Python-多线程之消费者模式和GIL全局锁
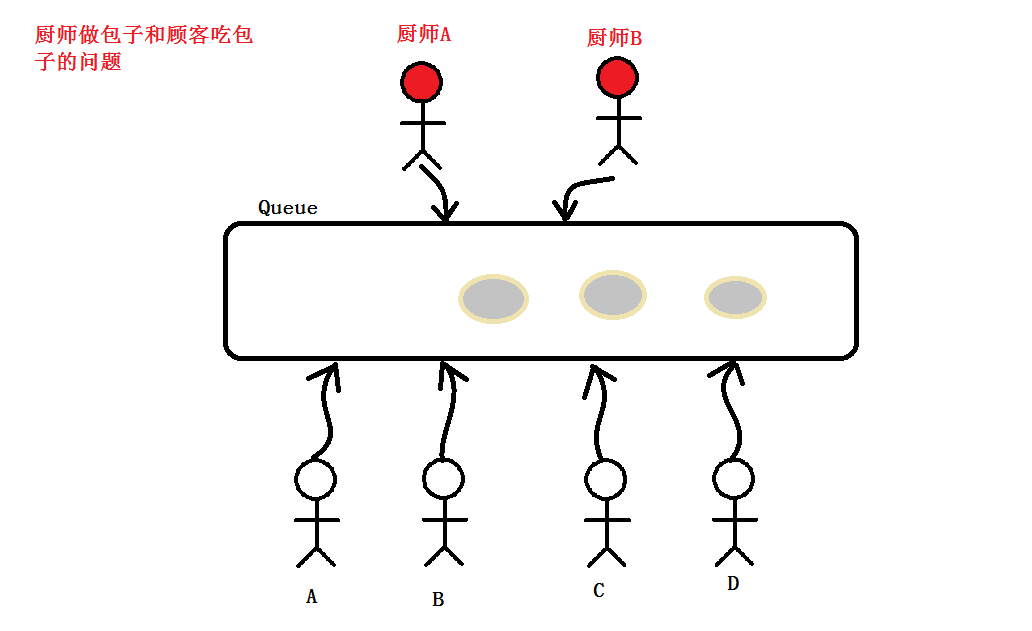
# 一对多 一个大厨对多个顾客 import threading
import queue
import time q = queue.Queue(maxsize=10) #生产者
def producer(name):
count = 1
while True:
q.put("包子%d"%count)
print("生产了包子%d"%count)
count += 1
time.sleep(0.8) #消费者
def consumer(name):
count = 1
while True:
print("[%s]取到了[%s]并且吃了它。。。"%(name,q.get()))
time.sleep(2) if __name__ == '__main__':
p = threading.Thread(target=producer,args=("刘大厨",))
a = threading.Thread(target=consumer,args=("A",))
b = threading.Thread(target=consumer,args=("B",)) p.start()
a.start()
b.start()
# 多对多 多个大厨对多个顾客 import threading
import queue
import time,random
q = queue.Queue(maxsize=10)
count = 1
#生产者
def producer(name):
global count
while True: # if mutex.acquire():
# q.put("包子%d"%count)
# print("%s生产了包子%d"%(name,count))
# count += 1
# time.sleep(random.random()*10)
# mutex.release()
q.put("包子%d" % count)
print("%s生产了包子%d" % (name, count))
count += 1
time.sleep(random.random() * 10) #消费者
def consumer(name):
count = 1
while True:
print("[%s]取到了[%s]并且吃了它。。。"%(name,q.get()))
time.sleep(random.random() * 10) if __name__ == '__main__': mutex = threading.Lock() p1 = threading.Thread(target=producer,args=("刘大厨",))
p2 = threading.Thread(target=producer,args=("李大厨",)) a = threading.Thread(target=consumer,args=("A",))
b = threading.Thread(target=consumer,args=("B",))
c = threading.Thread(target=consumer,args=("C",))
d = threading.Thread(target=consumer,args=("D",)) p1.start()
p2.start()
a.start()
b.start()
c.start()
d.start()
from threading import Thread
from multiprocessing import Process import time
#计数
def two_hundred_million():
start_time = time.time()
i = 0
for _ in range(200000000):
i = i + 1
end_time = time.time()
print("Total time:{}".format(end_time - start_time)) #数1亿
def one_hundred_million():
start_time = time.time()
i = 0
for _ in range(100000000):
i = i + 1
end_time = time.time()
print("Total time:{}".format(end_time - start_time)) if __name__ == "__main__":
#单线程---主线程
#two_hundred_million() #Total time:19.491114616394043 #多线程
# for _ in range(2):
# t = Thread(target=one_hundred_million) #Total time:18.768073320388794
# t.start() #Total time:18.906081438064575 #多进程
# for _ in range(2):
# p = Process(target=one_hundred_million) #Total time:11.364650011062622
# p.start() #Total time:11.398651838302612
Python-多线程之消费者模式和GIL全局锁的更多相关文章
- python GIL 全局锁,多核cpu下的多线程性能究竟如何?
python GIL 全局锁,多核cpu下的多线程性能究竟如何?GIL全称Global Interpreter Lock GIL是什么? 首先需要明确的一点是GIL并不是Python的特性,它是在实现 ...
