[转帖]Prometheus+Grafana监控Kubernetes
原博客的位置:
https://blog.csdn.net/shenhonglei1234/article/details/80503353
感谢原作者
这里记录一下自己试验过程中遇到的问题:
. 自己查看prometheus 里面的配置文件时 对mount的路径理解不清晰,以为是需要宿主机里面需要有目录才可以, 实际上不需要. 是k8s 将证书和token注入到container 里面去 使之能够与集群交互. 这里自己学习的不系统, 浪费了很多时间. 以为需要生成一个token 挂在进去才可以.
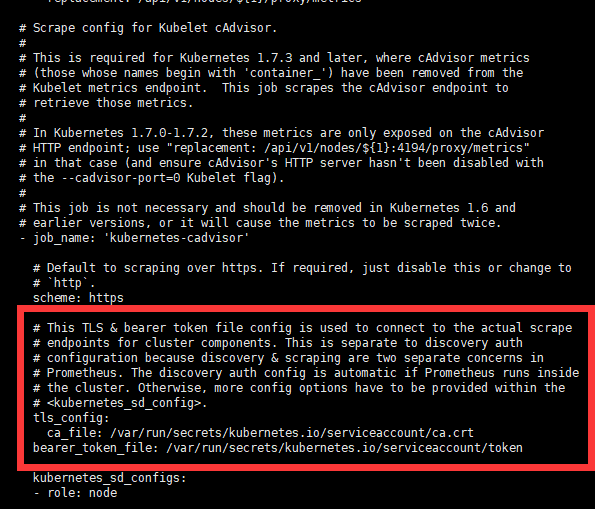
. 配置文件里面使用了nfs 的方式来挂作为pv和pvc的处理
一开始没注意,发现pod 总是 error 使用kubectl logs 命令找到问题原因后 修改了配置文件 创建自己的nfs server 才可以. 可以参考自己之前的 blog 有写制作blog
. nfs创建完成之后依旧报错. 这里的问题是 nfs 的目录的权限问题 提示 授权失败 无法绑定路径
翻墙google了下解决方案 将 nfs 目录修改成为 777权限,并且把owner 修改成 nobody 问题解决.
. service 如何暴露成为主机端口以及ingress的使用暂时还没弄清楚. 后续继续进行学习 感谢原作者的奉献 自己直接讲blog copy过来. 遇到的问题 在这里填充一下.
Prometheus+Grafana监控Kubernetes
涉及文件下载地址:链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6
文件中需要下载的镜像需要自己提前下载好,eg:prom/node-exporter:v0.16.0
Prometheus官方网址,或者百度自己了解脑补:https://prometheus.io/
官方文档说明链接
Prometheus是一个开源的系统监控工具。
根据配置的任务(job)以http/s周期性的收刮(scrape/pull)
指定目标(target)上的指标(metric)。目标(target)
可以以静态方式或者自动发现方式指定。
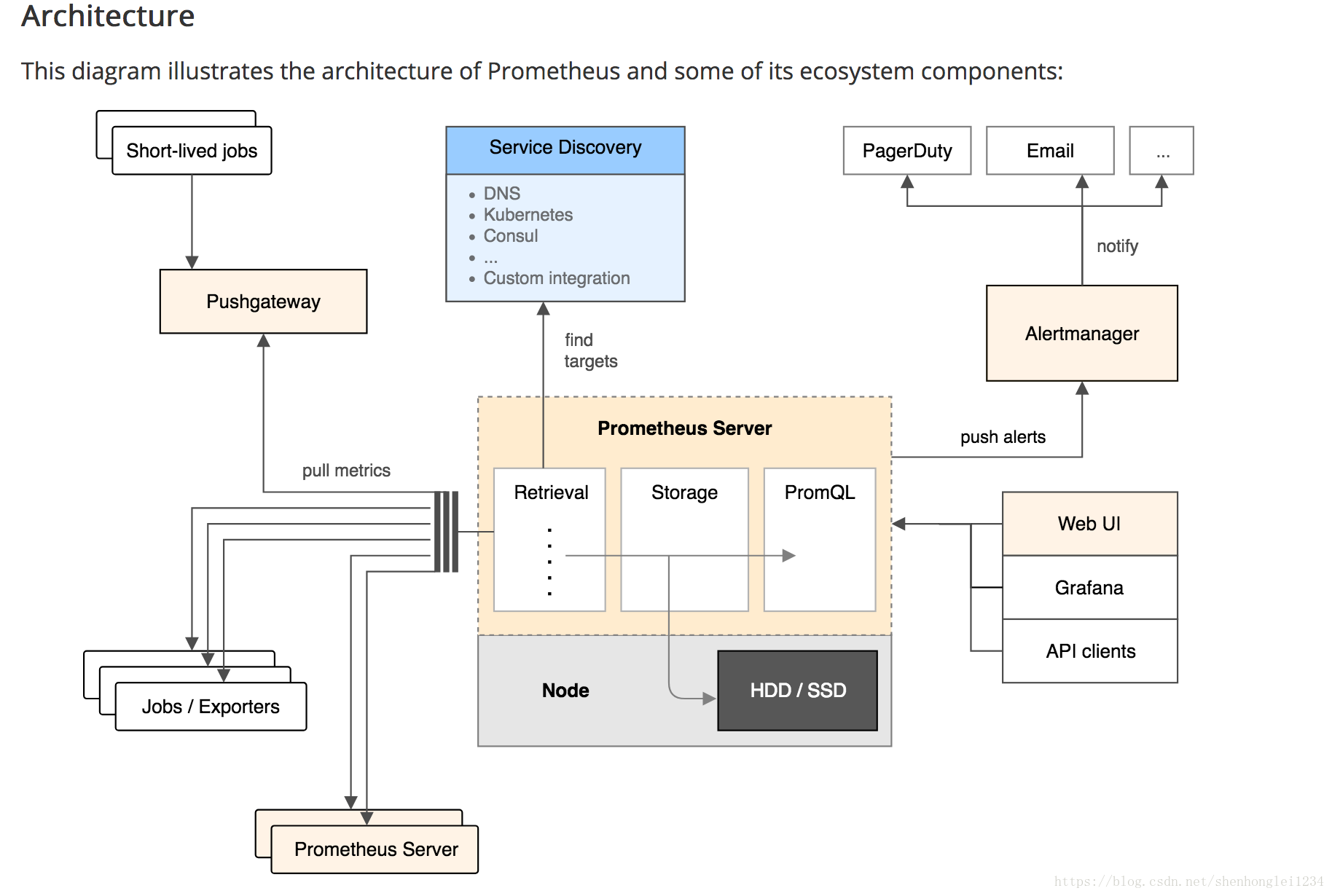
Prometheus将收刮(scrape)的指标(metric)保存在本地或者远程存储上。 Prometheus以pull方式来收集指标。对比push方式,
pull可以集中配置、针对不同的视角搭建不同的监控系统 Prometheus Server:核心组件,负责收刮和存储时序数据(time series data),并且提供查询接口; Jobs/Exporters:客户端,监控并采集指标,对外暴露HTTP服务(/metrics);
目前已经有很多的软件原生就支持Prometjeus,提供/metrics,可以直接使用;
对于像操作系统已经不提供/metrics的应用,可以使用现有的exporters
