Index Nested-Loop Join
(接上篇)由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ
算法最大的弊端。首先,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。例如下面的这个
SQL语句:
SELECT
COUNT(*)
FROM
part,
lineitem
WHERE
l_partkey = p_partkey
AND p_retailprice > 2050
AND l_discount > 0.04;
其中p_partkey是表part的主键,l_partkey是表lineitem的一个辅助索引,由于表part数据较小,因此作为外表(驱动表)。但是内表Join完成后还需要判断条件l_discount > 0.04,这个在聚集索引上,故需要回表进行读取。根据explain得到上述SQL的执行计划如下图所示:
Block Nested-Loop Join
算法说明
在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,因为那个算法太粗暴,不忍直视。数据量大些的复杂SQL估计几年都可能跑不出结果,如果你不信,那就是too young too simple。或者Inside君可以给你些SQL跑跑看。
Simple Nested-Loop Join算法的缺点在于其对于内表的扫描次数太多,从而导致扫描的记录太过庞大。Block Nested-Loop Join算法较Simple Nested-Loop Join的改进就在于可以减少内表的扫描次数,甚至可以和Hash Join算法一样,仅需扫描内表一次。
接着Inside君带你来看看Block Nested-Loop Join算法的伪代码:
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
Then output the tuple
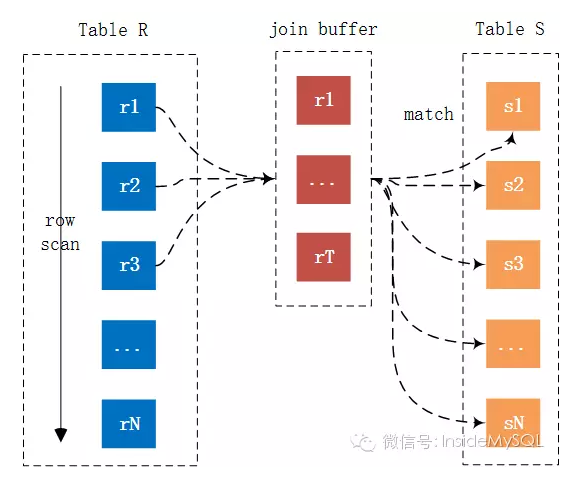
可以看到相比Simple Nested-Loop Join算法,Block Nested-LoopJoin算法仅多了一个所谓的Join Buffer,然为什么这样就能减少内表的扫描次数呢?下图相比更好地解释了Block Nested-Loop Join算法的运行过程:
可以看到Join Buffer用以缓存链接需要的列,然后以Join Buffer批量的形式和内表中的数据进行链接比较。就上图来看,记录r1,r2 … rT的链接仅需扫内表一次,如果join buffer可以缓存所有的外表列,那么链接仅需扫描内外表各一次,从而大幅提升Join的性能。
Join Buffer
变量join_buffer_size
从上一节中可以发现Join Buffer是用来减少内表扫描次数的一种优化,但Join Buffer又没那么简单,在上一节中Inside君故意忽略了一些实现。
首先变量join_buffer_size用来控制Join Buffer的大小,调大后可以避免多次的内表扫描,从而提高性能。也就是说,当MySQL的Join有使用到Block Nested-Loop Join,那么调大变量join_buffer_size才是有意义的。而前面的Index Nested-Loop Join如果仅使用索引进行Join,那么调大这个变量则毫无意义。
变量join_buffer_size的默认值是256K,显然对于稍复杂的SQL是不够用的。好在这个是会话级别的变量,可以在执行前进行扩展。Inside君建议在会话级别进行设置,而不是全局设置,因为很难给一个通用值去衡量。另外,这个内存是会话级别分配的,如果设置不好容易导致因无法分配内存而导致的宕机问题。
需要特别注意的是,变量join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
Join Buffer缓存的对象
Join Buffer缓存的对象是什么,这个问题相当关键和重要。然在MySQL的官方手册中是这样记录的:
Only columns of interest to the join are stored in the join buffer, not whole rows.
