线性判别分析(Linear Discriminant Analysis)
1. 问题
之前我们讨论的PCA、ICA也好,对样本数据来言,可以是没有类别标签y的。回想我们做回归时,如果特征太多,那么会产生不相关特征引入、过度拟合等问题。我们可以使用PCA来降维,但PCA没有将类别标签考虑进去,属于无监督的。
比如回到上次提出的文档中含有“learn”和“study”的问题,使用PCA后,也许可以将这两个特征合并为一个,降了维度。但假设我们的类别标签y是判断这篇文章的topic是不是有关学习方面的。那么这两个特征对y几乎没什么影响,完全可以去除。
再举一个例子,假设我们对一张100*100像素的图片做人脸识别,每个像素是一个特征,那么会有10000个特征,而对应的类别标签y仅仅是0/1值,1代表是人脸。这么多特征不仅训练复杂,而且不必要特征对结果会带来不可预知的影响,但我们想得到降维后的一些最佳特征(与y关系最密切的),怎么办呢?
2. 线性判别分析(二类情况)
回顾我们之前的logistic回归方法,给定m个n维特征的训练样例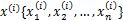 (i从1到m),每个
(i从1到m),每个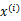 对应一个类标签
对应一个类标签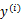 。我们就是要学习出参数
。我们就是要学习出参数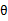 ,使得
,使得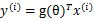 (g是sigmoid函数)。
(g是sigmoid函数)。
现在只考虑二值分类情况,也就是y=1或者y=0。
为了方便表示,我们先换符号重新定义问题,给定特征为d维的N个样例,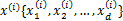 ,其中有
,其中有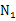 个样例属于类别
个样例属于类别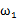 ,另外
,另外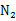 个样例属于类别
个样例属于类别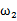 。
。
现在我们觉得原始特征数太多,想将d维特征降到只有一维,而又要保证类别能够“清晰”地反映在低维数据上,也就是这一维就能决定每个样例的类别。
我们将这个最佳的向量称为w(d维),那么样例x(d维)到w上的投影可以用下式来计算
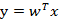
这里得到的y值不是0/1值,而是x投影到直线上的点到原点的距离。
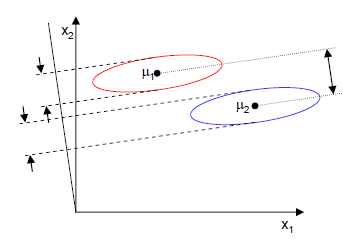
当x是二维的,我们就是要找一条直线(方向为w)来做投影,然后寻找最能使样本点分离的直线。如下图:
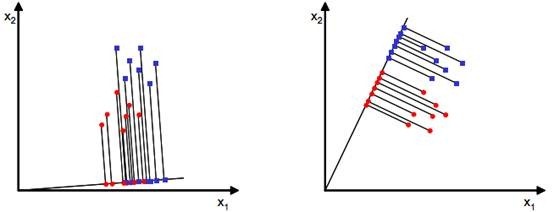
从直观上来看,右图比较好,可以很好地将不同类别的样本点分离。
接下来我们从定量的角度来找到这个最佳的w。
首先我们寻找每类样例的均值(中心点),这里i只有两个
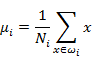
由于x到w投影后的样本点均值为
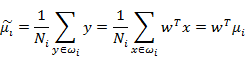
由此可知,投影后的的均值也就是样本中心点的投影。
什么是最佳的直线(w)呢?我们首先发现,能够使投影后的两类样本中心点尽量分离的直线是好的直线,定量表示就是:
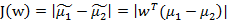
J(w)越大越好。
但是只考虑J(w)行不行呢?不行,看下图
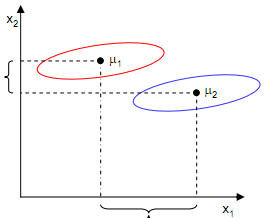
样本点均匀分布在椭圆里,投影到横轴x1上时能够获得更大的中心点间距J(w),但是由于有重叠,x1不能分离样本点。投影到纵轴x2上,虽然J(w)较小,但是能够分离样本点。因此我们还需要考虑样本点之间的方差,方差越大,样本点越难以分离。
我们使用另外一个度量值,称作散列值(scatter),对投影后的类求散列值,如下
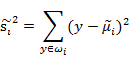
从公式中可以看出,只是少除以样本数量的方差值,散列值的几何意义是样本点的密集程度,值越大,越分散,反之,越集中。