或者开发自己的exporters来提供/metrics服务; Pushgateway:针对push系统设计,Short-lived jobs定时将指标push到Pushgateway,再由Prometheus Server从Pushgateway上pull; Alertmanager:报警组件,根据实现配置的规则(rule)进行响应,例如发送邮件; Web UI:Prometheus内置一个简单的Web控制台,可以查询指标,查看配置信息或者Service Discovery等,实际工作中,查看指标或者创建仪表盘通常使用Grafana,Prometheus作为Grafana的数据源; 数据结构
Prometheus按照时间序列存储指标,每一个指标都由Notation + Samples组成:
Notation:通常有指标名称与一组label组成:
<metric name>{<label name>=<label value>, ...}
Samples:样品,通常包含一个64位的浮点值和一个毫秒级的时间戳
下面是在Mac上安装使用Prometheus+Grafana监控Kubernetes演示
链接==-==Kubernetes Dashboard 安装,快速,简便运行Dashboard
环境如下:Docker for Mac 或者 Edge 版本的内置的 Kubernetes 集群
- 命令查看环境信息
kubectl get nodes -o wide
[root@k8smaster01 PrometheusGrafana]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8smaster01 Ready master 77d v1.10.1 <none> CentOS Linux (Core) 3.10.-.el7.x86_64 docker://17.3.2
k8snode01 Ready <none> 77d v1.10.1 <none> CentOS Linux (Core) 3.10.-.el7.x86_64 docker://17.3.2
k8snode02 Ready <none> 77d v1.10.1 <none> CentOS Linux (Core) 3.10.-.el7.x86_64 docker://17.3.2
kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default brown-iguana-postgresql-7b485855c8-8jnsf / Pending 39d <none> <none>
default brown-iguana-sonarqube-799854bf8-ptcp6 / CrashLoopBackOff 11d 10.244.0.79 k8smaster01
default frontend-7vlmm / Running 11d 10.244.0.78 k8smaster01
default frontend-krz57 / Running 21d 10.244.0.80 k8smaster01
default frontend-pzlnd / Running 11d 10.244.0.82 k8smaster01
default my-release-jenkins-5d77b99899-9g7mr / Pending 39d <none> <none>
default nfs-busybox-l596c / Running 39d 10.244.0.84 k8smaster01
