Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点:
1. python requests库
2. 正则表达式
3. csv模块
4. 多进程
正文
目标站点分析
通过对目标站点的分析, 来确定网页结构, 进一步确定具体的抓取方式.
1. 浏览器打开猫眼电影首页, 点击"榜单", 点击"Top100榜", 即可看到目标页面.
2. 浏览网页, 滚动到下方发现有分页, 切换到第2页, 发现: URL从 http://maoyan.com/board/4变换到http://maoyan.com/board/4?offset=10, 多次切换页码offset都有改变, 可以确定的是通过改变URL的offset参数来生成分页列表.
项目流程框架:
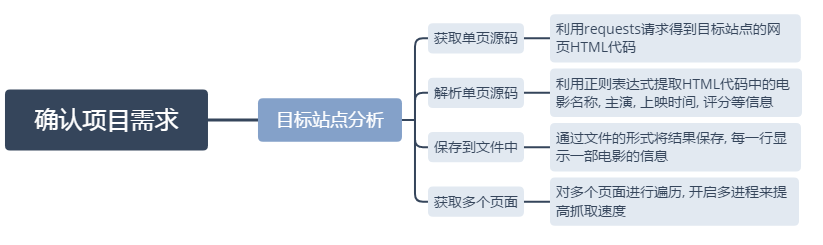
获取单页源码
#抓取猫眼电影TOP100榜
import requests
import time
from requests.exceptions import RequestException
def get_one_page():
'''获取单页源码'''
try:
url = "http://maoyan.com/board/4?offset={0}".format(0)
headers = {
"User-Agent":"Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36"
}
res = requests.get(url, headers=headers)
# 判断响应是否成功,若成功打印响应内容,否则返回None
if res.status_code == 200:
print(res.text)
return None
except RequestException:
return None
def main():
get_one_page()
if __name__ == '__main__':
main()
time.sleep(1)
执行即可得到网页源码, 那么下一步就是解析源码了
解析单页源码
导入正则表达式re模块, 对代码进行解析, 得到想要的信息.
import re def parse_one_page(html):
'''解析单页源码'''
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime'
+ '.*?>(.*?)</p>.*?score.*?integer">(.*?)</i>.*?>(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
print(items)
#采用遍历的方式提取信息
for item in items:
yield {
'rank' :item[0],
'title':item[1],
'actor':item[2].strip()[3:] if len(item[2])>3 else '', #判断是否大于3个字符
'time' :item[3].strip()[5:] if len(item[3])>5 else '',
'score':item[4] + item[5]
}
def main():
html = get_one_page()
for item in parse_one_page(html):
print(item) if __name__ == '__main__':
main()
time.sleep(1)
提取出信息之后, 那么下一步就是保存到文件
保存到文件中
这里采用两种方式, 一种是保存到text文件, 另一种是保存到csv文件中, 根据需要选择其一即可.
1. 保存到text文件
import json def write_to_textfile(content):
'''写入到text文件中'''
with open("MovieResult.text",'a',encoding='utf-8') as f:
#利用json.dumps()方法将字典序列化,并将ensure_ascii参数设置为False,保证结果是中文而不是Unicode码.
f.write(json.dumps(content,ensure_ascii=False) + "\n")
f.close()
def main():
html = get_one_page()
for item in parse_one_page(html):
write_to_textfile(item) if __name__ == '__main__':
main()
time.sleep(1)
2. 保存到CSV文件
其文件以纯文本的形式存储表格数据
import csv
def write_to_csvfile(content):
'''写入到csv文件中'''
with open("MovieResult.csv",'a',encoding='gb18030',newline='') as f:
# 将字段名传入列表
fieldnames = ["rank", "title", "actor", "time", "score"]
#将字段名传给Dictwriter来初始化一个字典写入对象
writer = csv.DictWriter(f,fieldnames=fieldnames)
#调用writeheader方法写入字段名
writer.writeheader()
writer.writerows(content)
f.close()
def main():
html = get_one_page()
rows = []
for item in parse_one_page(html):
#write_to_textfile(item)
rows.append(item)
write_to_csvfile(rows)
if __name__ == '__main__':
main()
time.sleep(1)
单页的信息已经提取出, 接着就是提取多个页面的信息
获取多个页面
1. 普通方法抓取
def main(offset):
url = "http://maoyan.com/board/4?offset={0}".format(offset)
html = get_one_page(url)
rows = []
for item in parse_one_page(html):
#write_to_textfile(item)
rows.append(item)
write_to_csvfile(rows)
if __name__ == '__main__':
#通过遍历写入TOP100信息
for i in range(10):
main(offset=i * 10)
time.sleep(1)
2. 多进程抓取
from multiprocessing import Pool if __name__ == '__main__':
# 将字段名传入列表
fieldnames = ["rank", "title", "actor", "time", "score"]
write_to_csvField(fieldnames)
pool = Pool()
#map方法会把每个元素当做函数的参数,创建一个个进程,在进程池中运行.