而我们想要的投影后的样本点的样子是:不同类别的样本点越分开越好,同类的越聚集越好,也就是均值差越大越好,散列值越小越好。正好,我们可以使用J(w)和S来度量,最终的度量公式是
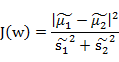
接下来的事就比较明显了,我们只需寻找使J(w)最大的w即可。
先把散列值公式展开
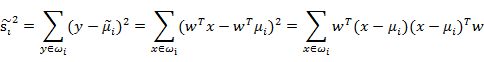
我们定义上式中中间那部分
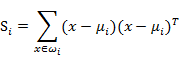
这个公式的样子不就是少除以样例数的协方差矩阵么,称为散列矩阵(scatter matrices)
我们继续定义
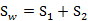
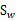 称为Within-class scatter matrix。
称为Within-class scatter matrix。
那么回到上面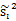 的公式,使用
的公式,使用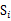 替换中间部分,得
替换中间部分,得
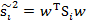
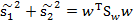
然后,我们展开分子
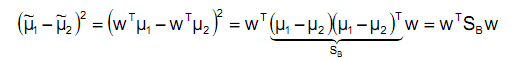
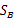 称为Between-class scatter,是两个向量的外积,虽然是个矩阵,但秩为1。
称为Between-class scatter,是两个向量的外积,虽然是个矩阵,但秩为1。
那么J(w)最终可以表示为
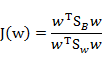
在我们求导之前,需要对分母进行归一化,因为不做归一的话,w扩大任何倍,都成立,我们就无法确定w。因此我们打算令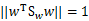 ,那么加入拉格朗日乘子后,求导
,那么加入拉格朗日乘子后,求导
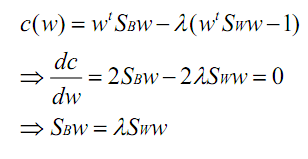
其中用到了矩阵微积分,求导时可以简单地把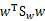 当做
当做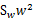 看待。
看待。
如果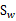 可逆,那么将求导后的结果两边都乘以
可逆,那么将求导后的结果两边都乘以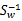 ,得
,得
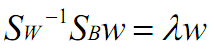
这个可喜的结果就是w就是矩阵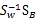 的特征向量了。
的特征向量了。
这个公式称为Fisher linear discrimination。
等等,让我们再观察一下,发现前面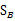 的公式
的公式
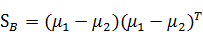
那么
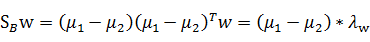
代入最后的特征值公式得
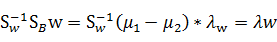
由于对w扩大缩小任何倍不影响结果,因此可以约去两边的未知常数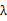 和
和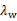 ,得到
,得到
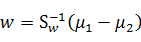
至此,我们只需要求出原始样本的均值和方差就可以求出最佳的方向w,这就是Fisher于1936年提出的线性判别分析。
看上面二维样本的投影结果图:
3. 线性判别分析(多类情况)
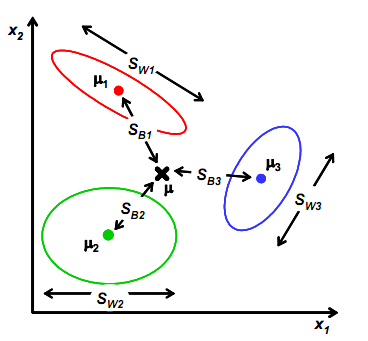
前面是针对只有两个类的情况,假设类别变成多个了,那么要怎么改变,才能保证投影后类别能够分离呢?