default nfs-web-5pj87 / Running 21d 10.244.0.83 k8smaster01
default prometheus-675b6f7b46-7p9kd / Running 4h 10.244.1.30 k8snode01
default redis-master-4hkwr / Evicted 11d <none> k8smaster01
default redis-master-fqrkh / Running 6d 10.244.2.186 k8snode02
default redis-slave-9dfx5 / Running 11d 10.244.0.81 k8smaster01
default redis-slave-gnjvb / Running 21d 10.244.0.85 k8smaster01
kube-system etcd-k8smaster01 / Running 77d 10.24.103.1 k8smaster01
kube-system kube-apiserver-k8smaster01 / Running 77d 10.24.103.1 k8smaster01
kube-system kube-controller-manager-k8smaster01 / Running 77d 10.24.103.1 k8smaster01
kube-system kube-dns-86f4d74b45-bq26h / Running 11d 10.244.0.88 k8smaster01
kube-system kube-flannel-ds-6xw52 / Running 77d 10.24.103.3 k8snode02
kube-system kube-flannel-ds-9kflb / Running 77d 10.24.103.2 k8snode01
kube-system kube-flannel-ds-ql64x / Running 77d 10.24.103.1 k8smaster01
kube-system kube-proxy-fdnhw / Running 77d 10.24.103.1 k8smaster01
kube-system kube-proxy-k5bq6 / Running 77d 10.24.103.3 k8snode02
kube-system kube-proxy-zzfm5 / Running 77d 10.24.103.2 k8snode01
kube-system kube-scheduler-k8smaster01 / Running 77d 10.24.103.1 k8smaster01
kube-system kubernetes-dashboard-5c469b58b8-847pl / Running 11d 10.244.0.87 k8smaster01
kube-system tiller-deploy-64cc99bc7-ntr7v / Running 11d 10.244.0.86 k8smaster01
ns-monitor grafana-865bdd58bc-znhdg / Running 41m 10.244.1.35 k8snode01