- [ Python - 11 ] 多线程及GIL全局锁
1. GIL是什么? 首先需要明确的一点是GIL并不是python的特性, 它是在实现python解析器(Cpython)时所引入的一个概念. 而Cpython是大部分环境下默认的python执行环境 ...
- java+反射+多线程+生产者消费者模式+读取xml(SAX)入数据库mysql-【费元星Q9715234】
java+反射+多线程+生产者消费者模式+读取xml(SAX)入数据库mysql-[费元星Q9715234] 说明如下,不懂的问题直接我[费元星Q9715234] 1.反射的意义在于不将xml tag ...
- 并发编程-线程-死锁现象-GIL全局锁-线程池
一堆锁 死锁现象 (重点) 死锁指的是某个资源被占用后,一直得不到释放,导致其他需要这个资源的线程进入阻塞状态. 产生死锁的情况 对同一把互斥锁加了多次 一个共享资源,要访问必须同时具备多把锁,但是这 ...
- python并发编程-多线程实现服务端并发-GIL全局解释器锁-验证python多线程是否有用-死锁-递归锁-信号量-Event事件-线程结合队列-03
目录 结合多线程实现服务端并发(不用socketserver模块) 服务端代码 客户端代码 CIL全局解释器锁****** 可能被问到的两个判断 与普通互斥锁的区别 验证python的多线程是否有用需 ...
- TCP并发、GIL全局锁、多线程讨论
TCP实现并发 #client客户端 import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while T ...
- Java实现多线程生产者消费者模式的两种方法
生产者消费者模式:生产者和消费者在同一时间段内共用同一存储空间,生产者向空间里生产数据,而消费者取走数据.生产者生产一个,消费者消费一个,不断循环. 第一种实现方法,用BlockingQueue阻塞队 ...
- java多线程 生产者消费者模式
package de.bvb; /** * 生产者消费者模式 * 通过 wait() 和 notify() 通信方法实现 * */ public class Test1 { public static ...
- java实现多线程生产者消费者模式
1.概念 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题.生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消 ...
随机推荐
- 新手如何学习Java——Java学习路线图
推荐初学者阅读:新手如何学习Java——Java学习路线图
- 过滤access日志前5条数据
cat /usr/local/nginx/logs/access.log|awk '{print $1}'|sort|uniq -c|sort -n -r|head -5 找不到的话可以find查找a ...
- 详解 Tomcat 的连接数与线程池
前言 在使用tomcat时,经常会遇到连接数.线程数之类的配置问题,要真正理解这些概念,必须先了解Tomcat的连接器(Connector). 在前面的文章 详解Tomcat配置文件server. ...
- Java中构造函数传参数在基本数据类型和引用类型之间的区别
Java中构造函数传参数在基本数据类型和引用类型的区别 如果构造函数中穿的参数为基本数据类型,如果在函数中没有返回值,在调用的时候不会发生改变:而如果是引用类型,改变的是存储的位置,所有不管有没有返回 ...
- kali域名解析错误解决
浏览器出现不能上网的的现象,推测是DNS解析有问题,想要修改DNS vim /etc/resolv.conf nameserver 202.96.134.133 nameserver 114.114. ...
- Mysql 数据库 创建与删除(基础2)
创建数据库 语法: 注意:创建数据库时可以指定编码(如: create database mydb123 default charset utf8; ) pyvip@Vip:~$ mysql -uxl ...
- SOA 是什么
SOA 英文:Service-Oriented Architecture,面向服务的架构. 是一种面向通用集成服务的.松耦合的架构实现方式,是web时代服务发展的产物: 使用"分层" ...
- E-R图学习笔记
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型.属性和联系的方法,用来描述现实世界的概念模型. 方法 编辑 E-R方法是“实体-联系方法”( ...
- jquery mobil 和页面适应
<meta name="viewport" content="width=device-width" />
- 五 shutil模块
高级的 文件.文件夹.压缩包 处理模块 shutil.copyfileobj(fsrc, fdst[, length])将文件内容拷贝到另一个文件中 1 import shutil 2 3 shuti ...