MapReduce在Map端的Combiner和在Reduce端的Partitioner
1.Map端的Combiner.
通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner...
只附录部分代码:
/**
* 以文本
* hello you
* hello me
* 为例子.
* map方法调用了两次,因为有两行
* k2 v2 键值对的数量有几个?
* 有4个.有四个单词.
*
* 会产生几个分组?
* 产生3个分组.
* 有3个不同的单词.
*
*/
public class WordCountApp {
public static void main(String[] args) throws Exception {
//程序在这里运行,要有驱动.
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,WordCountApp.class.getSimpleName()); //我们运行此程序通过运行jar包来执行.一定要有这句话.
job.setJarByClass(WordCountApp.class);
FileInputFormat.setInputPaths(job,args[0]); job.setMapperClass(WordCountMapper.class);//设置Map类
job.setMapOutputKeyClass(Text.class);//设置Map的key
job.setMapOutputValueClass(LongWritable.class);//设置Map的value job.setCombinerClass(WordCountReducer.class);//数据在Map端先进行 一次合并.
/*
这个setCombinerClass设置参数只能是一个继承了Reduce类的类.直接用我们定义的WordCountReducer.
在单词技术的例子中,Map端产生了四个键值对,两个hello,you和me各一个.
这样合并之后Map端最终只产生三个键值对.
这样在Reduce端也只处理三个键值对,而不是没有合并之前的四个.
这样Map端最终产生的键值对少了,Map端向Reduce端传递键值对占用的带宽就小.提高网络通信的速度.
Reduce端接受键值对的数量变少,就减少了Reduce端处理键值对所需要的时间.
以上就是Combiner的好处(在Map端对数据进行一次合并).
Map端的合并和Reduce端的合并是不能相互取代的.
在Map端进行的合并是局部合并,当前Map任务在它之中的合并.
各个Map任务之间还是会 有相同的数据的.这些相同的数据要到Reduce端进行合并.
*/ job.setReducerClass(WordCountReducer.class);//设置Reduce的类
job.setOutputKeyClass(Text.class);//设置Reduce的key Reduce这个地方只有输出的参数可以设置. 方法名字也没有Reduce关键字区别于Map
job.setOutputValueClass(LongWritable.class);//设置Reduce的value. FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);//表示结束了才退出,不结束不退出
}
......................................................
2.Reduce端的Partitioner.
以流量统计TrafficCountApp.java的例子示例Reduce端设置Partitioner.
只附录部分代码:
public class TrafficApp {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), TrafficApp.class.getSimpleName());
job.setJarByClass(TrafficApp.class);
FileInputFormat.setInputPaths(job, args[0]);
job.setMapperClass(TrafficMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TrafficWritable.class);
job.setNumReduceTasks(2);//设定Reduce的数量为2
job.setPartitionerClass(TrafficPartitioner.class);//设定一个Partitioner的类.
/*
*Partitioner是如何实现不同的Map输出分配到不同的Reduce中?
*在不适用指定的Partitioner时,有 一个默认的Partitioner.
*就是HashPartitioner.
*其只有一行代码,其意思就是过来的key,不管是什么,模numberReduceTasks之后 返回值就是reduce任务的编号.
*numberReduceTasks的默认值是1. 任何一个数模1(取余数)都是0.
*这个地方0就是取编号为0的Reduce.(Reduce从0开始编号.)
*/
job.setReducerClass(TrafficReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TrafficWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class TrafficPartitioner extends Partitioner<Text,TrafficWritable>{//k2,v2
@Override
public int getPartition(Text key, TrafficWritable value,int numPartitions) {
long phoneNumber = Long.parseLong(key.toString());
return (int)(phoneNumber%numPartitions);
}
}
.................................................
//============附录MapReduce中Reduce使用默认的HashPartitioner进行分组的源代码==============
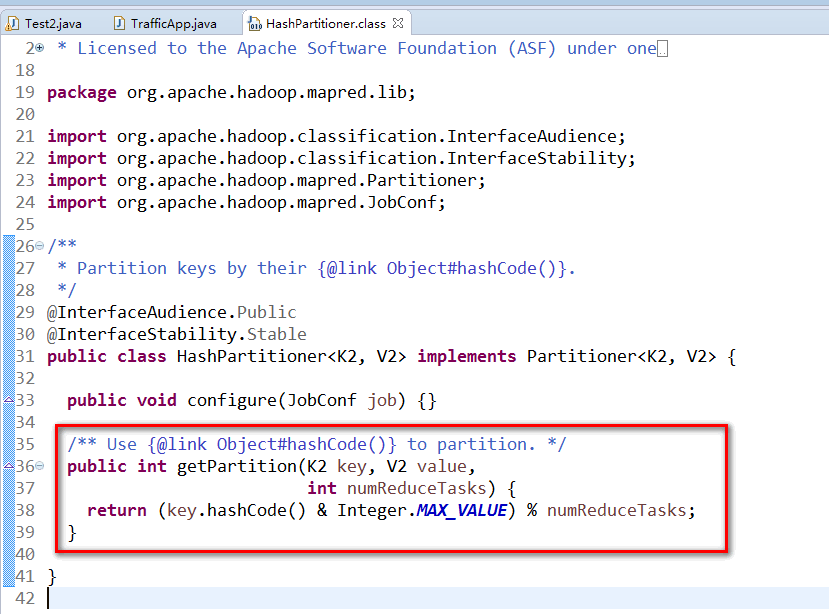
MapReduce在Map端的Combiner和在Reduce端的Partitioner的更多相关文章
- Hadoop2.4.1 MapReduce通过Map端shuffle(Combiner)完成数据去重
package com.bank.service; import java.io.IOException; import org.apache.hadoop.conf.Configuration;im ...