ns-monitor node-exporter-2xj9m / Running 2h 10.24.103.3 k8snode02
ns-monitor node-exporter-spntx / Running 2h 10.24.103.1 k8smaster01
ns-monitor node-exporter-tdtq8 / Running 2h 10.24.103.2 k8snode01
ns-monitor prometheus-544bf54848-fxl9r / Running 48m 10.244.2.190 k8snode02
- Kubernetes的Dashboard
- 在kubernetest中创建namespace叫做ns-monitor
创建文件名:namespace.yaml,内容如下:
【文件在百度云盘可下载链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6】
apiVersion: v1
kind: Namespace
metadata:
name: ns-monitor
labels:
name: ns-monitor
在文件目录处,执行创建命令如下:

kubectl apply -f namespace.yaml
- 在kubernetest中部署node-exporter,Node-exporter用于采集kubernetes集群中各个节点的物理指标,比如:Memory、CPU等。可以直接在每个物理节点是直接安装,这里我们使用DaemonSet部署到每个节点上,使用 hostNetwork: true 和 hostPID: true 使其获得Node的物理指标信息,配置tolerations使其在master节点也启动一个pod。
创建文件名:node-exporter.yaml文件,内容如下:
【文件在百度云盘可下载链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6】
kind: DaemonSet
apiVersion: apps/v1beta2
metadata:
labels:
app: node-exporter
name: node-exporter
namespace: ns-monitor
spec:
revisionHistoryLimit:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort:
protocol: TCP
name: http
hostNetwork: true
hostPID: true
tolerations:
- effect: NoSchedule
operator: Exists ---
kind: Service
apiVersion: v1
metadata:
labels:
app: node-exporter
name: node-exporter-service
namespace: ns-monitor
spec:
ports:
- name: http
port:
nodePort:
protocol: TCP
type: NodePort
selector:
app: node-exporter
在文件目录处,执行创建命令如下:
kubectl apply -f node-exporter.yaml
