spark与hive的集成
一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别为(区别):
-1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
--1.1 需要将连接数据库的驱动添加到Spark应用的classpath中
-2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
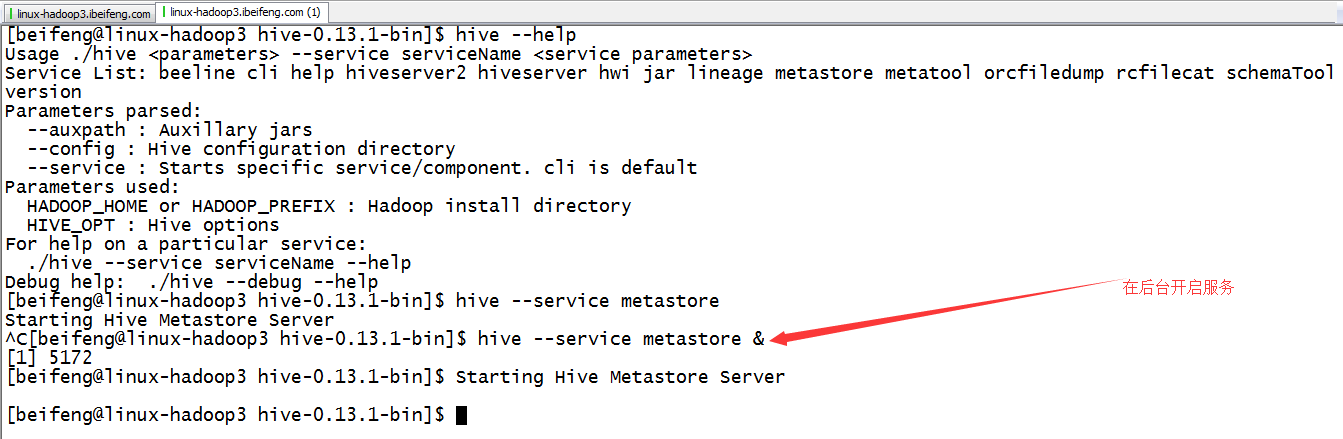
--2.1 直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式

4.启动hive service metastore服务
三:测试
1.spark-sql
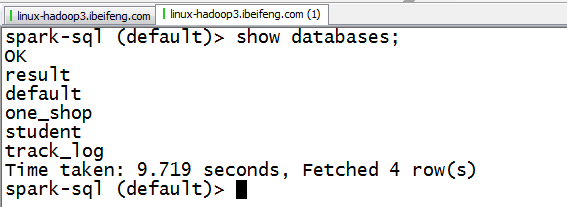
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache

五:使用spark-shell
1.启动
2.使用
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version.
http://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.27
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
备注:如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:
spark与hive的集成的更多相关文章
- 035 spark与hive的集成
一:介绍 1.在spark编译时支持hive 2.默认的db 当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库. ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 使用spark访问hive错误记录
在spark集群中执行./spark-shell时报以下错误: 18/07/23 10:02:39 WARN DataNucleus.Connection: BoneCP specified but ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark SQL -- Hive
使用Saprk SQL 操作Hive的数据 前提准备: 1.启动Hdfs,hive的数据存储在hdfs中; 2.启动hive -service metastore,元数据存储在远端,可以远程访问; 3 ...
随机推荐
- python基础教程(八)
创建自已的对象(类)是python非常核心的概念,事实上,python被称为面向对象语言,本章会介绍如何创建对象.以及面向对象的概念:继承.封装.多态. 多态: 可对不同类的对象使用同样的操作. 封装 ...
- JDBCTemplate
1.Spring提供的一个操作数据库的技术JdbcTemplate,是对Jdbc的封装.语法风格非常接近DBUtils. JdbcTemplate可以直接操作数据库,加快效率,而且学这个JdbcTem ...
- 认清Javascript的地位并编写合理的Javascript代码
作为前端程序员,一定要认清javascript的地位,不要被它乱七八糟的特点所迷惑.JavaScript主要是用来操控和重新调整DOM,通过修改DOM结构,从而达到修改页面效果的目的. 要用这个中心思 ...
- ThreadLoacl的反思
在我的随笔 spring mvc:注解@ModelAttribue妙用 中使用ThreadLocal来简化spring mvc控制层controller中的ModelMap,Response.Jso ...
- 【grunt】两小时入门
目录: 1. 用途和场景 2.Grunt插件 3.相关资源 4.环境安装 5.开始学习 5.1 一个新项目 5.2 生成package.json 5.3 在项目中安装grunt和相关插件 5.4 Gr ...
- django 5 form1
---------------------Form表单验证(用户请求验证+生成HTML标签) 示例:用户管理 a. 添加用户页面 - 显示HTML标签 - 提交:数据验证 - 成功之后保存 - 错误显 ...
- makefile中":=","=","?=","+=" 之间的区别
区别: := 有关位置的等于,值取决于当时位置的值 = 无关位置的等于,值永远等于最后的值 ?= 是如果没有被赋值过就赋予等号后面的值+= 是添加等号后面的值 '=':无关位置的等于 比如: x = ...
- 协处理器CP15介绍—MCR/MRC指令(6)
概述:在基于ARM的嵌入式应用系统中,存储系统的操作通常是由协处理器CP15完成的.CP15包含16个32位的寄存器,其编号为0-15. 而访问CP15寄存器的指令主要是MCR和MRC这两个指令. 例 ...
- §--------算法分界线--------§
如题 As said in the title~ 计算机的cpu计算从根源上由最基本的逻辑电路(晶体管)组成,由此衍生出最基本的数值运算:四则运算.而此后所有的高级算法都是建立在这个基本计算原理(逻辑 ...
- 【Java并发编程】之六:Runnable和Thread实现多线程的区别(含代码)
转载请注明出处:http://blog.csdn.net/ns_code/article/details/17161237 Java中实现多线程有两种方法:继承Thread类.实现Runnable接口 ...