我们之前讨论的是如何将d维降到一维,现在类别多了,一维可能已经不能满足要求。假设我们有C个类别,需要K维向量(或者叫做基向量)来做投影。
将这K维向量表示为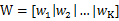 。
。
我们将样本点在这K维向量投影后结果表示为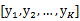 ,有以下公式成立
,有以下公式成立
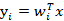
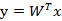
为了像上节一样度量J(w),我们打算仍然从类间散列度和类内散列度来考虑。
当样本是二维时,我们从几何意义上考虑:
其中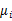 和
和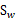 与上节的意义一样,
与上节的意义一样,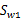 是类别1里的样本点相对于该类中心点
是类别1里的样本点相对于该类中心点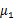 的散列程度。
的散列程度。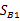 变成类别1中心点相对于样本中心点
变成类别1中心点相对于样本中心点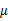 的协方差矩阵,即类1相对于
的协方差矩阵,即类1相对于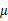 的散列程度。
的散列程度。
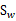 为
为
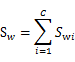
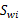 的计算公式不变,仍然类似于类内部样本点的协方差矩阵
的计算公式不变,仍然类似于类内部样本点的协方差矩阵
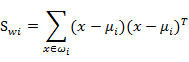
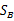 需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将
需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将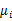 看作样本点,
看作样本点,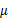 是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。
是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。
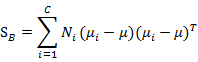
其中
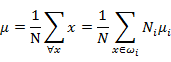
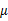 是所有样本的均值。
是所有样本的均值。
上面讨论的都是在投影前的公式变化,但真正的J(w)的分子分母都是在投影后计算的。下面我们看样本点投影后的公式改变:
这两个是第i类样本点在某基向量上投影后的均值计算公式。
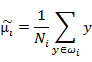
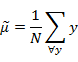
下面两个是在某基向量上投影后的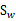 和
和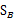
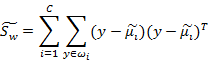
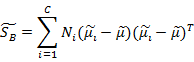
其实就是将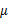 换成了
换成了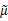 。
。
综合各个投影向量(w)上的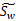 和
和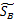 ,更新这两个参数,得到
,更新这两个参数,得到
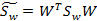
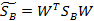
W是基向量矩阵,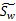 是投影后的各个类内部的散列矩阵之和,
是投影后的各个类内部的散列矩阵之和,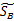 是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
回想我们上节的公式J(w),分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。
然而,最后的J(w)的形式是
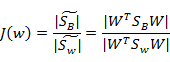
由于我们得到的分子分母都是散列矩阵,要将矩阵变成实数,需要取行列式。又因为行列式的值实际上是矩阵特征值的积,一个特征值可以表示在该特征向量上的发散程度。因此我们使用行列式来计算(此处我感觉有点牵强,道理不是那么有说服力)。
整个问题又回归为求J(w)的最大值了,我们固定分母为1,然后求导,得出最后结果(我翻查了很多讲义和文章,没有找到求导的过程)
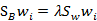
与上节得出的结论一样
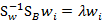
最后还归结到了求矩阵的特征值上来了。首先求出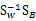 的特征值,然后取前K个特征向量组成W矩阵即可。
的特征值,然后取前K个特征向量组成W矩阵即可。
注意:由于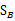 中的
中的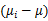 秩为1,因此
秩为1,因此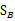 的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个
的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个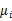 后,最后一个
后,最后一个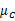 可以有前面的
可以有前面的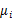 来线性表示,因此
来线性表示,因此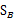 的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
由于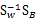 不一定是对称阵,因此得到的K个特征向量不一定正交,这也是与PCA不同的地方。
不一定是对称阵,因此得到的K个特征向量不一定正交,这也是与PCA不同的地方。
转自:http://www.cnblogs.com/jerrylead/archive/2011/04/21/2024384.html
线性判别分析(Linear Discriminant Analysis)的更多相关文章
- 线性判别分析(Linear Discriminant Analysis, LDA)算法分析
原文来自:http://blog.csdn.net/xiazhaoqiang/article/details/6585537 LDA算法入门 一. LDA算法概述: 线性判别式分析(Lin ...