查看创建是否成功:

kubectl get pods -n ns-monitor -o wide
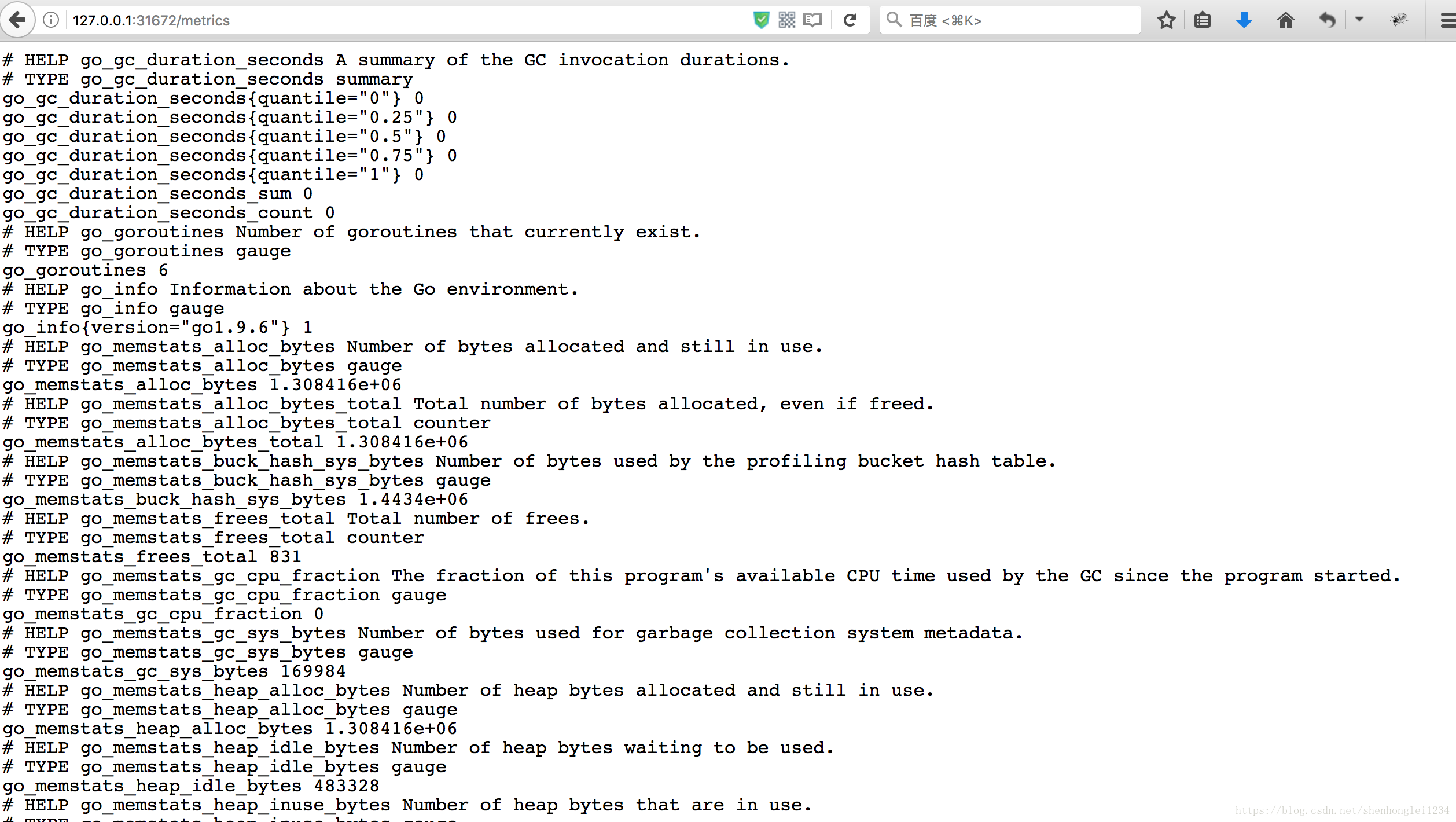
检验node-exporter是否都成功运行
http://127.0.0.1:31672/metrics或者http://127.0.0.1:9100/metrics
- 在kubernetest中部署Prometheus
官方参考文档:/etc/prometheus/prometheus.yaml的配置
创建文件名prometheus.yaml,内容如下:
【文件在百度云盘可下载链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6】
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs:
- get
- watch
- list
......为节省篇幅,此处省略,请在百度云盘下载
执行创建命令
kubectl apply -f prometheus.yaml
kubectl get pods -n ns-monitor -o wide
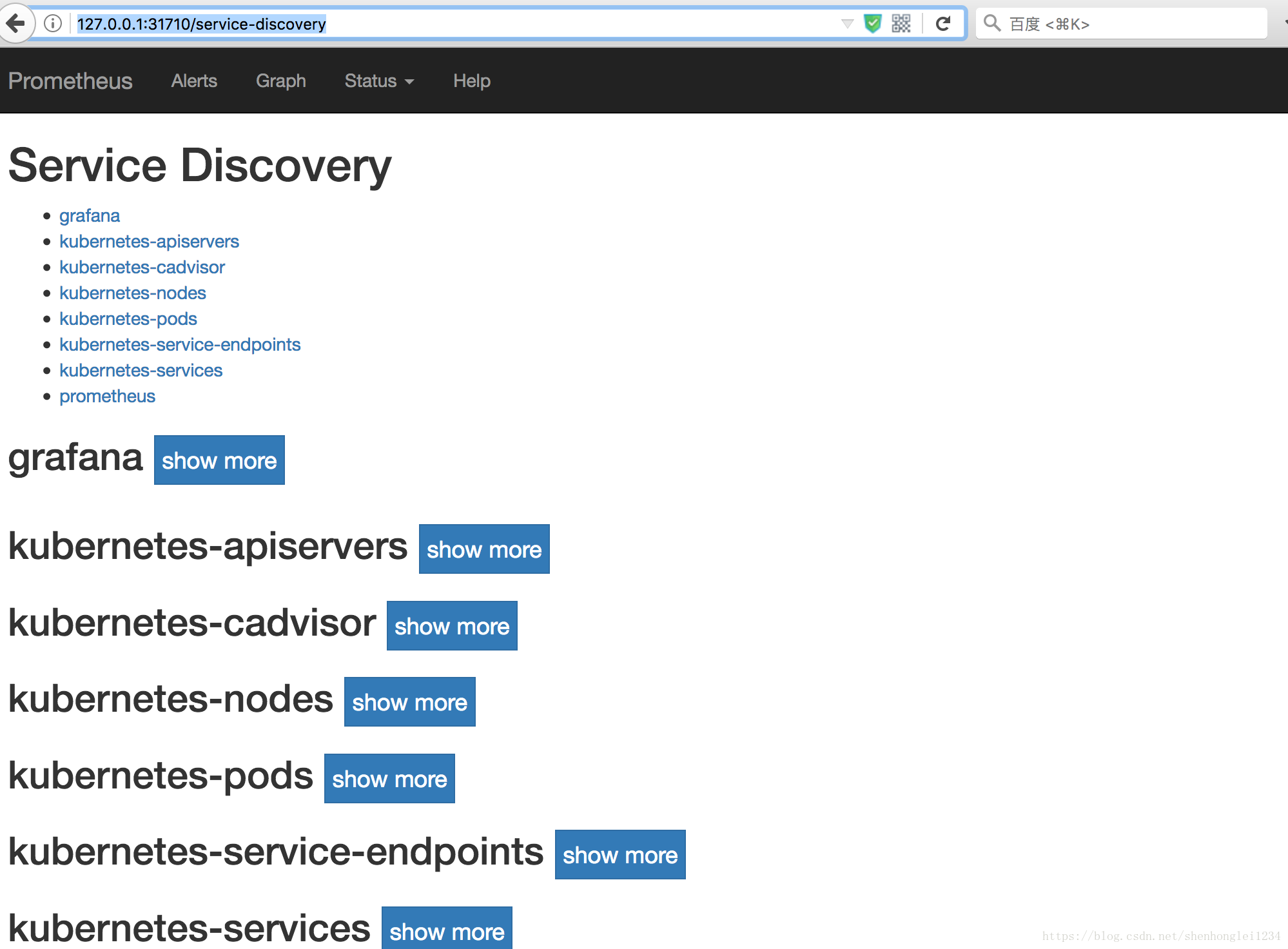
验证prometheus的正确性:http://127.0.0.1:31710/graph 或者 http://127.0.0.1:31710/service-discovery 或者 http://127.0.0.1:31710/targets

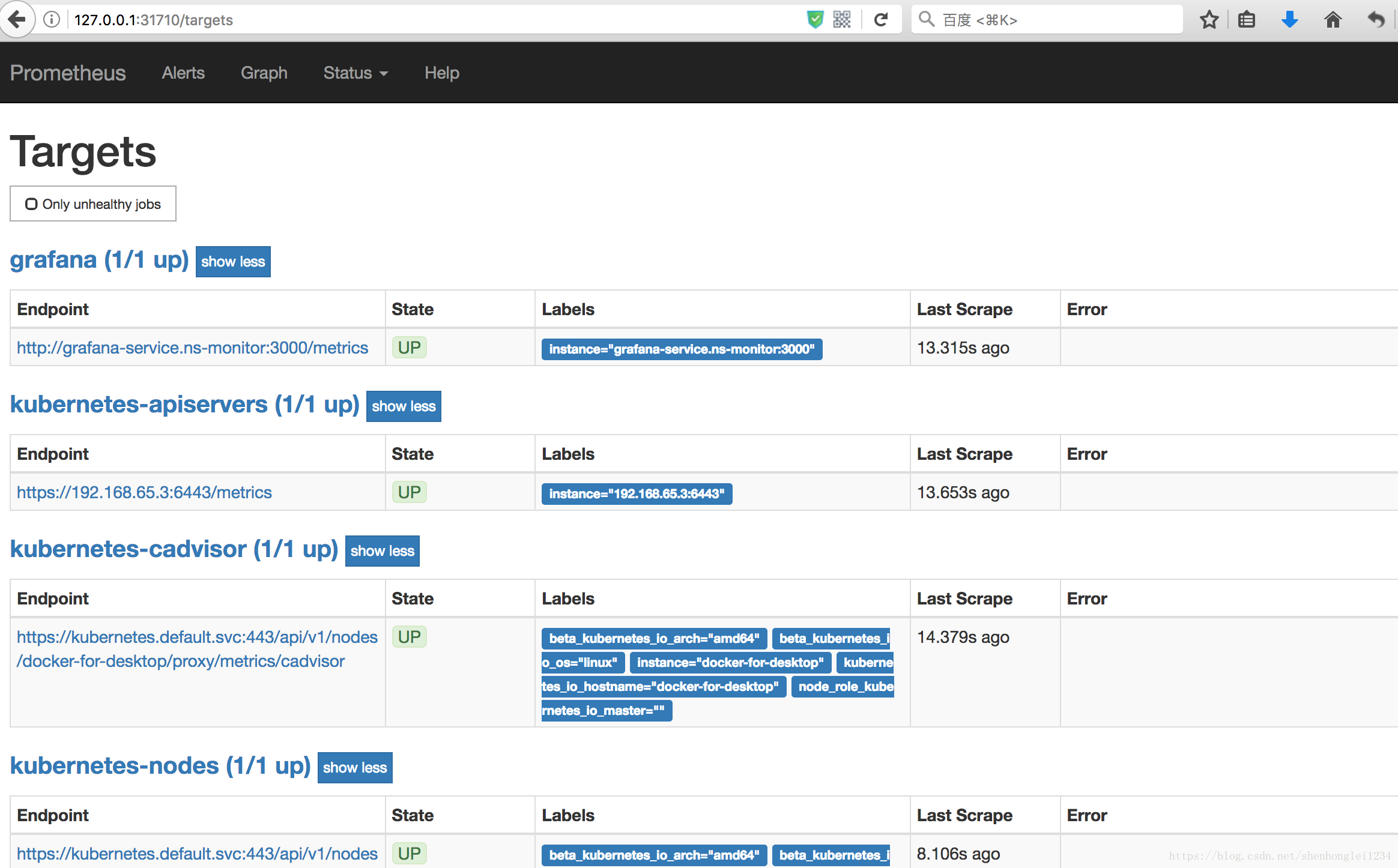
- 在kubernetest中部署grafana
创建grafana.yaml文件,内容如下:
【文件在百度云盘可下载链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6】
apiVersion: v1
kind: PersistentVolume
metadata:
name: "grafana-data-pv"
labels:
name: grafana-data-pv
release: stable
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /nfs/grafana/data
server: 192.168.65.3
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-data-pvc
namespace: ns-monitor
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
selector:
matchLabels:
name: grafana-data-pv
release: stable
---
kind: Deployment
apiVersion: apps/v1beta2
metadata:
labels:
app: grafana
name: grafana
namespace: ns-monitor
spec:
replicas:
revisionHistoryLimit:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:latest
env:
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
readinessProbe:
httpGet:
path: /login
port:
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-data-volume
ports:
- containerPort:
protocol: TCP
volumes:
- name: grafana-data-volume
persistentVolumeClaim:
claimName: grafana-data-pvc
---
kind: Service
apiVersion: v1
metadata:
labels:
app: grafana
name: grafana-service
namespace: ns-monitor
spec:
ports:
- port:
targetPort:
selector:
app: grafana
type: NodePort
执行创建命令、并查看
kubectl apply -f grafana.yaml
kubectl get pods -n ns-monitor -o wide
验证grafana是否成功运行:http://127.0.0.1:30591/login 默认用户名和密码:admin/admin

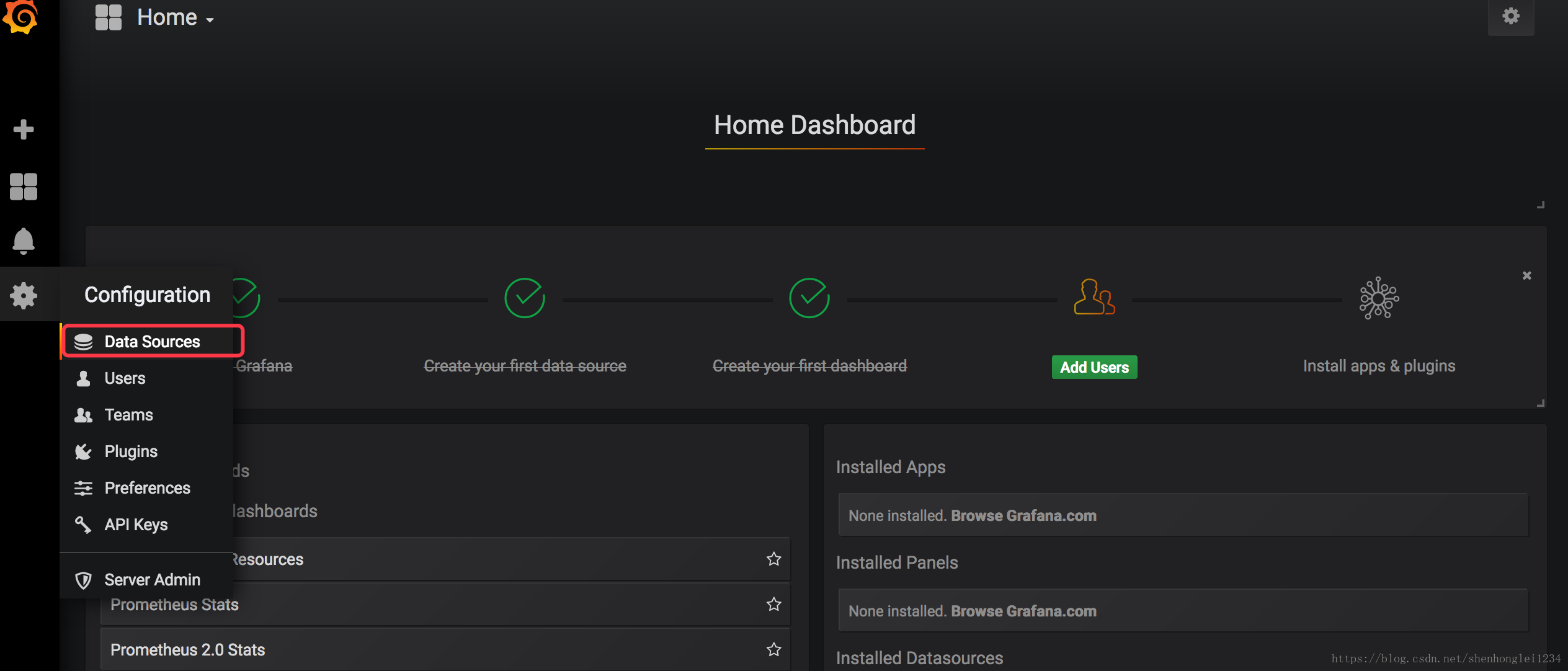
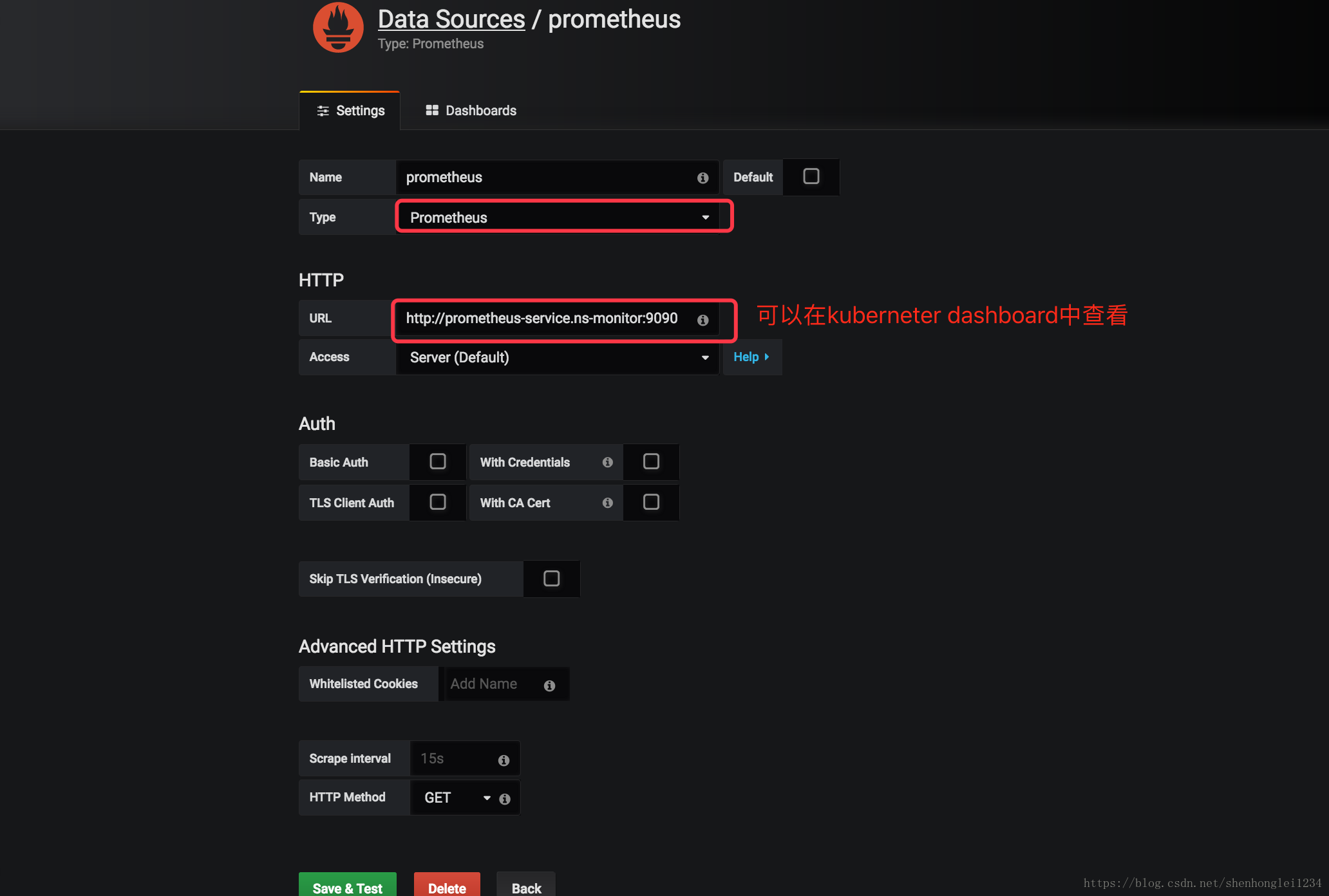
- 配置grafana:把prometheus配置成数据源
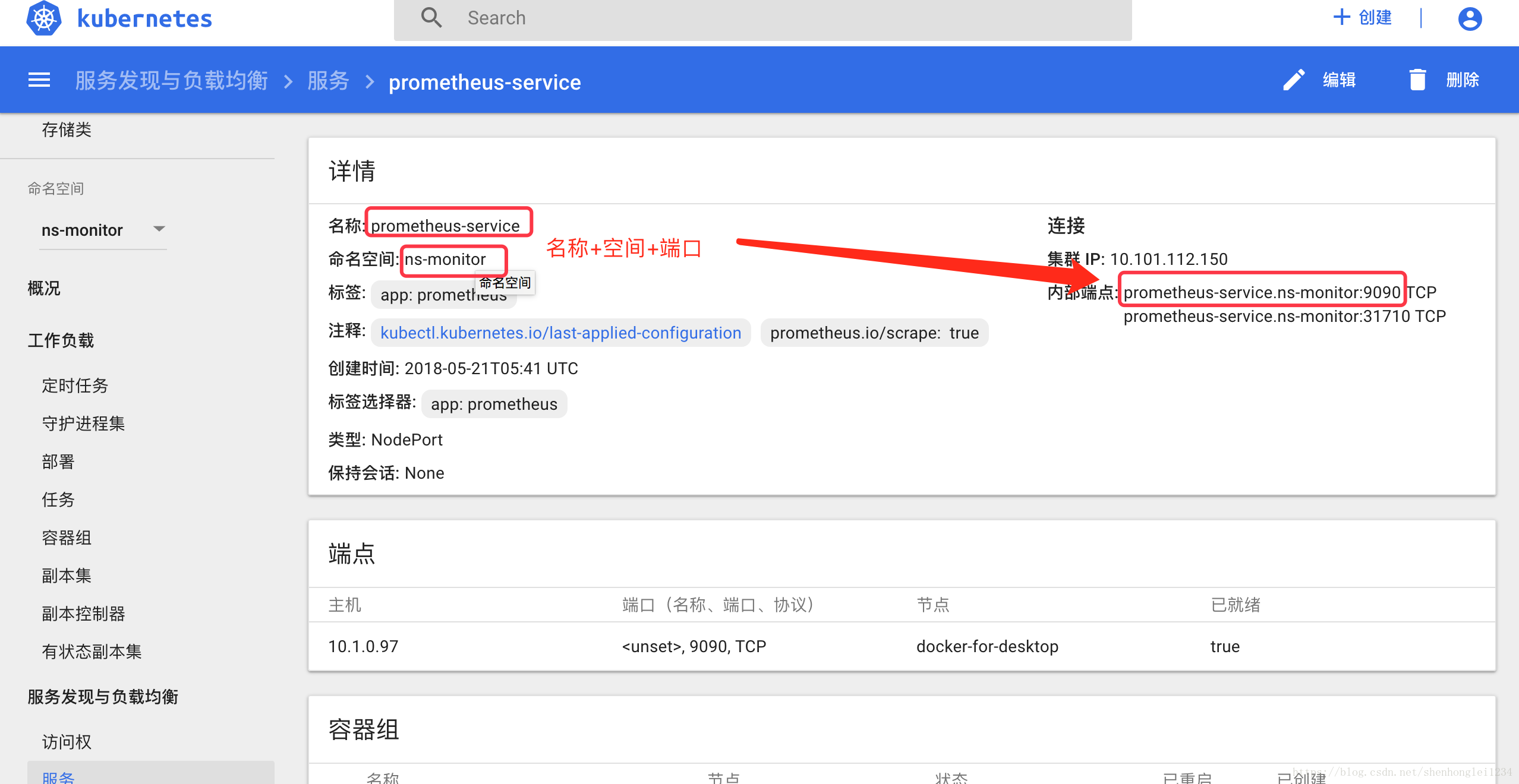
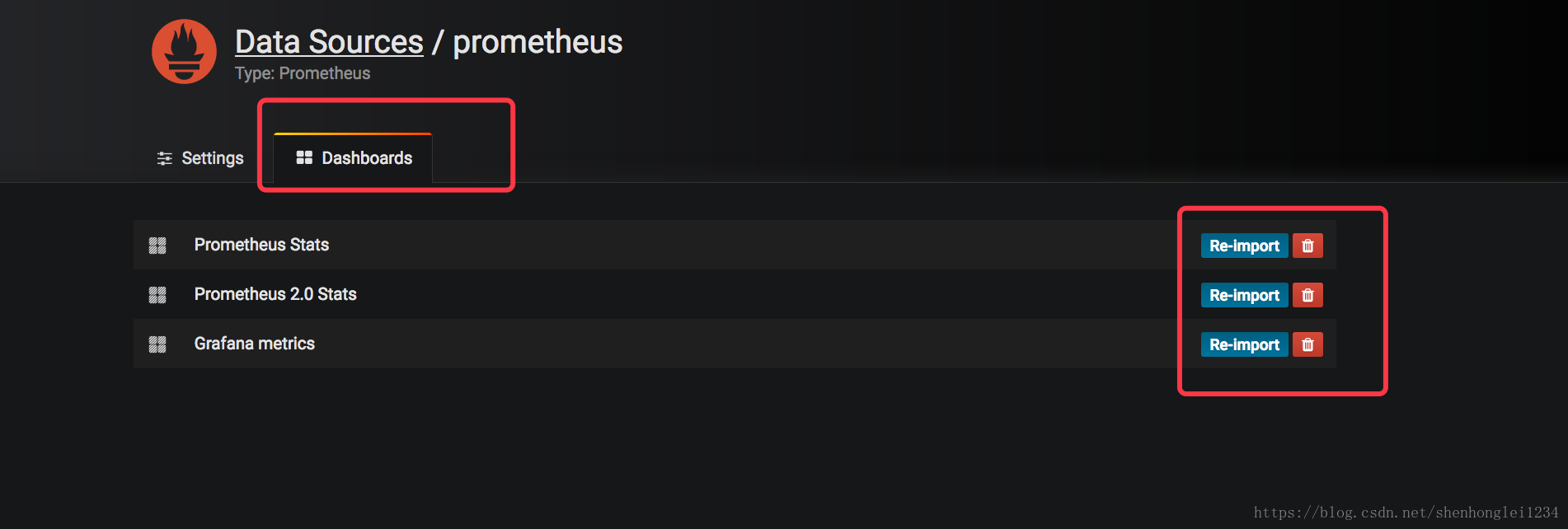
http://prometheus-service.ns-monitor:9090这个链接的来源: - 然后导入Dashboard
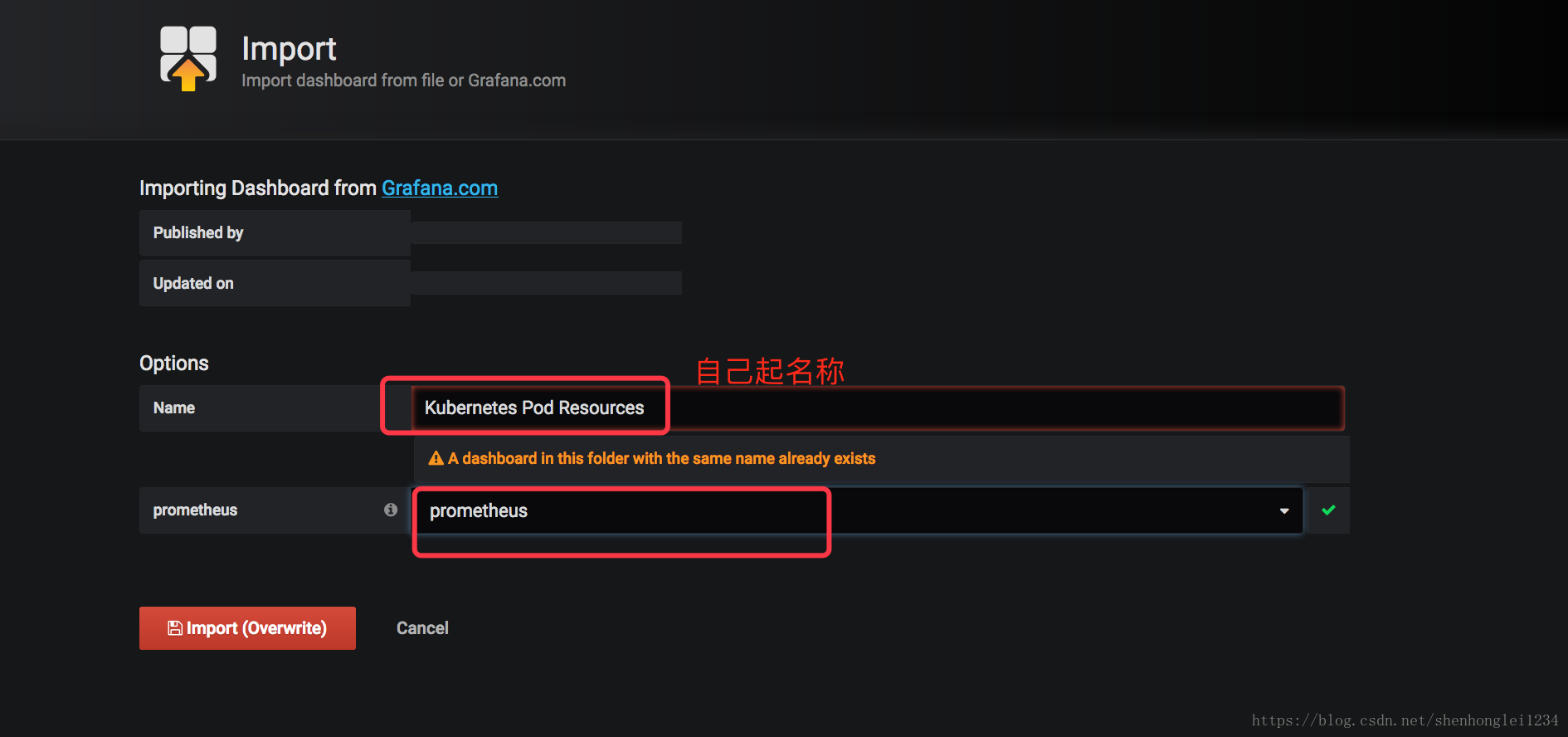
- 再把 kubernetes的Dashboard的模板导入进来显示:直接把JSON格式内容复制进来就行
【文件在百度云盘可下载链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6】
{
"__inputs": [
{
"name": "DS_PROMETHEUS",
"label": "prometheus",
"description": "",
"type": "datasource",
"pluginId": "prometheus",
"pluginName": "Prometheus"
}
],
"__requires": [
{
"type": "grafana",
"id": "grafana",
"name": "Grafana",
"version": "5.0.4"
},
......为节省篇幅,此处省略内容
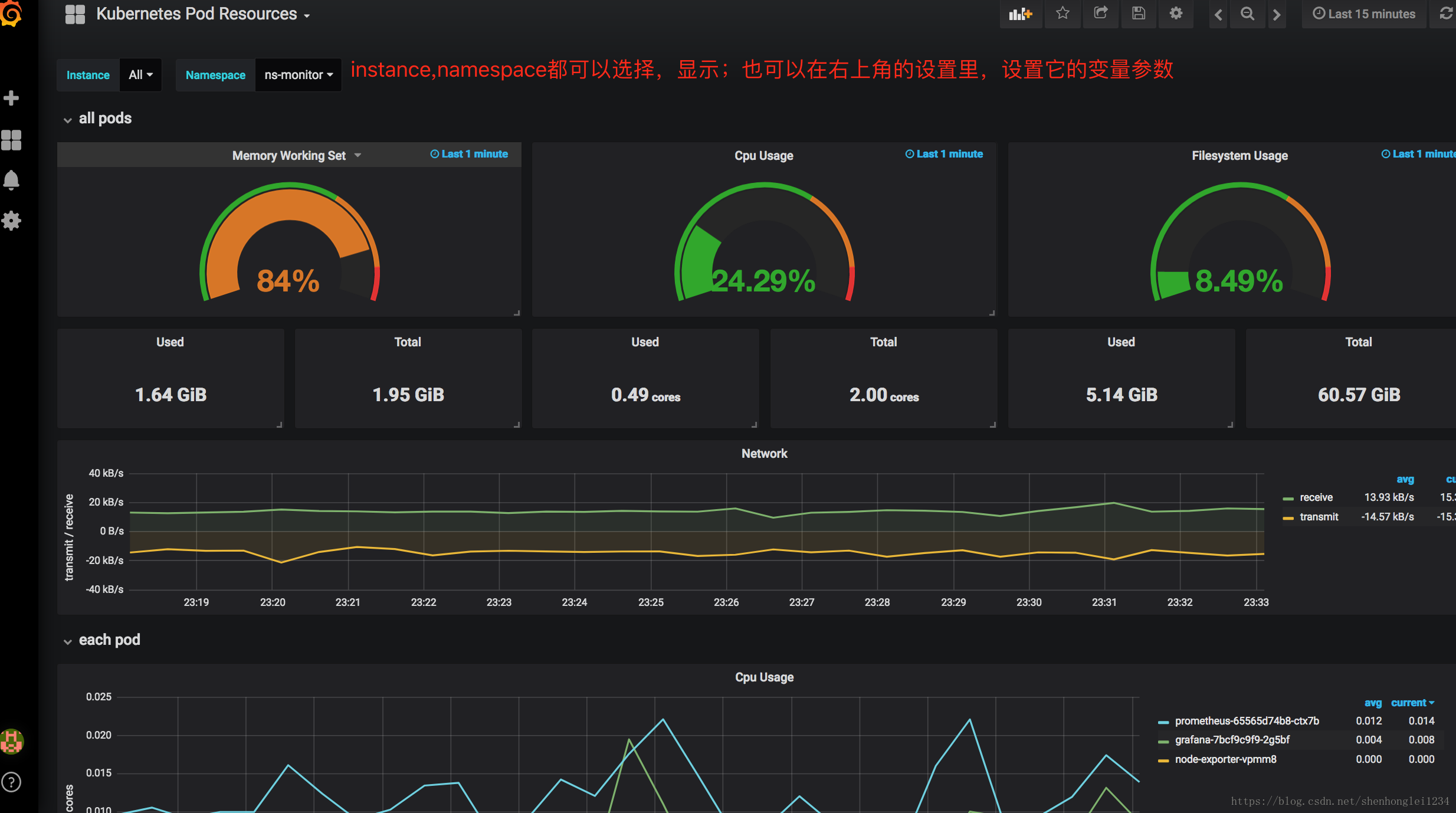
Dashboard中的每一个Panel可以自行编辑、保存和回滚!
