jieba分词学习
具体项目在githut里面:
应用jieba库分词
1)利用jieba分词来统计词频:
对应文本为我们队伍的介绍:jianjie.txt:
项目名称:碎片
项目描述:制作一个网站,拾起日常碎片,记录生活点滴!
项目成员:孔潭活、何德新、吴淑瑶、苏咏梅
成员风采:
孔潭活:2015034643032
何德新:
学号:2015034643017
风格:咸鱼王
擅长技术:设计
编程兴趣:机器学习、人工智能。希望的软工角色:项目经理。
一句话宣言:持而盈之,不如其已。揣而锐之,不可常保。道可道非常道;名可名非常名
吴淑谣:
学号:2015034643018
风格:细水长流
擅长技术:无,对C++比较熟悉
编程兴趣:对数据进行处理和分析
希望的软工角色:代码能力比较薄弱,希望负责技术含量不是很高的模块
一句话宣言:推陈出新,永无止境。
苏咏梅:
学号:2015034643025
风格:越挫越勇
擅长技术:没有比较擅长的,对MySQL与Java感兴趣
希望的软工角色:需求分析员
一句话宣言:要成功,先发疯,头脑简单向前冲
课程目标
一个小而美记录生活碎片的网站
代码:
import jieba
import jieba.analyse
import xlwt #写入Excel表的库
if name == "main":
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("wordCount") # Excel单元格名字
word_lst = []
key_list = []
for line in open('jianjie.txt'): # jianjie.txt是需要分词统计的文档
item = line.strip('\n\r').split('\t') # 制表格切分
# print item
tags = jieba.analyse.extract_tags(item[0]) # jieba分词
for t in tags:
word_lst.append(t)
word_dict = {}
with open("wordCount.txt", 'w') as wf2: # 打开文件
for item in word_lst:
if item not in word_dict: # 统计数量
word_dict[item] = 1
else:
word_dict[item] += 1
for item in word_lst:
if word_dict[item]==1:
del word_dict[item]
orderList = list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key] == orderList[i]:
wf2.write(key + ' ' + str(word_dict[key]) + '\n') # 写入txt文档
key_list.append(key)
word_dict[key] = 0
for i in range(len(key_list)):
sheet.write(i, 1, label=orderList[i])
sheet.write(i, 0, label=key_list[i])
wbk.save('wordCount.xls') # 保存为 wordCount.xls文件
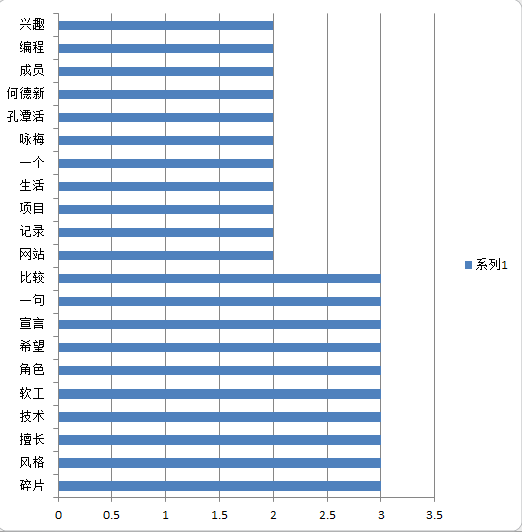
2)统计的词频会输出两个文件一个是txt文件另外一个是xls文件名字都是wordCount
我们利用excel来绘图
jieba分词学习的更多相关文章
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- jieba分词(2)
结巴分词系统中实现了两种关键词抽取法,一种是TF-IDF关键词抽取算法另一种是TextRank关键词抽取算法,它们都是无监督的算法. 以下是两种算法的使用: #-*- coding:utf-8 -*- ...
- jieba分词原理-DAG(NO HMM)
最近公司在做一个推荐系统,让我给论坛上的帖子找关键字,当时给我说让我用jieba分词,我周末回去看了看,感觉不错,还学习了一下具体的原理 首先,通过正则表达式,将文章内容切分,形成一个句子数组,这个比 ...
- jieba分词流程及部分源码解读(一)
首先我们来看一下jieba分词的流程图: 结巴中文分词简介 1)支持三种分词模式: 精确模式:将句子最精确的分开,适合文本分析 全模式:句子中所有可以成词的词语都扫描出来,速度快,不能解决歧义 搜索引 ...
