二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍
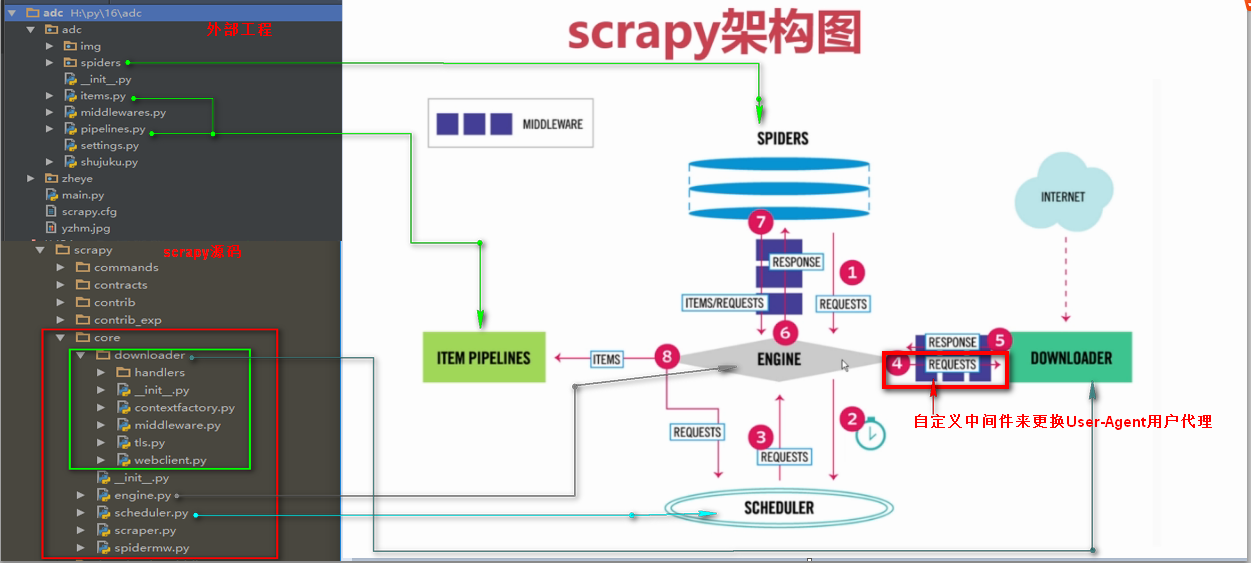
中间件是一个框架,可以连接到请求/响应处理中。这是一种很轻的、低层次的系统,可以改变Scrapy的请求和回应。也就是在Requests请求和Response响应之间的中间件,可以全局的修改Requests请求和Response响应
UserAgentMiddleware()方法,默认中间件
源码里downloadmiddleware里的useragent.py下的UserAgentMiddleware()方法,默认中间件
我们可以从源码看到当Requests请求时默认的User-Agent是Scrapy,这个很容易被网站识别而拦截爬虫

我们可以修改默认中间件UserAgentMiddleware()来随机更换Requests请求头信息的User-Agent浏览器用户代理
第一步、在settings.py配置文件,开启中间件注册DOWNLOADER_MIDDLEWARES={ }
将默认的将默认的UserAgentMiddleware设置为None,或者设置成最大就最后执行,这样我们自定义的中间件修改默认的user_agent就会先执行
settings.py配置文件

# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
第二步、安装浏览器用户代理模块fake-useragent 0.1.7
fake-useragent 是一个专门用于爬虫伪装浏览器User-Agent请求头的模块。此模块在线维护了各个浏览器的各种版本库,提供我们使用
在线各种浏览器信息:http://fake-useragent.herokuapp.com/browsers/0.1.7 0.1.7版本,fake-useragent会随机到这里调用浏览器代理
首先安装这个模块
pip install fake-useragent
使用说明:
#!/usr/bin/env python
# -*- coding:utf8 -*- from fake_useragent import UserAgent #导入浏览器代理模块
ua = UserAgent() #实例化浏览器代理类 ua.ie #随机获取IE类型的代理
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie #随机获取msie类型的代理,下面的相同
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua['Internet Explorer']
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua.opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua.chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25 # and the best one, random via real world browser usage statistic
ua.random #随机获取各种浏览器类型的代理,
更多使用 https://pypi.python.org/pypi/fake-useragent/0.1.7
第三步、自定义中间件来全局随机更换Requests请求头信息的User-Agent浏览器用户代理
在middlewares.py文件里,自定义中间件
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from fake_useragent import UserAgent #导入浏览器用户代理模块 class RequestsUserAgentmiddware(object): #自定义浏览器代理中间件
#随机更换Requests请求头信息的User-Agent浏览器用户代理
def __init__(self,crawler):
super(RequestsUserAgentmiddware, self).__init__() #获取上一级父类基类的,__init__方法里的对象封装值
self.ua = UserAgent() #实例化浏览器用户代理模块类
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') #获取settings.py配置文件里的RANDOM_UA_TYPE配置的浏览器类型,如果没有,默认random,随机获取各种浏览器类型 @classmethod #函数上面用上装饰符@classmethod,函数里有一个必写形式参数cls用来接收当前类名称
def from_crawler(cls, crawler): #重载from_crawler方法
return cls(crawler) #将crawler爬虫返回给类 def process_request(self, request, spider): #重载process_request方法