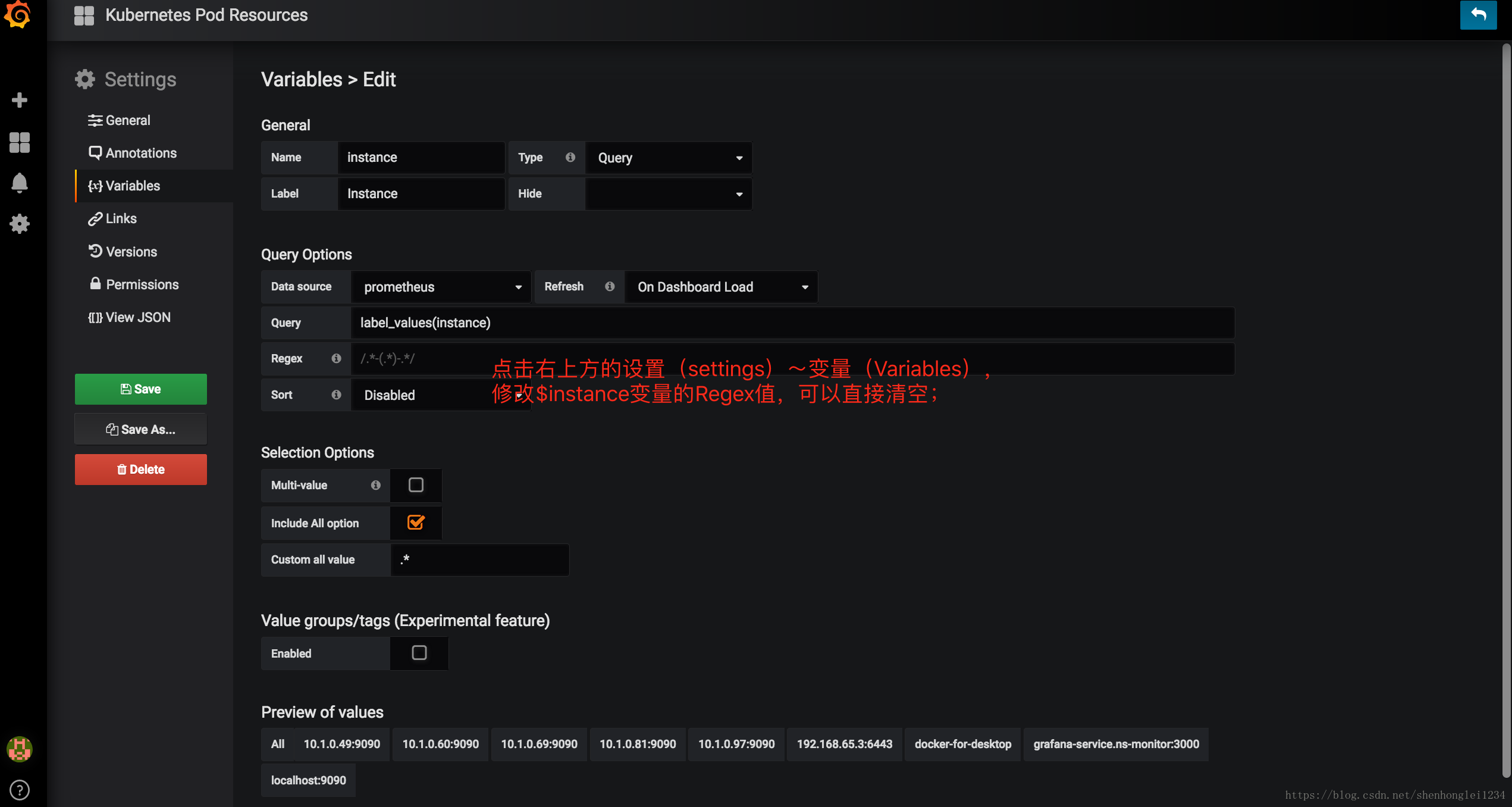
如果instance下拉框显示有问题,点击右上方的设置(settings)~变量(Variables),
修改$instance变量的Regex值,可以直接清空;
配置数据源、导入Dashboard、安装插件等这些操作可以配置到grafana.yaml文件中,
但是配置过程比较麻烦,这里先提供在界面上操作的说明,后期需要再处理。
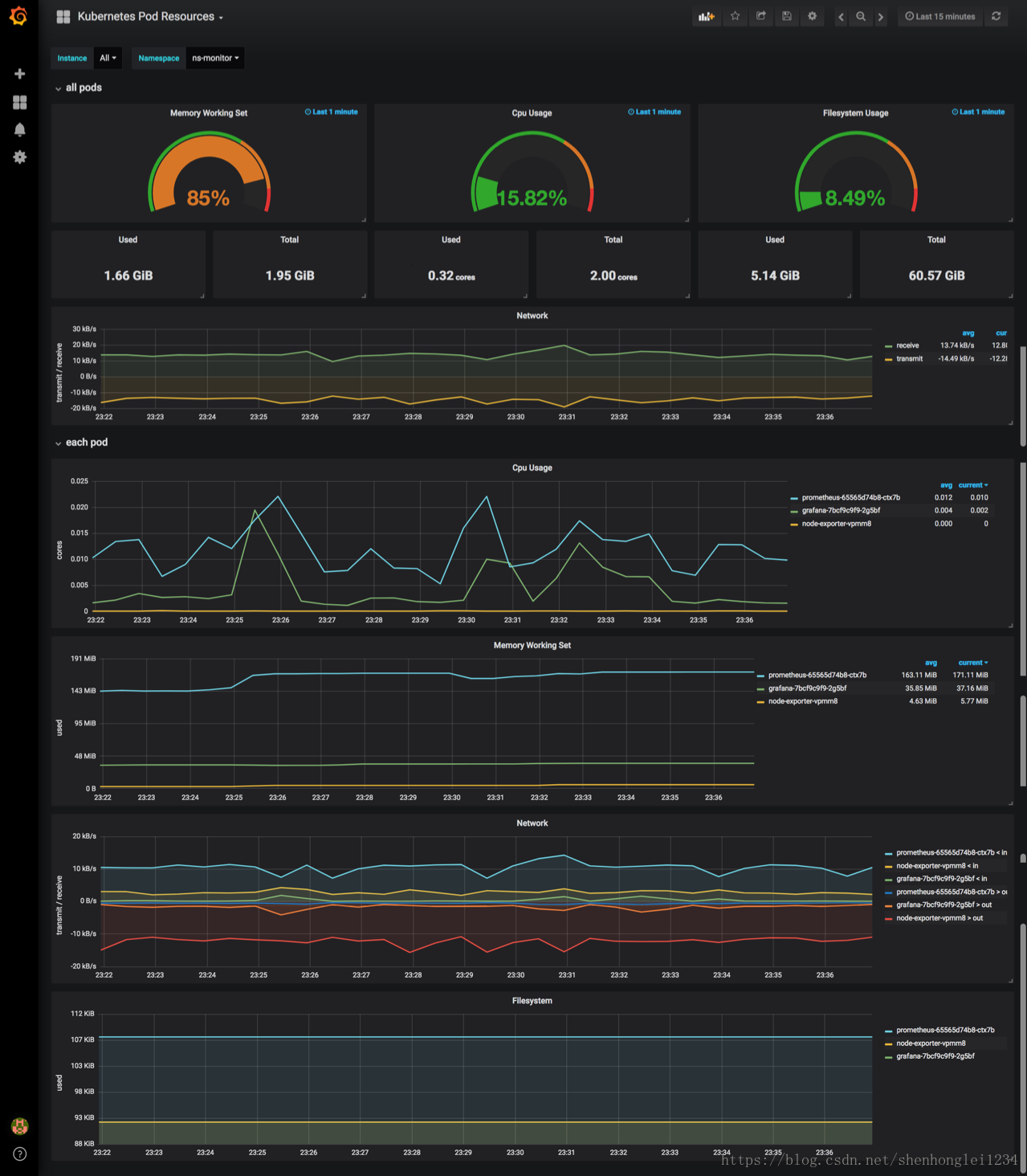
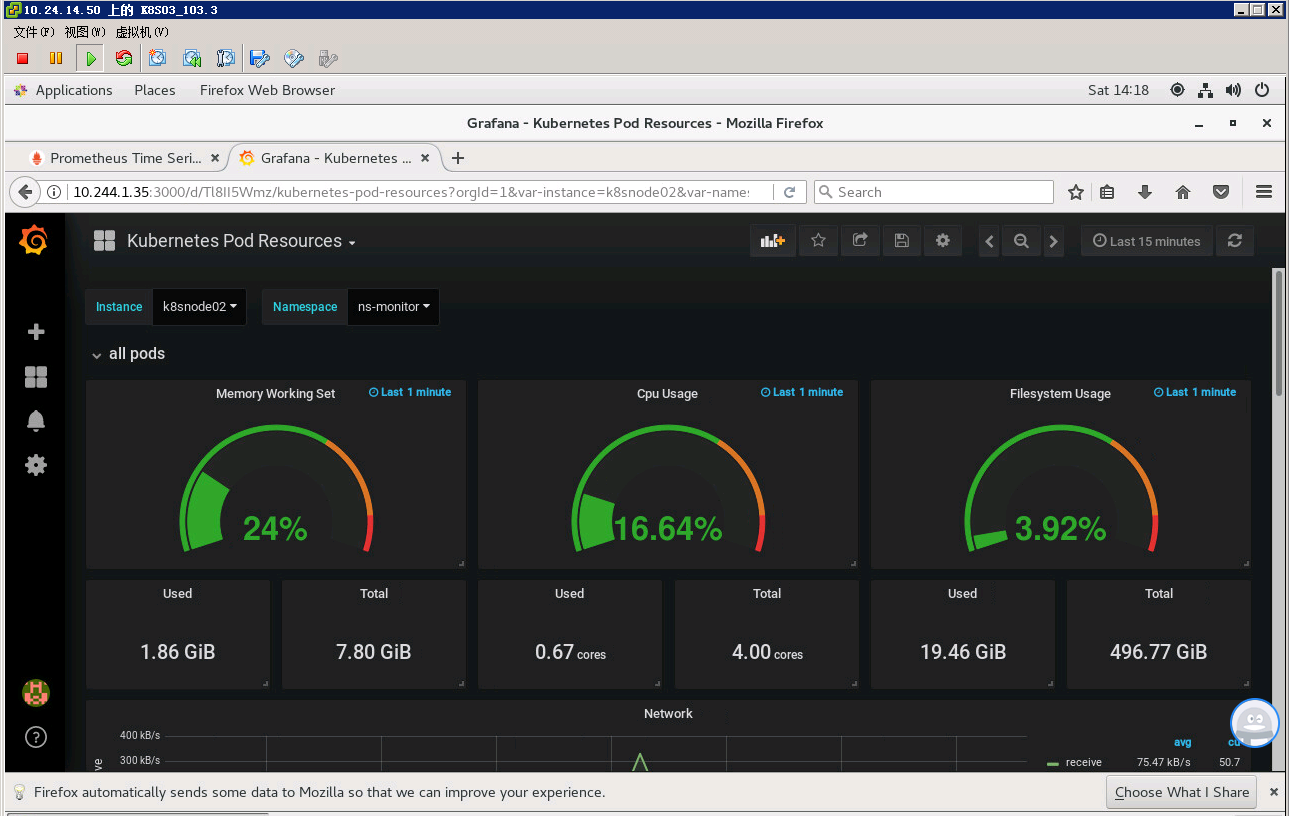
自己的环境监测信息
[转帖]Prometheus+Grafana监控Kubernetes的更多相关文章
- Prometheus+Grafana监控Kubernetes
涉及文件下载地址:链接:https://pan.baidu.com/s/18XHK7ex_J0rzTtfW-QA2eA 密码:0qn6 文件中需要下载的镜像需要自己提前下载好,eg:prom/node ...
- Rancher2.x 一键式部署 Prometheus + Grafana 监控 Kubernetes 集群
目录 1.Prometheus & Grafana 介绍 2.环境.软件准备 3.Rancher 2.x 应用商店 4.一键式部署 Prometheus 5.验证 Prometheus + G ...
- [转帖]安装prometheus+grafana监控mysql redis kubernetes等
安装prometheus+grafana监控mysql redis kubernetes等 https://www.cnblogs.com/sfnz/p/6566951.html plug 的模式进行 ...
- 使用 Prometheus + Grafana 对 Kubernetes 进行性能监控的实践
1 什么是 Kubernetes? Kubernetes 是 Google 开源的容器集群管理系统,其管理操作包括部署,调度和节点集群间扩展等. 如下图所示为目前 Kubernetes 的架构图,由 ...
- cAdvisor+Prometheus+Grafana监控docker
cAdvisor+Prometheus+Grafana监控docker 一.cAdvisor(需要监控的主机都要安装) 官方地址:https://github.com/google/cadvisor ...
- Prometheus Operator 监控Kubernetes
Prometheus Operator 监控Kubernetes 1. Prometheus的基本架构 Prometheus是一个开源的完整监控解决方案,涵盖数据采集.查询.告警.展示整个监控流程 ...
- 【Springboot】用Prometheus+Grafana监控Springboot应用
1 简介 项目越做越发觉得,任何一个系统上线,运维监控都太重要了.关于Springboot微服务的监控,之前写过[Springboot]用Springboot Admin监控你的微服务应用,这个方案可 ...
- Prometheus + Grafana 监控系统搭
