035 spark与hive的集成
一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)
将hive-site.xml拷贝到${SPARK_HOME}/conf下。
下面使用软连接:

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别:
1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
但是,需要将连接数据库的驱动添加到Spark应用的classpath中
2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
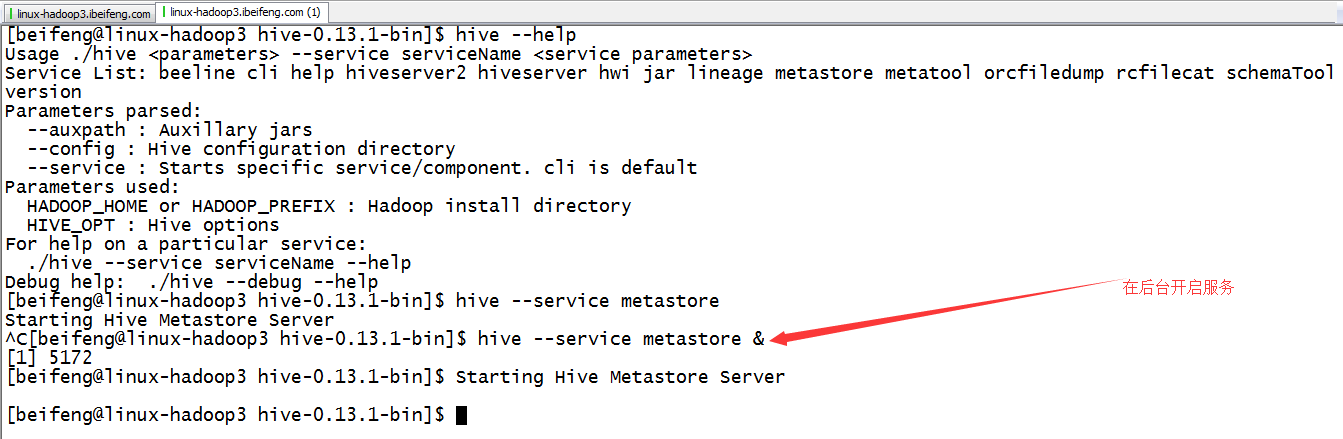
直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式
配置hive.metastore.uris的方式。

4.启动hive service metastore服务
如果没有配置全局hive,就使用bin/hive --service metastore &
三:测试
1.spark-sql
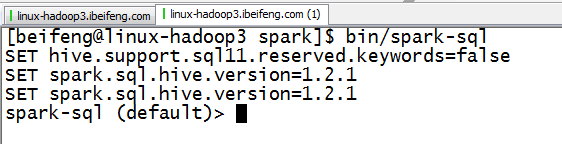
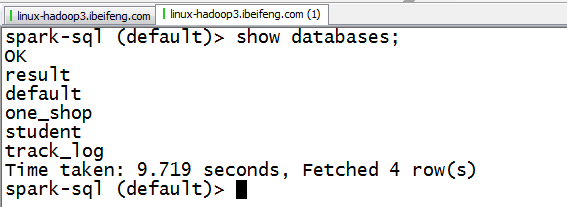
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache
cache是立即执行的,然后使用下面的可以懒加载。
uncache是立即执行的。