- 自然语言处理课程(二):Jieba分词的原理及实例操作
上节课,我们学习了自然语言处理课程(一):自然语言处理在网文改编市场的应用,了解了相关的基础理论.接下来,我们将要了解一些具体的.可操作的技术方法. 作为小说爱好者的你,是否有设想过通过一些计算机工具 ...
- jieba分词-强大的Python 中文分词库
1. jieba的江湖地位 NLP(自然语言)领域现在可谓是群雄纷争,各种开源组件层出不穷,其中一支不可忽视的力量便是jieba分词,号称要做最好的 Python 中文分词组件. 很多人学习pytho ...
- python使用matplotlib画图,jieba分词、词云、selenuium、图片、音频、视频、文字识别、人脸识别
一.使用matplotlib画图 关注公众号"轻松学编程"了解更多. 使用matplotlib画柱形图 import matplotlib from matplotlib impo ...
- widows下jieba分词的安装
在切词的时候使用到jieba分词器,安装如下: 切入到结巴包,执行 python setup.py install 安装后,可以直接在代码中引用: import jieba
- 【原】关于使用jieba分词+PyInstaller进行打包时出现的一些问题的解决方法
错误现象: 最近在做一个小项目,在Python中使用了jieba分词,感觉非常简洁方便.在Python端进行调试的时候没有任何问题,使用PyInstaller打包成exe文件后,就会报错: 错误原因分 ...
随机推荐
- 分享-结合demo讲解JS引擎工作原理
代码如下: var x = 1; function A(y){ var x = 2; function B(z){ console.log(x+y+z); } return B; } var C = ...
- rename 表
----执行过程 TS.TEST ---RENAME INDEX(索引) ALTER INDEX TS.IDX1_TEST RENAME TO IDX1_TEST_BAK; ALTER INDEX T ...
- VS2010自行编译OpenCV2.4.4时缺少python27_d.lib的解决方法
错误 24 error LNK1104: 无法打开文件“python27_d.lib” C:\OpenCV\VS2013_64\modules\python\LINK opencv_python 编 ...
- jQuery封装自定义事件--valuechange(动态的监听input,textarea)之前值,之后值的变化
jQuery封装自定义事件--valuechange(动态的监听input,textarea)之前值,之后值的变化 js监听输入框值的即时变化 网上有很多关于 onpropertychange.oni ...
- css实现气泡框效果
前提:气泡框或者提示框是网页很常见的,实现它的方式有很多,我们以前最常用的就是切图片 然后通过 "定位" 方式 定位到相应的位置,但是用这种方式维护很麻烦,比如设计师想改成另外一种 ...
- Android 关于在ScrollView中加上一个ListView,ListView内容显示不完全(总是显示第一项)的问题的两种简单的解决方案
是这样的哈: 有这样一个需求: 1.显示一个界面,界面上有一个列表(ListView),列表上面有一个可以滚动的海报. 2.要求在ListView滚动的过程中,ListView上面的海报也可以跟着Li ...
- NLB网路负载均衡管理器详解(转载)
序言 在上一篇配置iis负载均衡中我们使用啦微软的ARR,我在那篇文章也中提到了网站的高可用性,但是ARR只能做请求入口的消息分发服务,这样如果我们的消息分发服务器给down掉啦,那么做再多的应用服务 ...
- Ubuntu系统上双节点部署OpenStack
安装和部署双节点OpenStack 介绍: 1.宿主机:Win10操作系统 2.在VMware下创建两台虚拟机: devstack-controller:控制节点 + 网络节点 + 块存储节点 + 计 ...
- 20155226《网络攻防》 Exp3 免杀原理与实践
20155226<网络攻防> Exp3 免杀原理与实践 实验过程 1. msfvenom直接生成meterpreter可执行文件 直接将上周做实验时用msf生成的后门文件放在virscan ...
- 2017-2018-2 20155230《网络对抗技术》实验1:PC平台逆向破解(5)M
1.直接修改程序机器指令,改变程序执行流程 2.通过构造输入参数,造成BOF攻击,改变程序执行流 3.注入Shellcode并执行 4.实验感想 注:因为截图是全屏所以右键图片在新的标签页打开观看更加 ...