Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版)
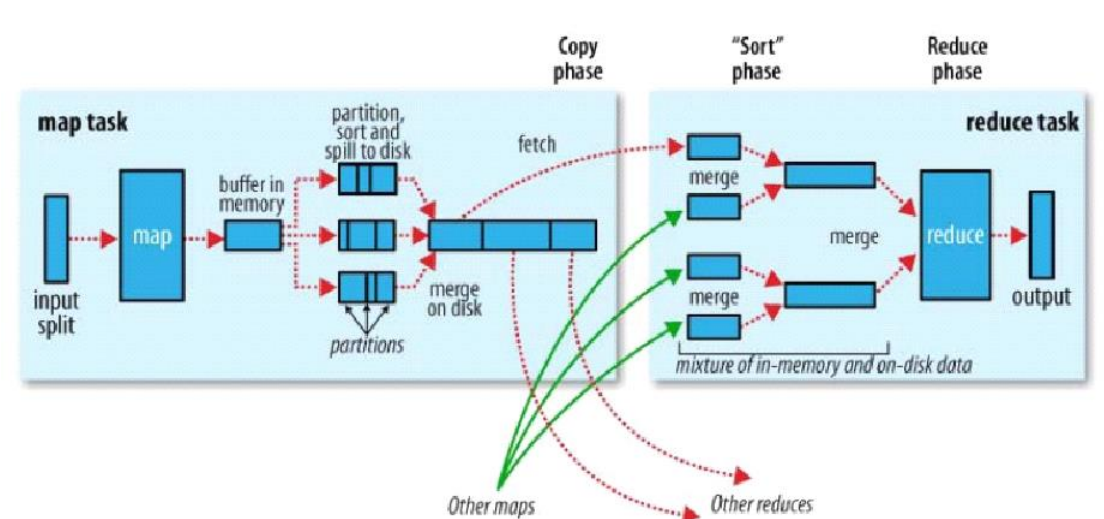
实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解
1eg 数据如下 2014010114 标识20140101日的温度为14度,需求为统计每年温度的最最高值
2014010114
2014010216
2014010317
2014010410。。。
Partition 实际是根据map 任务的key,以及reduce任务的数量来决定最终来由那个reduce来处理,默认指定reduce的方法是key的hash 对reduce的数量取模来决定由那个reduce处理,map端将年作为key,温度作为value ,不指定reduce任务的情况下 默认的reduce数量为1,按照上面的规则 hashcode%1 =0(任何数对1求模对为0) 所以看到最后输出到HDFS中的文件名为part-r-0000 证明只有1个reduce 来处理任务
为了验证上面的猜想,自己重写了Partition规则, year%2 作为规则,偶数年为reduce1 处理, 奇数年由reduce2 处理,结果发现part-r-0000
2014 17
2012 32
2010 17
2008 37
part-r-0001
2015 99
2013 29
2007 99
2001 29
其中自己在reduce端做了二次排序,二次排序的概念就是 针对这组相对的key 怎么来输出结果,默认的牌勋规则是字典排序,按照英文字母的顺序,当然自己可以重写输出的规则,自己按照年的倒序输出,试验后基本明白了 shuffle 的partion 和reduce端的二次排序
partition重写负责如下
public class WDPartition extends HashPartitioner<Text,IntWritable> {
@Override
public int getPartition(Text text, IntWritable value, int numReduceTasks) {
// TODO Auto-generated method stub
int year = Integer.valueOf(text.toString());
return year%2;
}
}
reduce 的二次排序如下
public class WDSort extends WritableComparator{
public WDSort(){
super(Text.class, true);
}
//按照key 来降序排序
public int compare(WritableComparable a, WritableComparable b) {
String t1 = a.toString();
String t2 = b.toString();
return -Integer.compare(Integer.valueOf(t1), Integer.valueOf(t2));
}
}
Haoop MapReduce 的Partition和reduce端的二次排序的更多相关文章
- MapReduce在Map端的Combiner和在Reduce端的Partitioner
1.Map端的Combiner. 通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner... 只附录部分代码: /** * 以文本 * hello you * he ...
- 第2节 mapreduce深入学习:15、reduce端的join算法的实现
reduce端的join算法: 例子: 商品表数据 product: pidp0001,小米5,1000,2000p0002,锤子T1,1000,3000 订单表数据 order: pid ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- 深入理解Spark 2.1 Core (十一):Shuffle Reduce 端的原理与源代码分析
http://blog.csdn.net/u011239443/article/details/56843264 在<深入理解Spark 2.1 Core (九):迭代计算和Shuffle的原理 ...
- hadoop的压缩解压缩,reduce端join,map端join
hadoop的压缩解压缩 hadoop对于常见的几种压缩算法对于我们的mapreduce都是内置支持,不需要我们关心.经过map之后,数据会产生输出经过shuffle,这个时候的shuffle过程特别 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- MapReduce启动的Map/Reduce子任务简要分析
对于Hadoop来说,是通过在DataNode中启动Map/Reduce java进程的方式来实现分布式计算处理的,那么就从源码层简要分析一下hadoop中启动Map/Reduce任务的过程. ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
随机推荐
- 1012 u Calculate e
A simple mathematical formula for e iswhere n is allowed to go to infinity. This can actually yield ...
- 华硕 F1A55-M LX3系列跳线图
天啊,第一次遇到这么变态的主板跳线...浪费我好久时间找到这跳线图
- Java学习笔记——山西煤老板蛋疼的拉车问题
小荷才露尖尖角,早有蜻蜓立上头 --小池 这个问题是这样描述的: 山西煤老板有3000吨煤,要运到1000km公里外的地方卖.他选择使用火车来运煤,每辆火车行驶一公里将消耗一吨煤,且火车载货上限为10 ...
- 如何使用.bas文件
1. 确保你安装的是word 2010,打开word文档,,按ALT + F11打开VBE编辑器. 2.点击Normal,右键,在弹出的对话框中选择导入文件. 2. 选择需要使用的脚本的位置,然后点击 ...
- 也许是目前实现最好的js模拟滚动插件
finger-mover 是一个集成 Fingerd(移动端以手指为单位的事件管理方案) 和 Moved(微型运动方案) 为一体的移动端动效平台,finger-mover 本身并不能为你做什么,但是附 ...
- 【JAVAWEB学习笔记】13_servlet
JavaWeb核心之Servlet 教学目标 案例一.完成用户登录功能 案例二.记录成功登录系统的人次 一.Servlet简介 1.什么是Servlet Servlet 运行在服务端的Java小程序, ...
- mac下使用命令行打包出现bash gradle command not found的解决方案
命令行打包的时候出现 bash gradle command not found这个问题,主要是因为gradle环境丢失.需要重新配置gradle的环境变量. 1. gradle路径的查找 然后gra ...
- (HTTPS)-强制 SSL (HTTPS)Filter
汗,无知真可怕,Servlert规范中已经有自动跳转到保护页面(Http - Https)的方法了: web.xml <security-constraint> ...
- spring-线程池(1)
多线程并发处理起来通常比较麻烦,如果你使用spring容器来管理业务bean,事情就好办了多了.spring封装了java的多线程的实现,你只需要关注于并发事物的流程以及一些并发负载量等特性,具体来说 ...
- Java 开发中如何正确踩坑
为什么说一个好的员工能顶 100 个普通员工 我们的做法是,要用最好的人.我一直都认为研发本身是很有创造性的,如果人不放松,或不够聪明,都很难做得好.你要找到最好的人,一个好的工程师不是顶10个,是顶 ...