可以发现Join Buffer不是缓存外表的整行记录,但是columns of interest具体指的又是什么?Inside君的第一反应是Join的列。为此,Inside君又去查了下mysql internals,查询得到的说明如下所示:
We only store the used columns in the join buffer, not the whole rows.
used columns还是非常模糊。为此,Inside君询问了好友李海翔,也是官方MySQL优化器团队的成员,他答复我的结果是:“所有参与查询的列”都会保存到Join Buffer,而不是只有Join的列。最后,Inside君调试了MySQL,在sql_join_buffer.cc文件中验证了这个结果。
比如下面的SQL语句,假设没有索引,需要使用到Join Buffer进行链接:
SELECT a.col3 FROM a,b
WHERE a.col1 = b.col2
AND a.col2 > …. AND b.col2 = …
假设上述SQL语句的外表是a,内表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)。
通过上面的介绍,我们现在可以得到内表的扫描次数为:
Scaninner_table = (Rn * used_column_size) / join_buffer_size + 1
对于有经验的DBA就可以预估需要分配的Join Buffer大小,然后尽量使得内表的扫描次数尽可能的少,最优的情况是只扫描内表一次。
Join Buffer的分配
需要牢记的是,Join Buffer是在Join之前就进行分配,并且每次Join就需要分配一次Join Buffer,所以假设有N张表参与Join,每张表之间通过Block Nested-Loop Join,那么总共需要分配N-1个Join Buffer,这个内存容量是需要DBA进行考量的。
Join Buffer可分为以下两类:
regular join buffer
incremental join buffer
regular join buffer是指Join Buffer缓存所有参与查询的列, 如果第一次使用Join Buffer,必然使用的是regular join buffer。
incremental join buffer中的Join Buffer缓存的是当前使用的列,以及之前使用Join Buffer的指针。在多次进行Join的操作时,这样可以极大减少Join Buffer对于内存开销的需求。
此外,对于NULL类型的列,其实不需要存放在Join Buffer中,而对于VARCHAR类型的列,也是仅需最小的内存即可,而不是以CHAR类型在Join Buffer中保存。最后,从MySQL 5.6版本开始,对于Outer Join也可以使用Join Buffer。
Block Nested-Loop Join总结
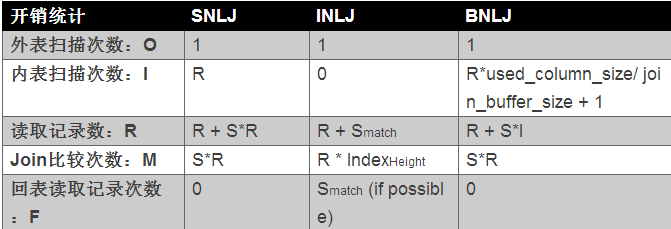
Block Nested-Loop Join极大的避免了内表的扫描次数,如果Join Buffer可以缓存外表的数据,那么内表的扫描仅需一次,这和Hash Join非常类似。但是Block Nested-Loop Join依然没有解决的是Join比较的次数,其仍然通过Join判断式进行比较。综上所述,到目前为止各Join算法的成本比较如下所示:
未完待续......
- MySQL Join算法与调优白皮书(一)
正文 Inside君发现很少有人能够完成讲明白MySQL的Join类型与算法,网上流传着的要提升Join性能,加大变量join_buffer_size的谬论更是随处可见.当然,也有一些无知的PGer攻 ...
- MySQL Join算法与调优白皮书(三)
Batched Key Access Join Index Nested-Loop Join虽好,但是通过辅助索引进行链接后需要回表,这里需要大量的随机I/O操作.若能优化随机I/O,那么就能极大的提 ...
- mysql监控、性能调优及三范式理解
原文:mysql监控.性能调优及三范式理解 1监控 工具:sp on mysql sp系列可监控各种数据库 2调优 2.1 DB层操作与调优 2.1.1.开启慢查询 在My.cnf文件中添加如 ...
