnM", columnM);
conf.setInt("columnN", columnN); Job job = new Job(conf, "MatrixMultiply");
job.setJarByClass(MatrixMultiply.class);
job.setMapperClass(MatrixMapper.class);
job.setReducerClass(MatrixReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]), new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
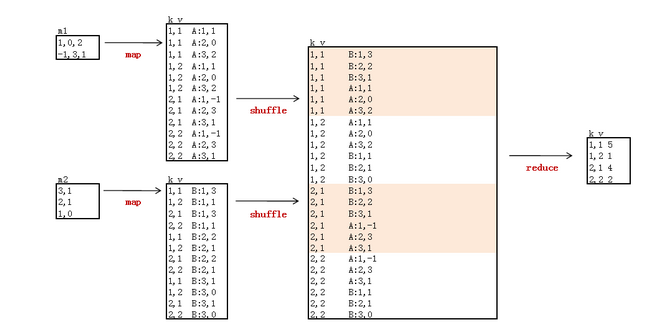
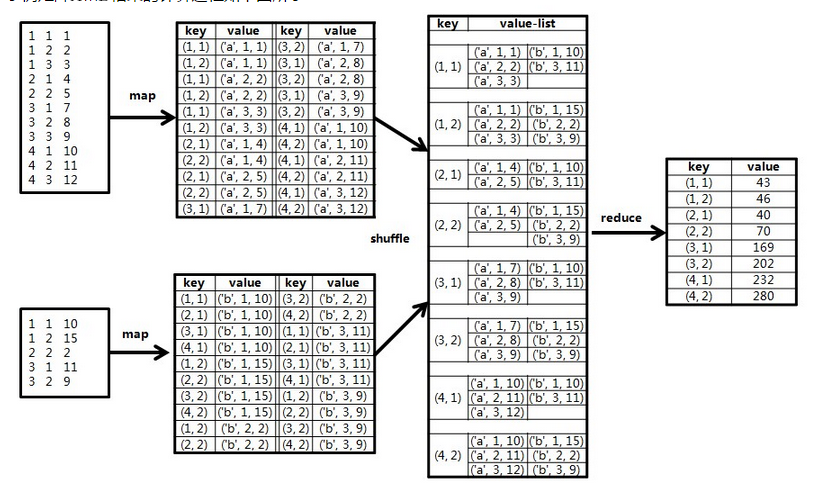
mapreduce 实现矩阵乘法的更多相关文章
- 【甘道夫】MapReduce实现矩阵乘法--实现代码
之前写了一篇分析MapReduce实现矩阵乘法算法的文章: [甘道夫]Mapreduce实现矩阵乘法的算法思路 为了让大家更直观的了解程序运行,今天编写了实现代码供大家參考. 编程环境: java v ...
- MapReduce实现矩阵乘法
简单回想一下矩阵乘法: 矩阵乘法要求左矩阵的列数与右矩阵的行数相等.m×n的矩阵A,与n×p的矩阵B相乘,结果为m×p的矩阵C.具体内容能够查看:矩阵乘法. 为了方便描写叙述,先进行如果: 矩阵A的行 ...
- 基于MapReduce的矩阵乘法
参考:http://blog.csdn.net/xyilu/article/details/9066973文章 文字未得及得总结,明天再写文字,先贴代码 package matrix; import ...
- Python+MapReduce实现矩阵相乘
算法原理 map阶段 在map阶段,需要做的是进行数据准备.把来自矩阵A的元素aij,标识成p条<key, value>的形式,key="i,k",(其中k=1,2,. ...
- 矩阵乘法的MapReduce实现
对于任意矩阵M和N,若矩阵M的列数等于矩阵N的行数,则记M和N的乘积为P=M*N,其中mik 记做矩阵M的第i行和第k列,nkj记做矩阵N的第k行和第j列,则矩阵P中,第i行第j列的元素可表示为公式( ...
- MapReduce实现大矩阵乘法
来自:http://blog.csdn.net/xyilu/article/details/9066973 引言 何 为大矩阵?Excel.SPSS,甚至SAS处理不了或者处理起来非常困难,需要设计巧 ...
- MapReduce的矩阵相乘
一.单个mapreduce的实现 转自:http://blog.sina.com.cn/s/blog_62186b460101ai1x.html 王斌_ICTIR老师的<大数据:互联网大规模数据 ...
- *HDU2254 矩阵乘法
奥运 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submissi ...
- *HDU 1757 矩阵乘法
A Simple Math Problem Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
随机推荐
- Oracle基础 PL-SQL编程基础(1) 变量和常量
一.什么是PL-SQL PL-SQL是结合了Oracle过程语言和结构化查询语言(SQL)的一种扩展语言.具体来说,PL-SQL就是在普通的SQL语句的基础上增加了编程语言的特点,将数据操作和查询语句 ...
- 利用dex2jar反编译apk
下载工具dex2jar和jd-gui ,解压 将要反编译的APK后缀名改为.rar或则 .zip,并解压,得到其中的额classes.dex文件(它就是java文件编译再通过dx工具打包而成的) 将获 ...
- Linux Centos 7 使用yum安装 mysql5.7 (实验成功)
第一部分:安装Mysql5.7 1.下载YUM库 shell > wget http://dev.mysql.com/get/mysql57-community-release-el7-7.no ...
- 18个有用的 .htaccess 文件使用技巧
.htaccess 是 Web 服务器 Apache 中特有的一个配置文件,操控着服务器上的许多行为,我们可以利用它来做许多事情,例如:设置访问权限,网址重定向,等等.本文向大家展示18条 .htac ...
- Kinect For Windows V2开发日志六:人体的轮廓的表示
Kinect中带了一种数据源,叫做BodyIndex,简单来说就是它利用深度摄像头识别出最多6个人体,并且用数据将属于人体的部分标记,将人体和背景区别开来.利用这一特性,就可以在环境中显示出人体的轮廓 ...
- Shuffle an Array
class Solution { private: vector<int> arr, idx; public: Solution(vector<int> nums) { sra ...
- IO输入输出
编写TextRw.java的Java应用程序,程序完成的功能是:首先向TextRw.txt中写入自己的学号和姓名,读取TextRw.txt中信息并将其显示在屏幕上. package com.hanqi ...
- Android实现抽奖转盘
一.SurfaceView认识及的应用的思路 SurfaceView继承自(extends)View,View是在UI线程中进行绘制: 而SurfaceView是在一个子线程中对自己进行绘制,优势:避 ...
- Android DiffUtil
Android 的recyclerview-v7:24.2.0 发布后多了个DiffUtil工具类,这个工具类能够大大解放了Android开发者的一个苦恼:RecyclerView局部刷新和重新刷新时 ...
- 清除windows的EFS加密
所使用软件为aefsdr_setup_en,搜索名为advanced.efs.data.recovery 1. 创建需要加密的文件 2. 进行加密 ...