sparkContext 读取hdfs文件流程及分片机制
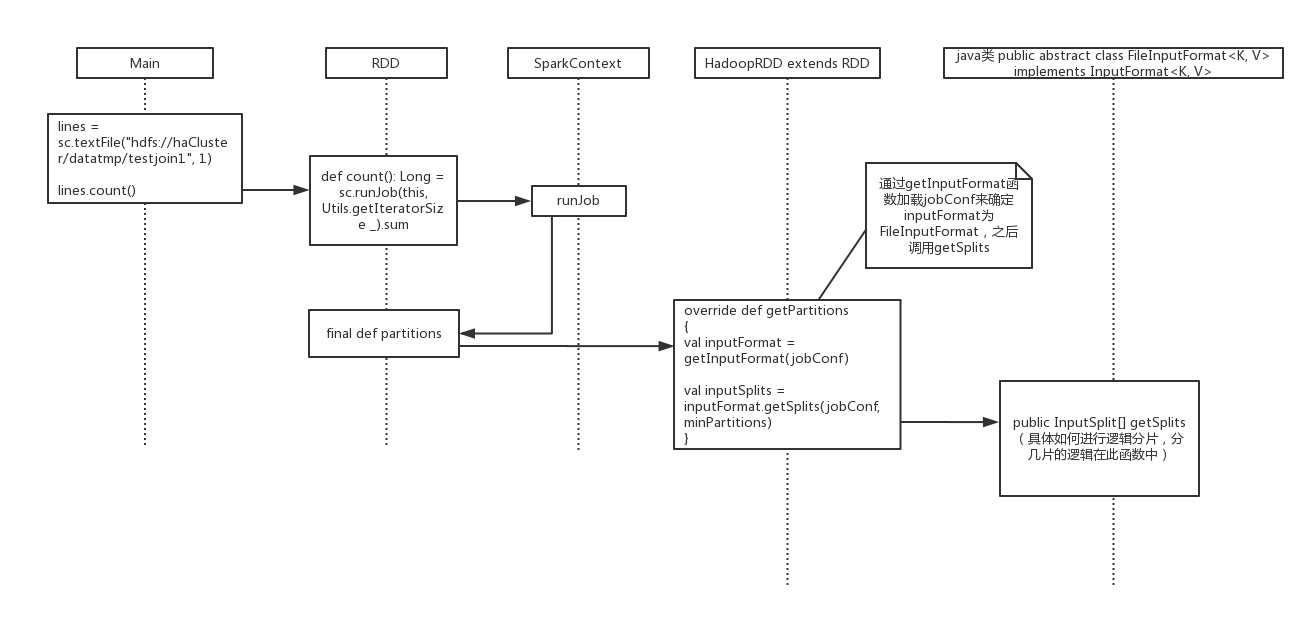
sparkContext 读取hdfs文件流程及分片机制的更多相关文章
- Spark读取HDFS文件,文件格式为GB2312,转换为UTF-8
package iie.udps.example.operator.spark; import scala.Tuple2; import org.apache.hadoop.conf.Configur ...
- Spark读取HDFS文件,任务本地化(NODE_LOCAL)
Spark也有数据本地化的概念(Data Locality),这和MapReduce的Local Task差不多,如果读取HDFS文件,Spark则会根据数据的存储位置,分配离数据存储最近的Execu ...
- 记录一次读取hdfs文件时出现的问题java.net.ConnectException: Connection refused
公司的hadoop集群是之前的同事搭建的,我(小白一个)在spark shell中读取hdfs上的文件时,执行以下指令 >>> word=sc.textFile("hdfs ...
- pig 自定义udf中读取hdfs 文件
最近几天,在研究怎么样把日志中的IP地址转化成具体省份城市. 希望写一个pig udf IP数据库采用的纯真IP数据库文件qqwry.dat,可以从http://www.cz88.net/下载. 这里 ...
- Spark设置自定义的InputFormat读取HDFS文件
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/problem_spark_reading_hdfs_serial ...
- 读取hdfs文件之后repartition 避免数据倾斜
场景一: api: textFile("hfds://....").map((key,value)).reduceByKey(...).map(实际的业务计算逻辑) 场景:hdf ...
- java Api 读取HDFS文件内容
package dao; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java ...
- 问题记录:spark读取hdfs文件出错
错误信息: scala> val file = sc.textFile("hdfs://kit-b5:9000/input/README.txt") 13/10/29 16: ...
- 读取hdfs文件内容
基础环境: cdh2.71 需要注意: url地址参照 <property> <name>dfs.namenode.servicerpc-address</name> ...
随机推荐
- SpringBoot 部署 docker 打包镜像
SpringBoot 部署 docker 打包镜像 环境: 1.代码编写工具:IDEA 2.打包:maven 3.docker 4.linux 7.JDK1.8 8.Xshell 9.Xftp 第一步 ...
- Java字符串池
1. String类的两个构造方法 private final char value[]; private int hash; public String() { this.value = " ...
- 卡特兰数 codevs 1086 栈
1086 栈 2003年NOIP全国联赛普及组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Description ...
- Ehcache缓存时间设置
timeToLiveSeconds和timeToIdleSecondstimeToLiveSeconds=x:缓存自创建日期起至失效时的间隔时间x:timeToIdleSeconds=y:缓存创建以后 ...
- 原生+H5开发之:js交互【location方式】
1. 交互方式总结 1Android与JS通过WebView互相调用方法,实际上是: Android去调用JS的代码 JS去调用Android的代码 二者沟通的桥梁是WebView 对于Android ...
- Git与SVN
http://www.nowamagic.net/academy/detail/48160207 前面提到,Linus一直痛恨CVS及SVN这些集中式的版本控制系统,为什么呢?Git是分布式版本控制系 ...
- WM-G-MR-09模块
WM-G-MR-09模块,该模块同时支持SDIO与SPI 模式 USI(环隆电气)WM-G-MR-09,该WiFi芯片支持802.11b/g无线网络模式,芯片体积8.2×8.4×1.35(mm),采用 ...
- ARM 调用约定 calling convention
int bar( int a, int b, int c, int d, int e, int f, int g ) { ]; array2[ ] = a + b; array2[ ] = b + c ...
- php中的var_dump()方法的详细说明
首先看看实例: <?PHP$a = "alsdflasdf;a";$b = var_dump($a);echo "<br>";//var_du ...
- java代码逆向工程生成uml
今天在看一个模拟器的源码,一个包里有多个类,一个类里又有多个属性和方法,如果按顺序看下来,不仅不能对整个模拟器的框架形成一个大致的认识,而且只会越看越混乱,所以,想到有没有什么工具可以将这些个类以及它 ...