- 【叶问】 MySQL常用的sql调优手段或工具有哪些
MySQL常用的sql调优手段或工具有哪些1.根据执行计划优化 通常使用desc或explain,另外可以添加format=json来输出更详细的json格式的执行计划,主要注意点如下: ...
- JVM调优(二)经验参数设置
调优设置具体解析 堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用物理内存限制.32位系统下,一般限制在1.5 ...
- MySQL性能诊断与调优 转
http://www.cnblogs.com/preftest/ http://www.highperfmysql.com/ BOOK LAMP 系统性能调优,第 3 部分: MySQL 服务 ...
- MySQL插入数据性能调优
插入数据性能调优总结: 1.SQL插入语句调优 2.如果是InnoDB引擎的话,尝试开启事务,批量提交 3.调整MySQl数据库配置 参考: 百度空间 - MySQL插入数据性能调优 CSDN ...
- MySQL性能诊断与调优
LAMP 系统性能调优,第 3 部分: MySQL 服务器调优http://www.ibm.com/developerworks/cn/linux/l-tune-lamp-3.html LoadRun ...
- JVM调优(二)——基于JVisualVM的可视化监控
JVM调优(二)--基于JVisualVM的可视化监控 工具路径://java/jdk1.8xxx/bin/JVisuaVM.exe 监控本地的Tomcat 监控远程Tomcat 监控普通的JAVA进 ...
随机推荐
- DB2导入导出数据
1.导出表数据到txt文件: export to /brcb_edp/data_public_edp/file/CCDM/file/FILE_CCDM_DR_CARD_CUST_DET.txt of ...
- NAT&Port Forwarding&Port Triggering
NAT Nat,网络地址转换协议.主要功能是实现局域网内的本地主机与外网通信. 在连接外网时,内部Ip地址需要转换为网关(一般为路由器Ip地址)(端口号也需要相应的转换) 如: ...
- c# 自定义排序类(冒泡、选择、插入、希尔、快速、归并、堆排序等)
using System; using System.Text; namespace HuaTong.General.Utility { /// <summary> /// 自定义排序类 ...
- html 实体和htmlspecialchars()
HTML 中的预留字符必须被替换为字符实体. HTML 实体 在 HTML 中,某些字符是预留的. 在 HTML 中不能使用小于号(<)和大于号(>),这是因为浏览器会误认为它们是标签. ...
- Spring核心概念(二)
IOC/DI IOC(控制反转):对象(组件)的创建由代码中转移到外部容器(XML,注解) . DI(依赖注入):当类A需要使用类B时,那么我们需要为类A的属性赋值类B的对象. 这种现象我们称为依赖注 ...
- 学习三部曲:WHAT、HOW、WHY
一个人学习的过程要经历以下三步,才可以说得上"学会"两字: 第一步:WHAT 所谓的"WHAT",就是搞清楚某个东东是什么?有什么用?有什么语法?有什么功能特性 ...
- phpstorm、webstorm配置less编译器
1. node.js 安装包 https://nodejs.org/en/download/ 1) 安装js解析器node.js.直接下一步就ok了. 2) 将npm压缩包解压,找到里面的les ...
- 解决visual studio2017没有系统类和方法注释的问题
好几次碰到这种情况了,每次都得稍微查一查才能解决这个问题,相信也有不少人遇到这个问题,在对方法还不是很熟练的时候,将鼠标放置到方法上去,就会有信息提示是一件非常方便的事情,本文的解决方法同样适用于只显 ...
- LOJ2362. 「NOIP2016」蚯蚓【单调队列】
LINK 思路 良心来说这题还挺思维的 我没看题解也不知道要这样维护 把每次斩断的点分别放进两个队列里面 因为要维护增长,所以可以让新进队的节点来一个负增长? 是不是就好了? 然后很容易发现因为在原始 ...
- HDU2222 Keywords Search 【AC自动机】
HDU2222 Keywords Search Problem Description In the modern time, Search engine came into the life of ...