def get_ua(): #自定义函数,返回浏览器代理对象里指定类型的浏览器信息
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua()) #将浏览器代理信息添加到Requests请求
第四步、将我们自定义的中间件注册到settings.py配置文件,的DOWNLOADER_MIDDLEWARES里
注意一点要把默认的UserAgentMiddleware中间件设置为None,使其我们自定义的中间件生效
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'adc.middlewares.RequestsUserAgentmiddware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
我们可以打断点调试一下,看看是否生效
原理说明图
二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理的更多相关文章
- 第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware随机更换user-agent浏览器用户代理 downloadmiddleware介绍中间件是 ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 二十七 Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
设置代理ip只需要,自定义一个中间件,重写process_request方法, request.meta['proxy'] = "http://185.82.203.146:1080&quo ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求 Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的 Requests()方法提交一个请求 参数: ur ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
随机推荐
- APP移动端自动化测试工具选型“兵器谱”一览(主流开源工具)
(下面大多数工具都是开源工具,在github,码云等开源平台都能找到) "测试那点事儿”在看到360旗下的测试团队整理的关于目前APP移动端自动化相关的工具,觉得总结的很到位,对目前大多数中 ...
- matlab 保存图片的几种方式
最近在写毕业论文, 需要保存一些高分辨率的图片. 下面介绍几种MATLAB保存图片的 方式. 一. 直接使用MATLAB的保存按键来保存成各种格式的图片 你可以选择保存成各种格式的图片, 实际上对于 ...
- contentSize、contentInset和contentOffset 是 scrollView三个基本的属性区别和使用
contentSize.contentInset和contentOffset 是 scrollView三个基本的属性. contentSize: 其实就是scrollview可以滚动的区域,比如fra ...
- idea构建一个简单的maven_web项目
软件说明 好啦,开始创建mave的web项目啦!
- Java GC随笔
最近发生了一些C#程序运行时的一些问题,发现是GC导致的问题,然后稍微研究了一下GC,因为知道Java的GC要比.NET稍微复杂一点,所以我觉得要是能弄懂Java的GC的原理,对.NET的GC的理解也 ...
- C++切割字符串
std::string text = "2001_1;2005_5;"; std::stringstream ss(text); std::string sub_str; std: ...
- List泛型集合转DataTable
自存,此方法可以防止出现DataSet不支持System.Nullable的错误 public static DataTable ToDataTable<T>(IEnumerable< ...
- spark[源码]-DAG调度器源码分析[二]
前言 根据图片上的结构划分我们不难发现当rdd触发action操作之后,会调用SparkContext的runJob方法,最后调用的DAGScheduler.handleJobSubmitted方法完 ...
- FS-LDM 十大主题
英文名称 中文名称 概念定义 Party 当事人 指银行所服务的任意对象和感兴趣进行分析的各种对象.如个人或公司客户.潜在客户.代理机构.雇员.分行.部门等. Internal Org 内部组织 可能 ...
- 基于session和token的身份认证方案
一.基于session的身份认证方案 1.方案图示 2.比较通用的鉴权流程实现如下: 在整个流程中有两个拦截器. 第一个拦截器AuthInteceptor是为了每一次的请求的时候都先去session中 ...