- hadoop的压缩解压缩,reduce端join,map端join
hadoop的压缩解压缩 hadoop对于常见的几种压缩算法对于我们的mapreduce都是内置支持,不需要我们关心.经过map之后,数据会产生输出经过shuffle,这个时候的shuffle过程特别 ...
- 第2节 mapreduce深入学习:15、reduce端的join算法的实现
reduce端的join算法: 例子: 商品表数据 product: pidp0001,小米5,1000,2000p0002,锤子T1,1000,3000 订单表数据 order: pid ...
- Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版) 实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解 1eg 数据如下 20140101 ...
- 【转】reduce端缓存数据过多出现FGC,导致reduce生成的数据无法写到hdfs
转自 http://blog.csdn.net/bigdatahappy/article/details/41726389 转这个目的,是因为该贴子中调优思路不错,值得学习 搜索推荐有一个job,1 ...
- 深入理解Spark 2.1 Core (十一):Shuffle Reduce 端的原理与源代码分析
http://blog.csdn.net/u011239443/article/details/56843264 在<深入理解Spark 2.1 Core (九):迭代计算和Shuffle的原理 ...
- Asp.net SignalR 实现服务端消息推送到Web端
之前的文章介绍过Asp.net SignalR, ASP .NET SignalR是一个ASP .NET 下的类库,可以在ASP .NET 的Web项目中实现实时通信. 今天我 ...
- scala学习笔记(8): 列表的map,flatMap,zip和reduce
map,flatMap,zip和reduce函数可以让我们更容易处理列表函数. 1 map函数map将一个函数应用于列表的每一个元素并且将其作为一个新的列表返回.我们可以这样对列表的元素进行平方: s ...
- JavaScript高级编程——Array数组迭代(every()、filter()、foreach()、map()、some(),归并(reduce() 和reduceRight() ))
JavaScript高级编程——Array数组迭代(every().filter().foreach().map().some(),归并(reduce() 和reduceRight() )) < ...
随机推荐
- Yii CModel中rules验证规则
array( array(‘username’, ‘required’), array(‘username’, ‘length’, ‘min’=>3, ‘max’=>12), array( ...
- linux下面的查找命令
在linux下面经常用查找命令,我自己最常用的是find whereis locate 关于find 我常用find的基本功能,如 find / -name filename 在某个目录下寻找文件. ...
- ActiveX控件是什么?
一.ActiveX的由来 ActiveX最初只不过是一个商标名称而已,它所涵盖的技术并不是各自孤立的,其中多数都与Internet和Web有一定的关联.更重要的是,ActiveX的整体技术是由Micr ...
- ThinkPHP框架的网站url重写
nginx location / { root /var/www; index index.html index.htm index.php; if (!-e $request_filename) { ...
- Windows-to-go-带着win10满街跑
一.前言 有句话是这么说的,程序员对工作是时刻准备着的.无论你是长假还是短假,只要有网,你就躲不开客户.这样子,当你外出的时候你可以选择时刻背着电脑,因为你的电脑有着你顺手的开发工具以及开发环境.我们 ...
- Listview上下滚动崩溃
利用CursorAdapter在ListView中显示Cursor中不同同类型的item,加载均正常,滚动时报如下错误: 11-28 15:18:16.703: E/InputEventReceive ...
- MVC神韵---你想在哪解脱!(十六)
MVC验证属性自动验证原理 也许有人会问,既然我们没有在C与V追加任何显示错误信息提示的代码,那么控制器或视图内部是如何生成这些显示错误信息提示的画面的.让我们揭开这么谜底吧!当在Movie类中追加了 ...
- Row_Number()over(order by....) as
出自:http://www.2cto.com/database/201307/227103.html Sql Server Row_Number()学习 Row_Number(): row_n ...
- iOS开发-block使用与多线程
Block Block封装了一段代码,可以在任何时候执行 Block可以作为函数参数或者函数的返回值,而其本身又可以带输入参数或返回值. 苹果官方建议尽量多用block.在多线程.异步任务.集合遍历. ...
- UVa 11111 Generalized Matrioshkas
嵌套玩具, 要求外层玩具的尺寸比内层玩具尺寸的和要大. 每一个玩具由一个负数与相应的正数表示, 在这两数之间的部分即为此玩具内部的玩具. 要求判断一串输出的数字是否能组成一个合法的玩具. 一个合法的玩 ...