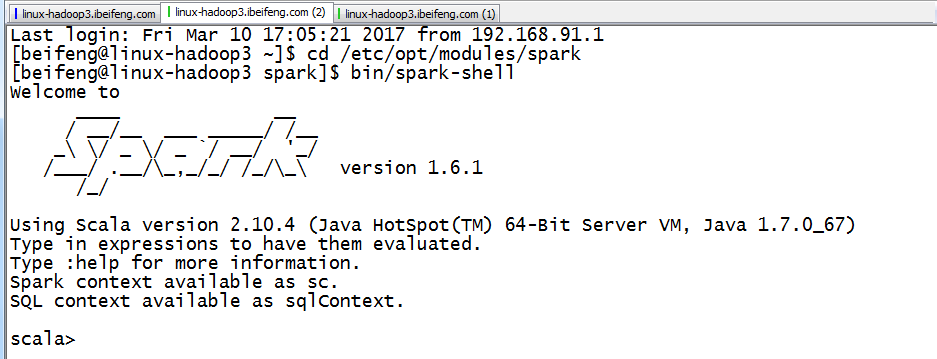
五:使用spark-shell
1.启动
2.使用
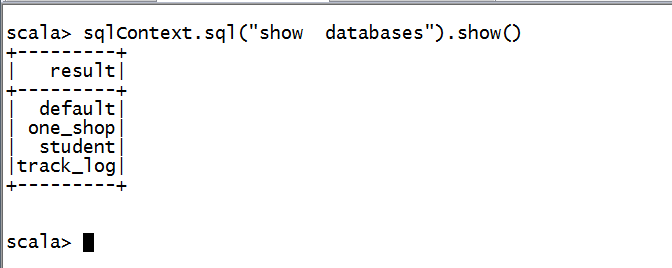
可以使用sqlContext . ,然后使用Tab进行补全。
show默认显示20行。
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件,而且jar包不是太多
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
方式:
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar:这样就不再需要配置hive.metastore.uris参数配置。
使用“,”分隔多个jar。
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
作用:
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version. 这一个说明是spark-submit后的package参数的说明。
方式:
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
下载路径:
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中,即是home/beifeng/.ivy/jars
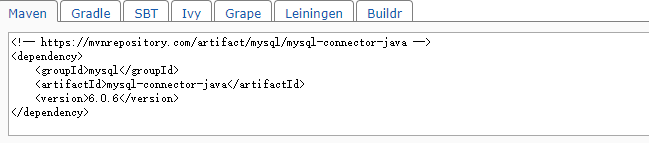
根据上面的maven来写格式。
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
035 spark与hive的集成的更多相关文章
- spark与hive的集成
一:介绍 1.在spark编译时支持hive 2.默认的db 当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库. ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 使用spark访问hive错误记录
在spark集群中执行./spark-shell时报以下错误: 18/07/23 10:02:39 WARN DataNucleus.Connection: BoneCP specified but ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark SQL -- Hive
使用Saprk SQL 操作Hive的数据 前提准备: 1.启动Hdfs,hive的数据存储在hdfs中; 2.启动hive -service metastore,元数据存储在远端,可以远程访问; 3 ...
随机推荐
- 【BZOJ1089】[SCOI2003]严格n元树(高精度,动态规划)
[BZOJ1089][SCOI2003]严格n元树(高精度,动态规划) 题面 BZOJ 洛谷 题解 设\(f[i]\)表示深度为\(i\)的\(n\)元树个数.然后我们每次加入一个根节点,然后枚举它的 ...
- 51nod1229 序列求和 V2 【数学】
题目链接 B51nod1229 题解 我们要求 \[\sum\limits_{i = 1}^{n}i^{k}r^{i}\] 如果\(r = 1\),就是自然数幂求和,上伯努利数即可\(O(k^2)\) ...
- 【洛谷P1828】香甜的黄油
题目大意:给定 N 个点,M 条边的无向图,在其中选定 P 个点,每个点可能被选多次,求图中的一个点到选定的 P 个点的距离的值最小是多少. 题解:由于数据范围的限制,直接 Floyd 会超时,因此对 ...
- ThinkPHP5项目目录
ThinkPHP5安装后(或者下载后的压缩文件解压后)可以看到下面的目录结构: tp5├─application 应用目录 ├─extend 扩展类库目录(可定义) ├─pu ...
- ubuntu下sublime Text3配置C++编译环境
今天在Ubuntu下用sublime Text3编译C++代码,环境配的不太顺利,下边展示一个实例. 1.主函数main.cpp #include <iostream> #include ...
- Java基础-原码反码补码
Java基础-原码反码补码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 注意,我们这里举列的原码和反码只是为了求负数的补码,在计算机中没有原码,反码的存在,只有补码. 一.原码 ...
- 比特币全节点(bitcoind) eth 全节点
运行全节点的用途: 1.挖矿 2.钱包 运行全节点,可以做关于btc的任何事情,例如创建钱包地址.管理钱包地址.发送交易.查询全网的交易信息等等 选个节点钱包:bitcoind 1.配置文件: ...
- Codeforces 314 E. Sereja and Squares
http://codeforces.com/contest/314/problem/E 题意: 原本有一个合法的括号序列 擦去了所有的右括号和部分左括号 问有多少种填括号的方式使他仍然是合法的括号序列 ...
- 贪心算法: Codevs 1052 地鼠游戏
#include <iostream> #include <algorithm> #include <queue> #include <cstring> ...
- 那些年实用但被我忘掉javascript属性.onresize
//获取屏幕宽度并动态赋值 var winWidth = 0; var winHeight = 0; function findDimensions() //函数:获取尺寸 { //获取窗口宽度 if ...