pool.map(main,[i*10 for i in range(10)])
完整代码
#抓取猫眼电影TOP100榜
from multiprocessing import Pool
from requests.exceptions import RequestException
import requests
import json
import time
import csv
import re
def get_one_page(url):
'''获取单页源码'''
try:
headers = {
"User-Agent":"Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36"
}
res = requests.get(url, headers=headers)
# 判断响应是否成功,若成功打印响应内容,否则返回None
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
def parse_one_page(html):
'''解析单页源码'''
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime'
+ '.*?>(.*?)</p>.*?score.*?integer">(.*?)</i>.*?>(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
#采用遍历的方式提取信息
for item in items:
yield {
'rank' :item[0],
'title':item[1],
'actor':item[2].strip()[3:] if len(item[2])>3 else '', #判断是否大于3个字符
'time' :item[3].strip()[5:] if len(item[3])>5 else '',
'score':item[4] + item[5]
} def write_to_textfile(content):
'''写入text文件'''
with open("MovieResult.text",'a',encoding='utf-8') as f:
#利用json.dumps()方法将字典序列化,并将ensure_ascii参数设置为False,保证结果是中文而不是Unicode码.
f.write(json.dumps(content,ensure_ascii=False) + "\n")
f.close() def write_to_csvField(fieldnames):
'''写入csv文件字段'''
with open("MovieResult.csv", 'a', encoding='gb18030', newline='') as f:
#将字段名传给Dictwriter来初始化一个字典写入对象
writer = csv.DictWriter(f,fieldnames=fieldnames)
#调用writeheader方法写入字段名
writer.writeheader()
def write_to_csvRows(content,fieldnames):
'''写入csv文件内容'''
with open("MovieResult.csv",'a',encoding='gb18030',newline='') as f:
#将字段名传给Dictwriter来初始化一个字典写入对象
writer = csv.DictWriter(f,fieldnames=fieldnames)
#调用writeheader方法写入字段名
#writer.writeheader() ###这里写入字段的话会造成在抓取多个时重复.
writer.writerows(content)
f.close() def main(offset):
fieldnames = ["rank", "title", "actor", "time", "score"]
url = "http://maoyan.com/board/4?offset={0}".format(offset)
html = get_one_page(url)
rows = []
for item in parse_one_page(html):
#write_to_textfile(item)
rows.append(item)
write_to_csvRows(rows,fieldnames) if __name__ == '__main__':
# 将字段名传入列表
fieldnames = ["rank", "title", "actor", "time", "score"]
write_to_csvField(fieldnames)
# #通过遍历写入TOP100信息
# for i in range(10):
# main(offset=i * 10,fieldnames=fieldnames)
# time.sleep(1)
pool = Pool()
#map方法会把每个元素当做函数的参数,创建一个个进程,在进程池中运行.
pool.map(main,[i*10 for i in range(10)])
效果展示:
最终采用写入csv文件的方式.

Python爬虫项目--爬取猫眼电影Top100榜的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
随机推荐
- python语言中的数据类型
一.内存管理 1.python解释器的垃圾回收机制 垃圾:当一个值上没有人绑定任何变量名时(当引用计数为0),该值就是一个垃圾. python解释器运行时会检测值的引用计数,当引用计数=0该值会被清除 ...
- b2BuoyancyController 使用浮力
package{ import Box2D.Collision.b2AABB; import Box2D.Collision.b2RayCastInput; import Box2D.Collisio ...
- qurtz.net
Quartz.NET的使用(附源码)(作者 陈珙) 简介 虽然Quartz.NET被园子里的大神们写烂了,自己还是整理了一篇,结尾会附上源码地址. Quartz.NET是一款功能齐全的开源作业调度 ...
- 【原创】锐捷实现OSPF路由协议和NAT地址转换协议
路由网络设计与实施 [锐捷设备实现OSPF路由协议与NAT地址转换] 说明: 本文是在多VLAN双星型交换网络的基础之上发展的.关于组建多VLAN双星型交换网络,请参阅: <思科和锐捷组建多 ...
- Ldap-crack-test?
ldap #!/bin/env python import sys import ldap ldapconn = ldap.initialize('ldap://domain.adserve.com' ...
- 手动安裝TMG2010所需Windows服务和功能
安装 Forefront TMG 之前,必须运行准备工具,以验证是否已在您的计算机上安装成功安装 Forefront TMG 所需的应用程序.如果在未首先运行准备工具的情况下运行 Forefront ...
- Swift重写UIButton的图片和标题的位置
import UIKit class ResetBtn: UIButton { let IMAGE_RATIO :CGFloat = 0.7 // 图片占整个按钮高度的比例 let TITLE_FON ...
- 关于池化(pooling)理解!!!
网上看到一个池化的解释是: 为了描述大的图像,可以对不同位置的特征进行聚合统计,如计算平均值或者是最大值,即mean-pooling和max-pooling 我的想法是,图像做卷积以后,将图像信息(特 ...
- 开始jQuery学习之旅
jQuery写法 //实例写法$('div').css({width:200,backgroundColor:'red'}); 参数规则 // css selector$('.wrapper ul l ...
- qt 中的基本知识
1. 由 .ui 文件生成界面头文件: uic -o ui_dialog.h dialog.ui 2. 在工程目录下生成与平台无关的工程文件 : qmake -project 3. 生成与平台相关的 ...