本文主要介绍基于Prometheus + Grafana 监控Linux服务器. 一.Prometheus 概述(略) 与其他监控系统对比 1 Prometheus vs. Zabbix Zabbix ...
- 部署Prometheus+Grafana监控
Prometheus 1.不是很友好,各种配置都手写 2.对docker和k8s监控有成熟解决方案 Prometheus(普罗米修斯) 是一个最初在SoudCloud上构建的监控系统,开源项目,拥有非 ...
随机推荐
- JAVA 框架hibernate (三)(数据库更新丢失)
一.场景: 我们在并发操作数据库同一个字段,比如:name:tom age:22这条数据.有2个同时进行操作.A操作该数据的name改成admin,B操作这条数据的age改成:35.然后A先把数据更 ...
- HDU 1285 经典拓扑排序入门题
确定比赛名次 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- php 操作时间、日期类函数
<?php // time() echo "time(): ",time(); echo "\n"; // strtotime() echo " ...
- always on 集群
准备工作 1. 四台已安装windows server 2008 r2 系统的虚拟机,配置如下: CPU : 1核 MEMORY : 2GB DISK : 40GB(未分区) NetAdapter ...
- 1.3《想成为黑客,不知道这些命令行可不行》(Learn Enough Command Line to Be Dangerous)——手册页
我们运行的命令行程序,通常在技术上称作shell, 它包含了一个非常强大(也很神秘)的工具,我们将用它来学习更多可用的命令.这个工具本身就是个称作'man'的命令('manual'的简写).它的参数是 ...
- 20155339 Exp4 恶意代码分析
20155339 Exp4 恶意代码分析 实验后回答问题 (1)如果在工作中怀疑一台主机上有恶意代码,但只是猜想,所有想监控下系统一天天的到底在干些什么.请设计下你想监控的操作有哪些,用什么方法来监控 ...
- 12、JAVA内存模型与线程
一.JMM 有序性,可见性,原子性 synchorize :3个性都有: volatile:保证可见性+禁止指令重排: 二.线程的五种状态 面向过程与面向对象的差别 面向过程:站在计算机的角度分析和解 ...
- 利用Python统计微信联系人男女比例以及简单的地区分布
寒暄的话不多说,直接进入主题. 运行效果图: [准备环境] Python版本:v3.5及其以上 开发工具:随意,此处使用Pycharm [依赖包] 1.itchat (CMD运行:pip instal ...
- 蓝牙inquiry流程之Inquiry Complete处理
inquiry流程一般持续有12s多,当inquiry完成的时候,设备端会上报一个Event: Inquiry Complete 上来,那协议栈是如何把这个事件上传到应用层的呢?本篇文章来分析一下其具 ...
- [BZOJ4857][JSOI2016]反质数序列[最大点独立集]
题意 在长度为 \(n\) 的序列 \(a\) 中选择尽量长的子序列,使得选出子序列中任意两个数的和不为质数. \(n\leq3000\ ,a_i\leq10^5\). 分析 直接按照奇偶性建立二分图 ...