二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求
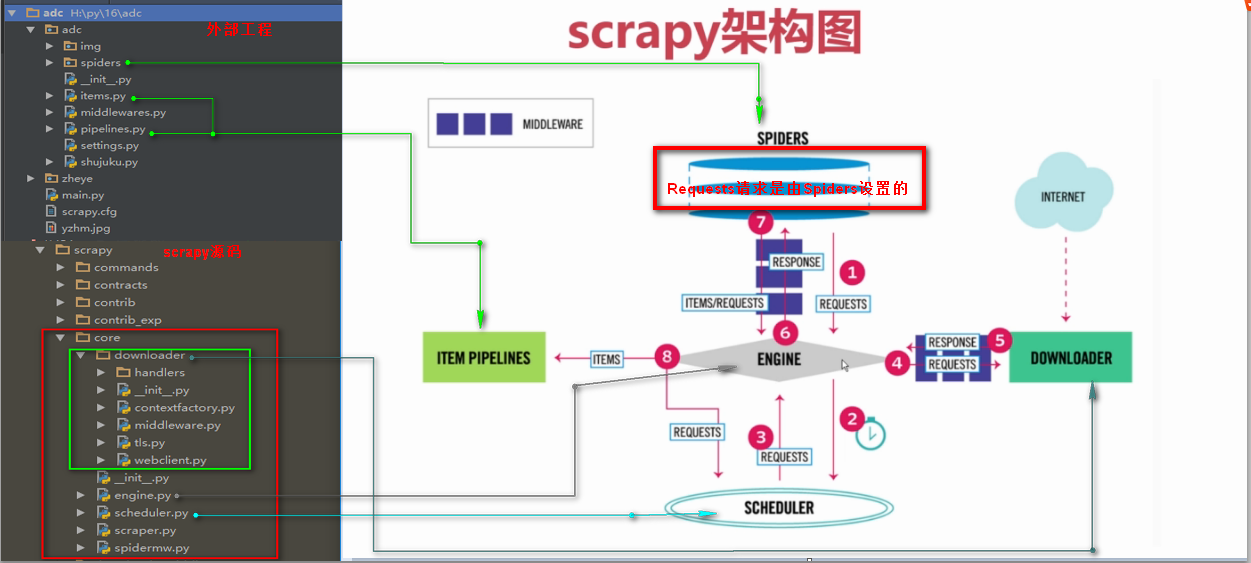
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
Response响应
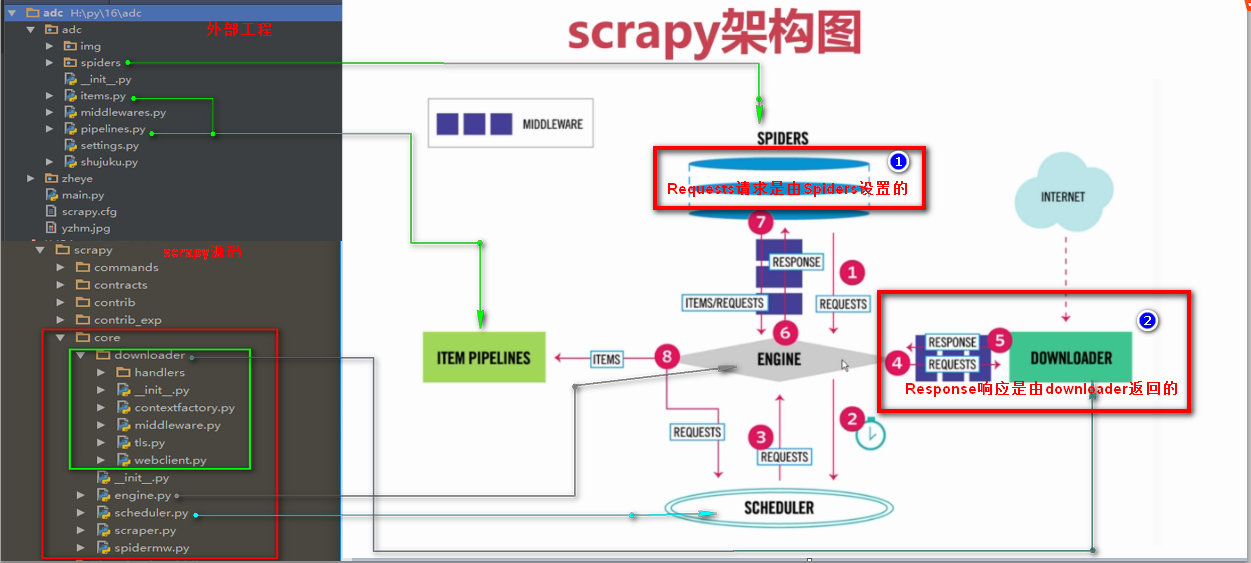
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
print(response.headers)
print(response.status)
# print(response.body)
print(response.url)
二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍的更多相关文章
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- 四十五 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
bool查询说明 filter:[],字段的过滤,不参与打分must:[],如果有多个查询,都必须满足[并且]should:[],如果有多个查询,满足一个或者多个都匹配[或者]must_not:[], ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- opencv:vs2015添加了包含目录依然无法打开‘opencv2/core/core.hpp’ 解决方法
安装环境 win10 vs2015 出错和改错 按网上的教程,配置好opencv后,包括已经把以下内容添加到'包含目录'了: E:\openCV\opencv\build\include E:\ope ...
- 07 nginx反向代理和nfs服务
作业一:nginx服务二进制安装nginx包 作为web服务修改配置文件 让配置生效,验证配置 作业二:nfs服务二进制安装nfs作为共享存储挂载在三台web的网站根目录下实现,在任意一台web上修改 ...
- xampp mac 版安装
欢迎光临 XAMPP 的 Mac OS X 版 适用于 Mac OS X 的 XAMPP 是 Mac OS X 上最简单,最实用,也最完整的网络服务器解决方案.该发行版包括整合了最新的 MySQL.P ...
- JMeter5.0 边界提取器使用
需求: 需要提取下图中requestNo的值,使用JMeter3.1和4.0版本,使用正则表达式提取器始终无法获取 而后使用JMeter5.0的边界提取器,不需要写复杂的正则表达式,只要填写左右边界即 ...
- c++之旅:操作符重载
操作符重载 操作符重载可以为操作符添加更多的含义,操作符重载的作用的对象是类 那些操作符可以重载 除了下面几个操作符不能重载外,其它的操作符都能重载 . :: .* ?: sizeof 操作符重载的本 ...
- python error: curl: (1) Protocol "'https" not supported or disabled in libcurl
python 调用curl访问一个网页时,出现error: curl: (1) Protocol "'https" not supported or disabled in lib ...
- 20145302张薇《Java程序设计》实验一报告
20145302 <Java程序设计>实验一:Java开发环境的熟悉 实验内容 使用dos命令行编译.运行简单的Java程序: 使用IDEA编辑.编译.运行.调试Java程序. 1.命令行 ...
- linux目录结构及文件权限
安装banner用到的指令: 第一步: sudo apt-get update 第二步: sudo apt-get install sysvbanner 成功了 创建新用户指令: sudo addus ...
- 20145231熊梓宏 《网络对抗》 实验8 Web基础
20145231熊梓宏 <网络对抗> 实验8 Web基础 基础问题回答 ●什么是表单? 表单是一个包含表单元素的区域,表单元素是允许用户在表单中输入信息的元素,表单在网页中主要负责数据采集 ...
- sublime text3 授权码
适用于 Sublime Text 3 Build3126 64位 官方版 -– BEGIN LICENSE -– Michael Barnes Single User License EA7E-821 ...