- 线性判别分析(Linear Discriminant Analysis, LDA)算法初识
LDA算法入门 一. LDA算法概述: 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discrimin ...
- Linear Discriminant Analysis Algorithm
线性判别分析算法. 逻辑回归是一种分类算法,传统上仅限于两类分类问题. 如果有两个以上的类,那么线性判别分析算法是首选的线性分类技术.LDA的表示非常直接.它包括数据的统计属性,为每个类计算.对于单个 ...
- 机器学习: Linear Discriminant Analysis 线性判别分析
Linear discriminant analysis (LDA) 线性判别分析也是机器学习中常用的一种降维算法,与 PCA 相比, LDA 是属于supervised 的一种降维算法.PCA考虑的 ...
- 线性判别分析(Linear Discriminant Analysis,LDA)
一.LDA的基本思想 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD) ...
- Max-Mahalanobis Linear Discriminant Analysis Networks
目录 概 主要内容 Pang T, Du C, Zhu J, et al. Max-Mahalanobis Linear Discriminant Analysis Networks[C]. inte ...
- 线性判别分析(Linear Discriminant Analysis)转载
1. 问题 之前我们讨论的PCA.ICA也好,对样本数据来言,可以是没有类别标签y的.回想我们做回归时,如果特征太多,那么会产生不相关特征引入.过度拟合等问题.我们可以使用PCA来降维,但PCA没有将 ...
- 高斯判别分析 Gaussian Discriminant Analysis
如果在我们的分类问题中,输入特征xx是连续型随机变量,高斯判别模型(Gaussian Discriminant Analysis,GDA)就可以派上用场了. 以二分类问题为例进行说明,模型建立如下: ...
- [ML] Linear Discriminant Analysis
虽然名字里有discriminat这个字,但却是生成模型,有点意思. 判别式 pk 生成式 阅读:生成方法 vs 判别方法 + 生成模型 vs 判别模型 举例: 判别式模型举例:要确定一个羊是山羊还是 ...
随机推荐
- 【TCP_协议_socket接口】-jmeter
1.ip 2.端口号 3.传入参数 4.告诉软件返回 最后以为是什么,不然就会报错 或者无限制的等待 查ascll 码表 启动接口的方法
- 设计模式C++实现(1)——策略(Strategy)模式
目录 策略模式 应用案例 实现的关键 Talk is cheap,let's See The Code 设计思想 参考 策略模式 策略模式定义了一系列算法和行为(也就是策略),他们可以在运行时相互替换 ...
- 高可用Kubernetes集群-3. etcd高可用集群
五.部署高可用etcd集群 etcd是key-value存储(同zookeeper),在整个kubernetes集群中处于中心数据库地位,以集群的方式部署,可有效避免单点故障. 这里采用静态配置的方式 ...
- 【python 3.6】xlwt和xlrd对excel的读写操作
#python 3.6 #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'BH8ANK' import xlrd '''====== ...
- less 语法特性翻译稿 - 特性快速预览部分
原文地址 http://lesscss.cn/features/ 概述 作为CSS的一种扩展语法,Less不仅仅向后兼容CSS,新的特性也是基于CSS现有语法.这使得学习Less变得容易,如果你有所怀 ...
- kafka浅谈
关键词 producer 生产者 broker 缓存代理 consumer 消费者 partition 分区 topic 主题 ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Spark SQL、DataFrame和Dataset——转载
转载自: Spark SQL.DataFrame和Datase
- “Hello World!”团队第五周第五次会议
博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.todo list 六.会议照片 七.燃尽图 八.checkout&push代码 一.会议时间 2017年11月14日 ...
- Thunder团队第七周 - Scrum会议1
Scrum会议1 小组名称:Thunder 项目名称:i阅app Scrum Master:杨梓瑞 工作照片: 参会成员: 王航:http://www.cnblogs.com/wangh013/ 李传 ...