035 spark与hive的集成
一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)
将hive-site.xml拷贝到${SPARK_HOME}/conf下。
下面使用软连接:

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别:
1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
但是,需要将连接数据库的驱动添加到Spark应用的classpath中
2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
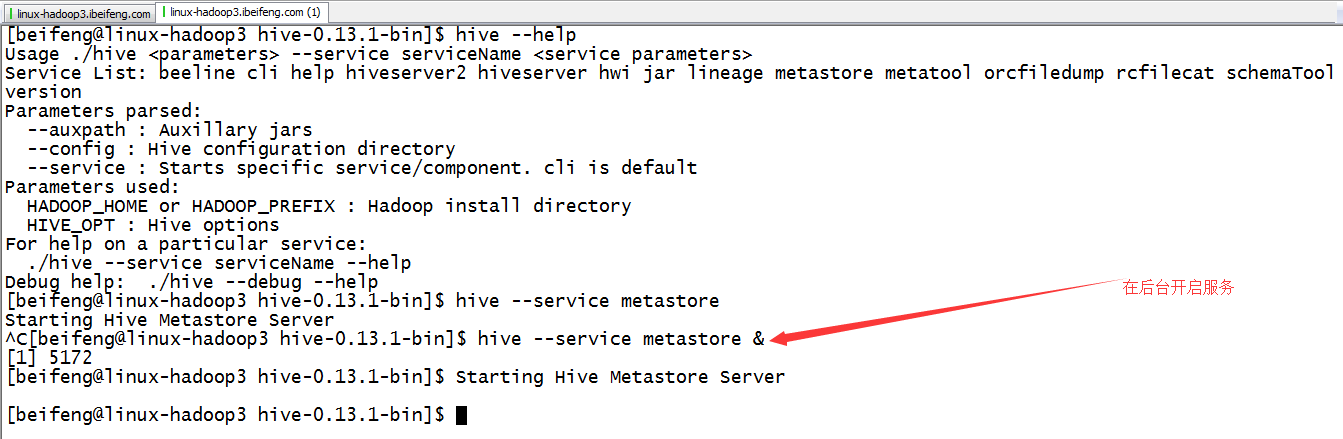
直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式
配置hive.metastore.uris的方式。

4.启动hive service metastore服务
如果没有配置全局hive,就使用bin/hive --service metastore &
三:测试
1.spark-sql
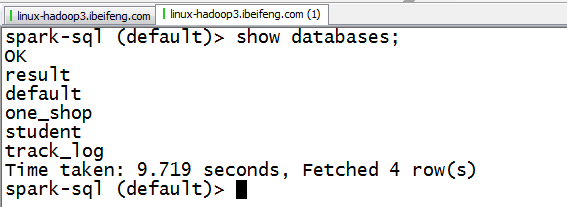
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache
cache是立即执行的,然后使用下面的可以懒加载。
uncache是立即执行的。

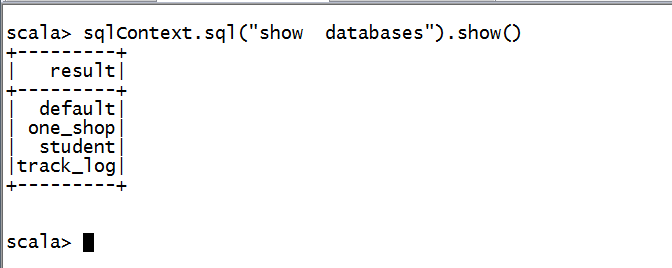
五:使用spark-shell
1.启动
2.使用
可以使用sqlContext . ,然后使用Tab进行补全。
show默认显示20行。
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件,而且jar包不是太多
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
方式:
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar:这样就不再需要配置hive.metastore.uris参数配置。
使用“,”分隔多个jar。
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
作用:
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version. 这一个说明是spark-submit后的package参数的说明。
方式:
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
下载路径:
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中,即是home/beifeng/.ivy/jars
根据上面的maven来写格式。
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
035 spark与hive的集成的更多相关文章
- spark与hive的集成
一:介绍 1.在spark编译时支持hive 2.默认的db 当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库. ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 使用spark访问hive错误记录
在spark集群中执行./spark-shell时报以下错误: 18/07/23 10:02:39 WARN DataNucleus.Connection: BoneCP specified but ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark SQL -- Hive
使用Saprk SQL 操作Hive的数据 前提准备: 1.启动Hdfs,hive的数据存储在hdfs中; 2.启动hive -service metastore,元数据存储在远端,可以远程访问; 3 ...
随机推荐
- NOI.AC 20181103 题解
CF 1037B Reach Median 班上 n个同学(n 是奇数)排成一排站队,为了美观,需要大家高度的中位数是 x. 你可以让同学们在脚下垫木板或者稍微蹲一点来达成这个目标.对任意一位同学的 ...
- 【小记】FreeRTOS任务创建后但任务中为空时运行错误
FreeRTOS任务创建后但任务中无语句为空时运行错误 会死在文件<port.c>中下边函数处 static void prvTaskExitError( void ){ /* A fun ...
- 学习4__STM32--中断
Cortex-M处理器的NVIC接收中断请求各种源 > 从图中可看出,NVIC是一个外设中断的管理器,简化core的工作,控制着整个芯片的中断功能 > NVIC负责给外设中断分配优先级,使 ...
- Hello,Power BI
Power BI 是什么 Power BI 是一套业务分析工具,用于分析数据和理解数据,快速便捷地监控数据变化,为商务决策提供依据. Power BI 有用户组的概念.分享权限等概念 Power BI ...
- 螺旋队列和hiho1525逃离迷宫3
我是真调不出错误了! hiho1525逃离迷宫3 #include <stdio.h> #include <stdlib.h> #include <math.h> ...
- Linux系统上查找已安装软件的路径
在Linux系统上查找已安装软件路径的命令,以查找pcre的安装路径为例: [root@localhost doc]# rpm -ql pcre /lib64/libpcre.so. /lib64/l ...
- NameError: name 'reload' is not defined
对于 Python 2.X: import sys reload(sys) sys.setdefaultencoding("utf-8") 对于 <= Python 3.3: ...
- 实现vue2.0响应式的基本思路
最近看了vue2.0源码关于响应式的实现,以下博文将通过简单的代码还原vue2.0关于响应式的实现思路. 注意,这里只是实现思路的还原,对于里面各种细节的实现,比如说数组里面数据的操作的监听,以及对象 ...
- WebSockets Tutorial(教程一)WebSockets简介
一.WebSockets简介 以字面意思来说,握手可以被定义为两个人抓住和握手右手,象征着问候,祝贺,同意或告别.在计算机科学中,握手是确保服务器与客户端同步的过程.握手是Web Socket协议的基 ...
- 《Linux命令行与shell脚本编程大全》第十一章 构建基本脚本
11.1使用多个命令 $date;who // 命令列表,加入分号就可以,这样会依次执行.参见5.2.1节 注意区分$(date;who),这个是进程列表,会生成一个子shell来执行 Shel ...